







向AI转型的程序员都关注了这个号????????????
机器学习AI算法工程 公众号:datayx
text2vec, chinese text to vetor.(文本向量化表示工具,包括词向量化、句子向量化)
本文相关代码 获取
关注微信公众号 datayx 然后回复 文本相似似度 即可获取。
AI项目体验地址 https://loveai.tech
Feature
文本向量表示
字词粒度,通过腾讯AI Lab开源的大规模高质量中文词向量数据(800万中文词),获取字词的word2vec向量表示。
https://ai.tencent.com/ailab/nlp/embedding.html
句子粒度,通过求句子中所有单词词嵌入的平均值计算得到。
篇章粒度,可以通过gensim库的doc2vec得到,应用较少,本项目不实现。
文本相似度计算
基准方法,估计两句子间语义相似度最简单的方法就是求句子中所有单词词嵌入的平均值,然后计算两句子词嵌入之间的余弦相似性。
词移距离(Word Mover’s Distance),词移距离使用两文本间的词嵌入,测量其中一文本中的单词在语义空间中移动到另一文本单词所需要的最短距离。
query和docs的相似度比较
rank_bm25方法,使用bm25的变种算法,对query和文档之间的相似度打分,得到docs的rank排序。
Result
文本相似度计算
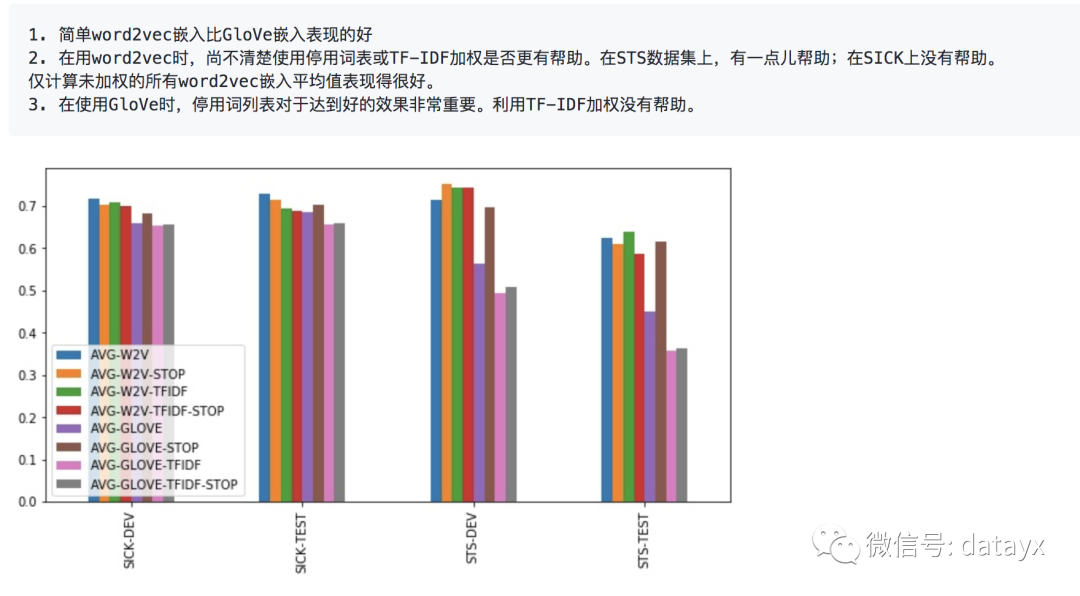
基准方法
尽管文本相似度计算的基准方法很简洁,但用平均词嵌入之间求余弦相似度的表现非常好。实验有以下结论:
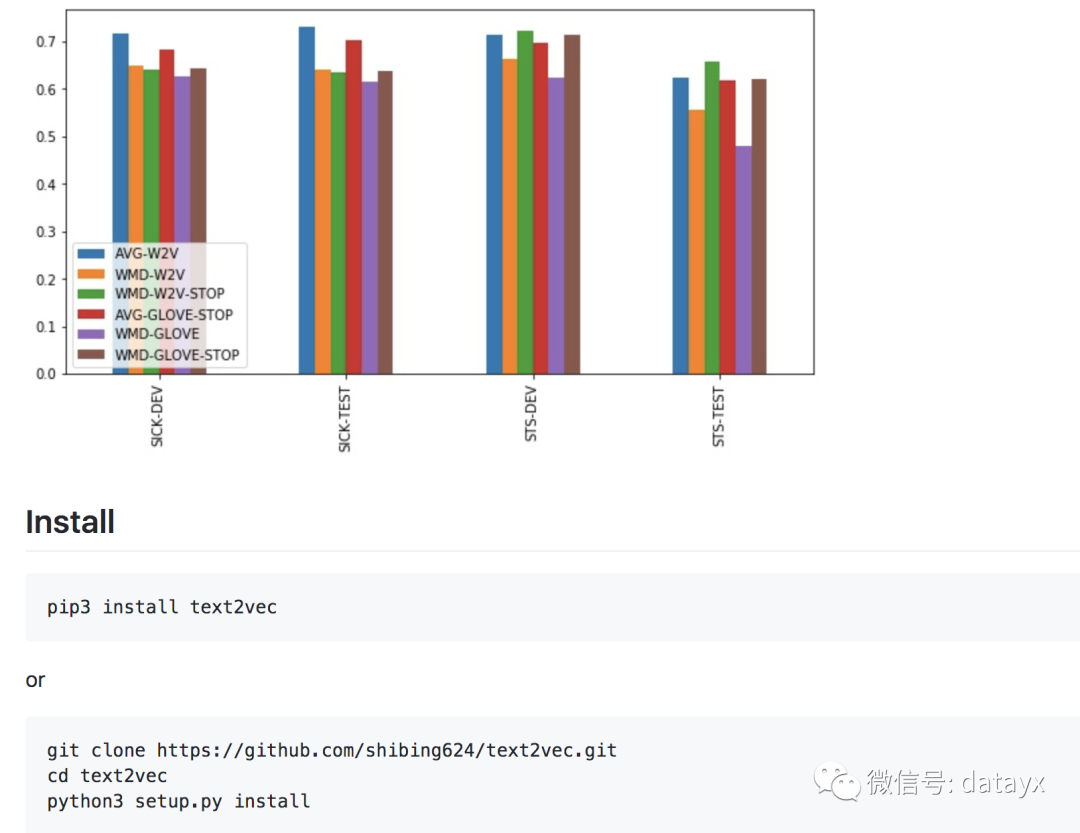
词移距离
基于我们的结果,好像没有什么使用词移距离的必要了,因为上述方法表现得已经很好了。只有在STS-TEST数据集上,而且只有在有停止词列表的情况下,词移距离才能和简单基准方法一较高下。
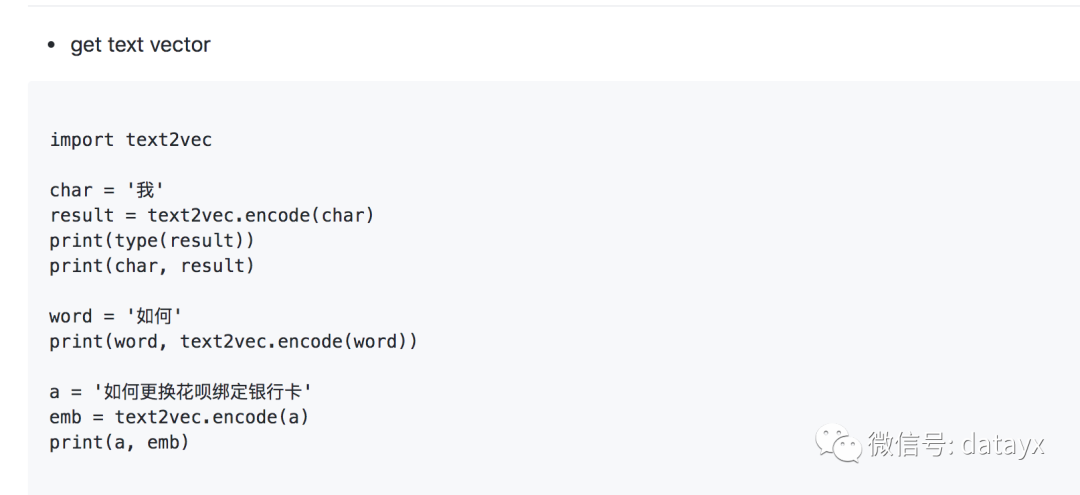
Usage:
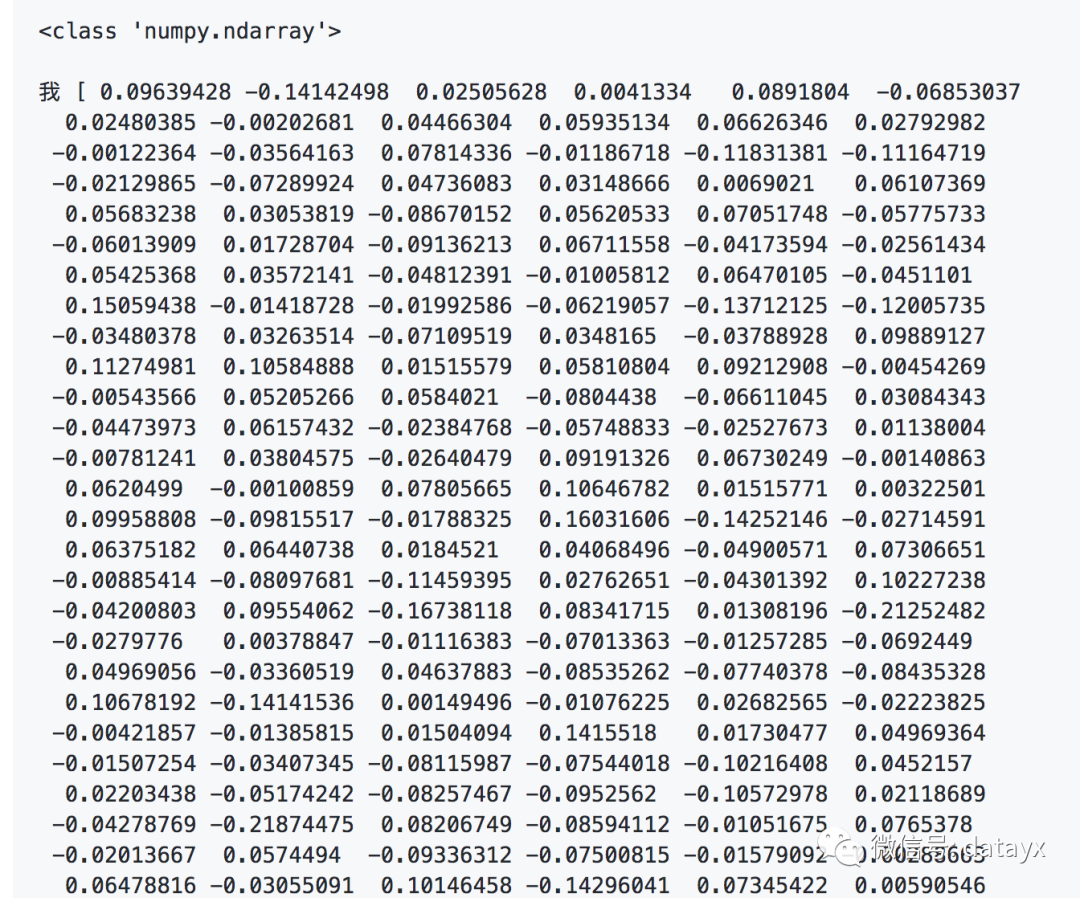
output:

