









我们在建立数据模型后通常希望在外部数据验证模型的检验能力。然而当没有外部数据可以验证的时候,交叉验证也不失为一种方法。交叉验验证(交叉验证,CV)则是一种评估模型泛化能力的方法,广泛应用中于数证据采挖掘和机器学习领域,在交叉验证通常将数据集分为两部分,一部分为训练集,用于建立预测模型;另一部分为测试集,用于测试该模型的泛化能力。
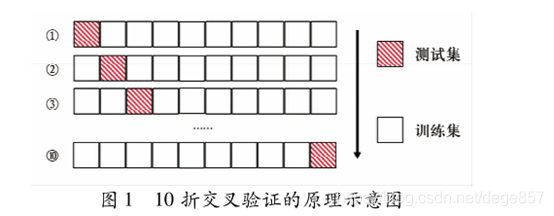
k折交叉验证可以看成是留一交叉验证的简化版,是将原始数据据随机平均分为k个子集(通常5-10个),每个子集做测试集的同时,其余k-1个子集合并作为训练 ,进行 k 次训练,取各评价指标(灵敏度、特异度、AUC等)的平均值。 测试通过平均的评价指来降低训练集和测试集划分方式对预测结果的影响,有研究值表明k 折评估准准确性高,当k为5或10时在评估准准后性和计算复杂性下综合性能最优。
10折交叉验证是指将原始数据集随机划分为样本数近乎相等的10个子集,轮流将其中的9个合并作为训练集,其余1个作为测试试集。算正确率等评价指标,最终终通过K次试验验后取评价指标的平均值来评估该模型的泛化能力。
目前我在sciml包编写了scikfoldcv函数,可以轻松实现机器学习模型进行10折交叉验证,下面我来演示一下
先导入数据和R包
library(scitable)
library(sciml)
library(httr)
library(base64enc)
bc<-read.csv("E:/r/test/buyunzheng.csv",sep=',',header=TRUE)
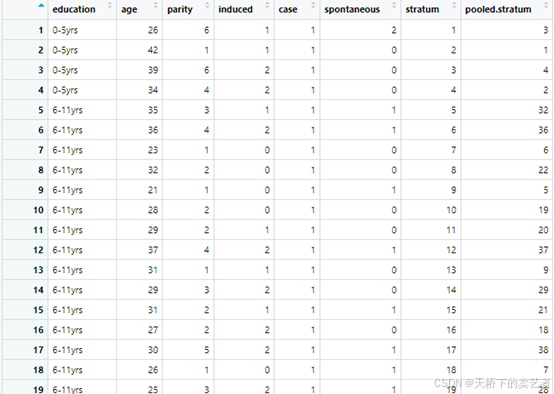
这是个不孕症数据,公众号回复:不孕症,可以获得数据,数据有8个指标,最后两个是PSM匹配结果,我们不用理他,其余六个为:
Education:教育程度,age:年龄,parity产次,induced:人流次数,case:是否不孕,这是结局指标,spontaneous:自然流产次数。
有一些变量是分类变量,我们需要把它转换一下
bc$education<-ifelse(bc$education=="0-5yrs",0,ifelse(bc$education=="6-11yrs",1,2))
bc$spontaneous<-as.factor(bc$spontaneous)
bc$case<-as.factor(bc$case)
bc$induced<-as.factor(bc$induced)
bc$education<-as.factor(bc$education)
假设咱们需要对不孕症进行随机森林分析,了解模型AUC值,
先要定义输入模型得变量
var<-c("education", "age", "parity", "induced","spontaneous")
10折交叉验证很简单,就是一句话代码
cv_results <- scikfoldcv(data=bc, y="case",var = var,type="randomForest",username = username, token = token)
生成得cv_results就是结果
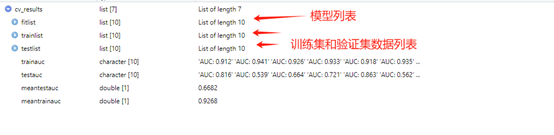
cv_results的生成结果很多,咱们先把结果提取出来
newdata2<-cv_results[["testlist"]]
fitlist<-cv_results[["fitlist"]]
接下来咱们使用m.sciroc函数来绘图,因为fitlist这里是个列表,所以咱们要加上参数oblist = T,等于告诉函数,你输入的是个列表
library(scitable)
out<-m.sciroc(fitlist,newdata = newdata2,oblist = T)
out[["p"]]
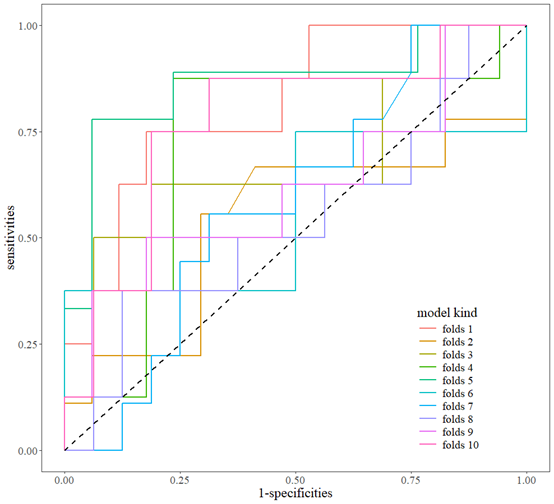
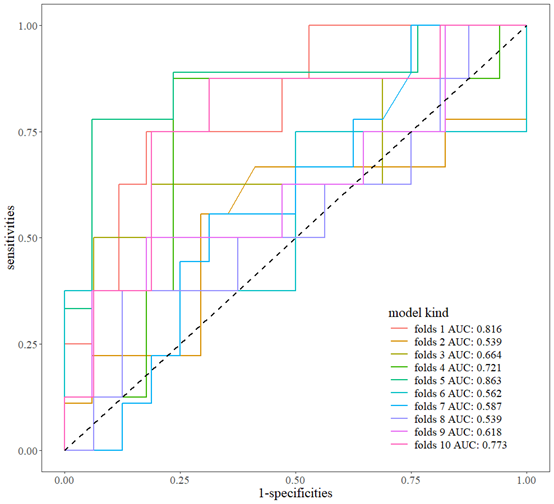
因为咱们的验证集数据比较少,所以线条不够连续,咱们还可以把AUC值提取出来进行二次绘图
auc<-out[["rocauc"]]
out<-m.sciroc(fitlist,newdata = newdata2,legend.name = auc,oblist = T)
out[["p"]]
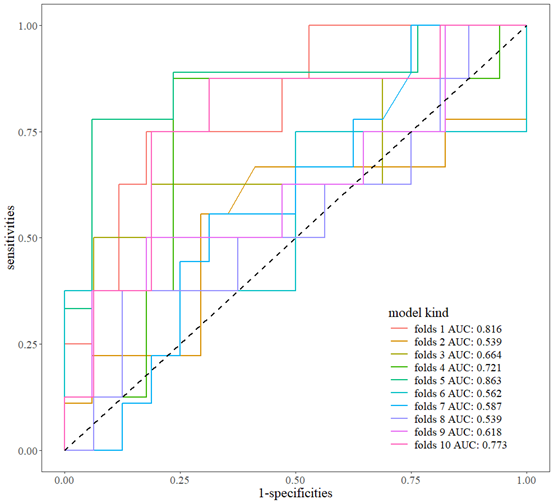
这样一个可以用于发表的随机森林10折交叉验证的ROC曲线就绘制好了,本函数还在进一步完善中。下面还有视频介绍
sciml包scikfoldcv函数轻松实现机器学习模型进行10折交叉验证



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











