









列线图,又称诺莫图(Nomogram),它是建立在回归分析的基础上,使用多个临床指标或者生物属性,然后采用带有分数高低的线段,从而达到设置的目的:基于多个变量的值预测一定的临床结局或者某类事件发生的概率。列线图(Nomogram)可以用于多指标联合诊断或预测疾病发病或进展。
近些年来在高质量SCI临床论文中用的越来越多。列线图将回归模型转换成了可以直观的视图,让结果更容易判断,具有可读性,例如:
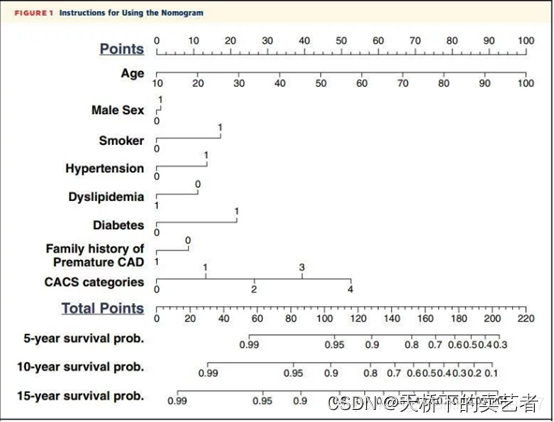
对于复杂设计调查(Survey-Weighted)的数据,我们不能使用RMS包直接绘制预测模型列线图,这样会造成数据偏差,既往我们已经介绍了SvyNom包绘制复杂设计调查(Survey-Weighted)的数据cox回归的列线图,今天我们来介绍绘制复杂设计调查(Survey-Weighted)的数据logistic回归列线图-Cindex-ROC-校准曲线绘制-外部验证,继续使用我们的转移性胃癌数据,我们先导入数据和R包
library("rms")
library("survey")
bc<-read.csv("E:/r/test/noNA.csv",sep=',',header=TRUE)
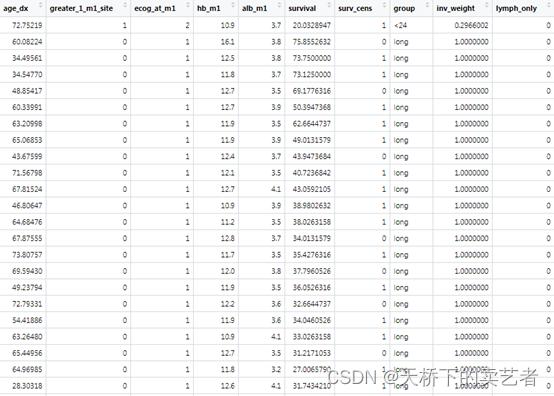
上图只显示了一部分,这是一个转移性胃癌患者(Power、Capanu、Kelsen 和 Shah 2011)的数据(公众号回复:胃癌数据,可以获得数据),数据很多我们选取一部分建模,age_dx:年龄,group:分组变量,分为存活率小于2年的和大于两年的,inv_weight:概率权重,ssize:每个分组患者的人数,survival生存时间,surv_cens生存结局
先要注意一下,这是个生存数据,我们把它当成二分类数据来分析,做个演示而已。
因为我们要进行外部验证,所以要分成建模集和验证集
tr1<- sample(nrow(bc),0.8*nrow(bc))##随机无放抽取
bc_train <- bc[tr1,]#70%数据集
bc_test<- bc[-tr1,]#30%数据集
要建立调查加权,我们先要生成一个调查表,我们这里是根据患者是否能活超过24个月进行分层,
本文为转载文章,原文地址为: https://mp.weixin.qq.com/s?__biz=MzI1NjM3NTE1NQ==&mid=2247487455&idx=1&sn=a690bb9a24d89ed17ca614416ee73dc9&chksm=ea26efc3dd5166d5ae060ba90dad8b2bb4aff9a5d6ade4f33c91717c6777b7e4d79ac3a8ac83#rd














 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