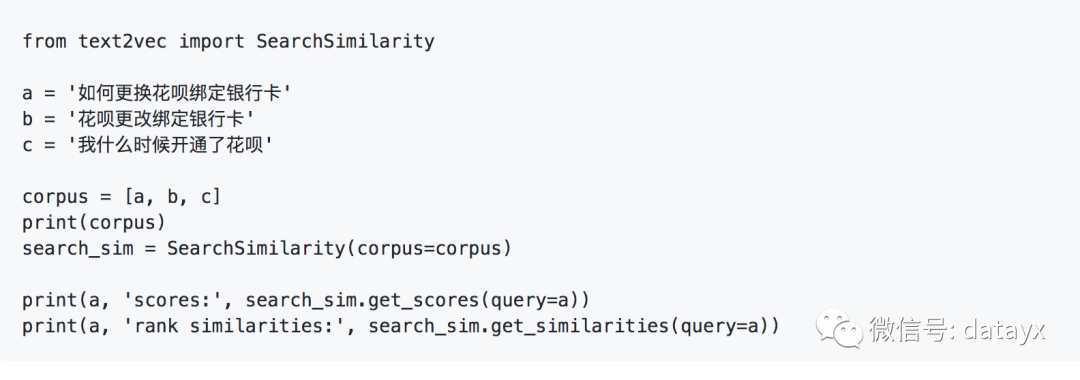
get similarity score between text1 and text2
from text2vec import Similarity
a = '如何更换花呗绑定银行卡'
b = '花呗更改绑定银行卡'
sim = Similarity()
s = sim.get_score(a, b)
print(s)


get text similarity score between query and docs

阅读过本文的人还看了以下文章:
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

QQ群
333972581


















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









