







在科学研究中免不了和数据打交道,收集到原始数据后我们经常需要对其进行清洗、转换才能得到我们需要的数据。今天我总结了一下自己常用的一些多条件的数据转换方法,在临床中遇到问题能多一种选择。

继续使用我们的乳腺癌数据(公众号回复:乳腺癌,可以获得数据)。我们先导入数据和R包。
library(survival)
bc <- read.spss("E:/r/test/Breast cancer survival agec.sav",
use.value.labels=F, to.data.frame=T)


这是个乳腺癌患者的生存数据,age表示年龄,pathsize表示病理肿瘤大小(厘米),lnpos表示腋窝淋巴结阳性,histgrad表示病理组织学等级,er表示雌激素受体状态,pr表示孕激素受体状态,status结局事件是否死亡,pathscat表示病理肿瘤大小类别(分组变量),ln_yesno表示是否有淋巴结肿大,time是生存时间,后面的agec是我们自己设定的,不用管它。
有部分变量为分类变量,我们先把它转换成因子,并且删除缺失值
bc$histgrad<-as.factor(bc$histgrad)
bc$er<-as.factor(bc$er)
bc$pr<-as.factor(bc$pr)
bc$ln_yesno<-as.factor(bc$ln_yesno)
names(bc)
bc <- na.omit(bc)
假设我们想把年龄这个指标分成4个等分,然后比较不同年龄组的组间趋势P for trend,就是年龄分组对死亡率的影响。按照上一篇文章《手把手教你R语言计算校正混杂因素后的P for trend》的方法之一,要算出每组年龄段患者的中位数值。
我们先按年龄通过百分比0-25%,25%-50%,50%-70%,70%-100%这个比较把年龄分为4个区间
age3<-quantile(bc$age,c(0,.25,.50,.75,1))
age2<-cut(bc$age,breaks=c(age3),include.lowest=T,
labels = c(0,1,2,3))#把age划分为4个等分到区间
bc$age2<-age2

我们已经生成了年龄分段组(上图age2),我们接下来进行今天的主要内容:分别计算出每个分段的age2的中位数值,啥意思的呢?就是age2等于0的这一组age(年龄)的中位数,然后age2等于1的这一组age(年龄)的中位数,如此类推。这就涉及到了变量的按条件转换。
1.subset函数
这个函数用得很广泛,也很简单
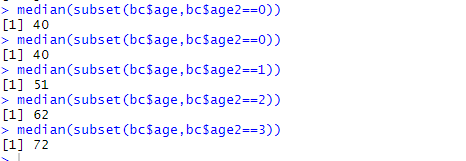
subset(bc$age,bc$age2==0)

这样就求出了age2等于0的这一组age(年龄)的数值,再用median函数求出中位数
median(subset(bc$age,bc$age2==0))

同理可以求出其他组的中位数值
median(subset(bc$age,bc$age2==0))
median(subset(bc$age,bc$age2==1))
median(subset(bc$age,bc$age2==2))
median(subset(bc$age,bc$age2==3))
2. which函数
which函数可以在一个向量中,按条件取出特定的数值,就本数据来说,先取出age2等于0的数据
which(bc$age2==0)

生成age中,age2==0的这部分数据
bc[,"age"][which(bc[,"age2"]==0)]

生成中位数
median(bc[,"age"][which(bc[,"age2"]==0)])
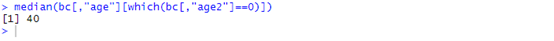
3. with函数与by函数结合
with函数与attach函数类似,by函数取其中的age,按age2分类来进行中位数计算,非常简单,一行代码搞定
newcode<-with(bc,by(age,age2,median))

4. tapply函数
Tapply函数需要提供3个数据,要计算的向量,分类变量和计算的函数,也是一行代码搞定,非常方便
attach(bc)
tapply(age,age2, median)

5. dplyr包的分组摘要函数(group_by和summarize函数)
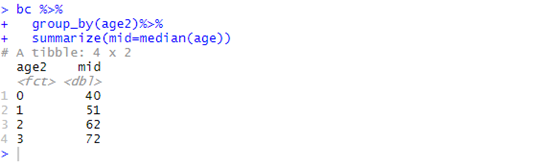
library(dplyr)
by_age<-group_by(bc,age2)
summarize(by_age,mid=median(age))

走通道也是可以的
bc %>%
group_by(age2)%>%
summarize(mid=median(age))
6. select函数
Select函数和subset函数有点类似,都是选出子集
select(filter(bc,age2 == 0),age)$age

median(select(filter(bc,age2 == 0),age)$age)

7.自己写个funtion
可以加深对函数的理解
datamedian<-function(data,x,group){
attach(data)
m<-levels(group)
n<-length(m)
newcode<-median(subset(x,group==m[1]))
if (n>2){
for (i in 2:n){
newcode1<-median(subset(x,group==levels(group)[i]))
newcode<-append(newcode,newcode1)
}
}
return(newcode)
}
datamedian(data = bc,x=age,group=age2)

总结一下,以上方法中with函数与by函数结合,tapply函数,group_by和summarize函数组合这几种方法计算很方便。

















 2596
2596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











