









文章目录
1. 机器学习machine learning
机器学习,是从有限的数据集中学习到一定的规律,再把学到的规律应用到一些相似的样本集中做预测。机器学习的历史可以追溯到20世纪40年代 McCulloch提出的人工神经元网络,目前学界大致把机器学习分为传统机器学习和机器学习两个类别。其中传统机器学习更多地关注于特征提取(提取数据集中有效地特征)和特性转化(对提取的特征进行一定的加工)问题,也就是更多的需要在某一领域的专家进行人为干预,这时很多传统机器学习问题变成了特征工程(feature engineering)。
传统机器学习的流程:
- 数据预处理(data proprecessing): 主要是去除数据集噪声
- 特征提取(feature extraction):主要是提取去噪后数据集中的有效特征,根据问题不同采取的措施不同,比如使用图像问题中,一般采用SIFT(scale invariant feature transform)方法提取边缘不变,尺寸相同的特征;而在一些问题中,可能直接挑选出对研究问题影响最大的变量作为备选特征
- 特征转化(feature transform):主要是对提取的有效特征进行某种形式的进一步整合和筛选,,最终确定对研究问题影响最大的一些特征,比如 PCA(principal component analysis)方法, RF(random forest)方法等
- 预测(predication):利用最终确定的特征对这些特征对应的新样本值进行预测,得到研究问题的预测结果
但如果我们没有专业的知识,如何提升预测结果的准确性? 这就导致了表示学习(Representation Learning)的出现
2. 表示学习Representation Learning
要理解表示学习,就得先明确一个概念,语义鸿沟(semantic gap): 指的是输入数据与最终输出数据语义信息的不一致性。
举个栗子,输入许多段不同人的"愉悦"的语音,因为每个人说话方式的不同,导致每段语音表达"愉悦"的方式不同,因此如果仅让模型学习其中一段或者几段语音表达"愉悦"的方式,模型很可能不知道那些没有学习过的语音表达"愉悦"的方式,这导致如果再给他一段新的语音(新输入数据),那么模型无法做出准确的"愉悦"预测(输出数据),即模型的泛化能力可能不会很理想。
这就是表示学习和深度学习出现的主要原因。
表示学习:可以自动地学习出有效特征,并最终提升机器学习模型性能的方法。
表示学习为了解决语义鸿沟把输入数据特征做了"表示处理",为的是模型学到更具代表性的特征,一共有两种方式:分别为 局部表示(常见为one-hot形式) 和 分布式表示。局部表示转化为分布式表示的过程称为嵌入(embedding)
局部表示和分布式表示都是以向量形式出现,但分布式表示性能更好,维度低,数据处理高效
表示学习的另一个关键就是构建具有一定深度的多层次特征表示, 而这推动了深度学习的出现
3. 深度学习Deep Learning
深度学习是机器学习的一个子问题, 主要目的是从输入数据中自动学习到有效的特征表示, 是不是跟表示学习很像?
深度学习的本质就是表示学习,同时深度学习通过在输入数据和输入数据中加入了中层特征,就是把输入数据的特征经过很多次非线性转化,进一步解决了语义鸿沟问题。
深度学习主要采用神经网络模型结构,网络模型中的参数主要通过反向传播算法自动调节,达到自动学习有效特征,提升模型预测能力的效果
A 机器学习VS表征学习
参考1-表示学习(representation learning) & 特征学习
参考2-表示学习
- 特征工程:依靠专家提取显示特征,工程量巨大,特征选取的好坏将直接决定数据表示的质量,从而影响后续任务的性能。
- 表征学习:采用模型自动学习数据的隐式特征,数据表示与后续任务往往是联合训练,不依赖专家经验,但需要较大的训练数据集。
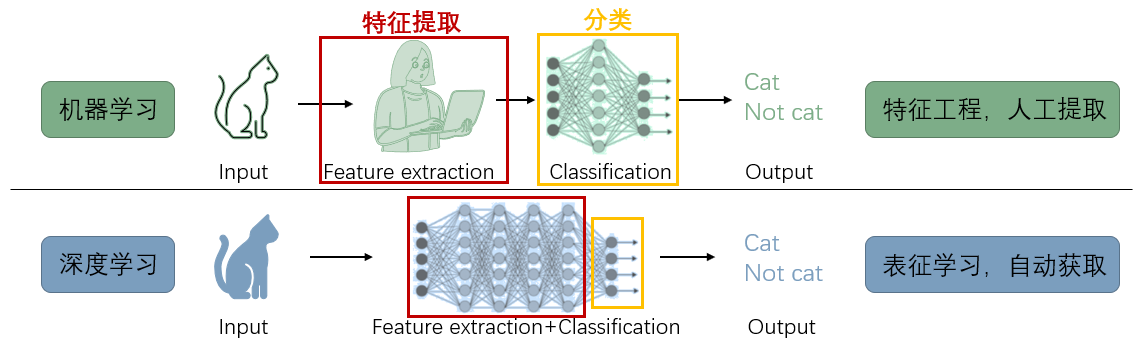
B 机器学习VS深度学习
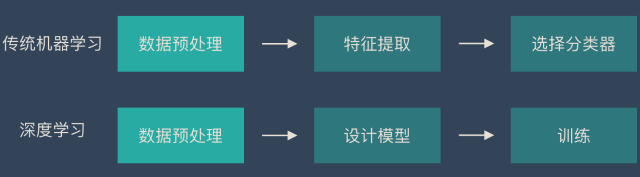
总结
机器学习本质就是利用机器自动(有部分人为参与的)学习数据特征,从而对于类似输入(相同特征)进行特定任务的预测。如果有人为参与地进行特征处理,我们称之为特征工程;
我们可以利用表示学习和深度学习方法使机器学习模型达到模型自己学习特征规律,从而自主提升模型性能的效果。















 752
752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









