







向AI转型的程序员都关注了这个号👇👇👇
前言
这段时间一直在搞文档矫正相关实验,阅读了大量相关论文,今天来记录一篇目前比较经典,实用性较好的方法,doctr++
paper:https://arxiv.org/abs/2304.08796
一、介绍
Doctr++除了提出一种新的architecture外,most importantly,提出了一种新的数据处理方式,解决了以前文档矫正只能处理带有边界信息的完整文档,文章通过数据处理定义了三种类型的训练数据。
图1展示了三类常见的形变文档图像:(a) 包含完整文档边界,(b) 包含部分文档边界,(c ) 不包含文档边界。

二、方法理论
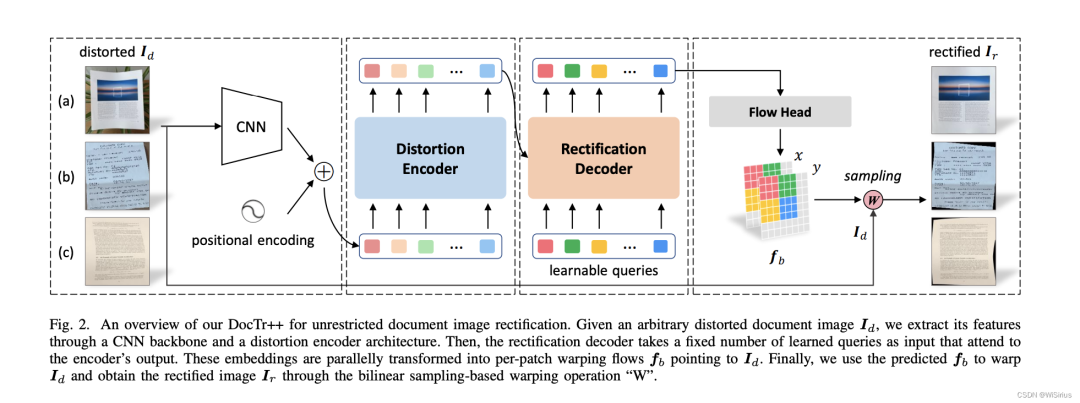
其实网络结构很简单,input未矫正图像,firstly,extract the feature through CNN, then, 经过一个transformer(这个部分相比original transformer结构有变动),finally,经过一个flow head进行最终预测。具体结构如下:
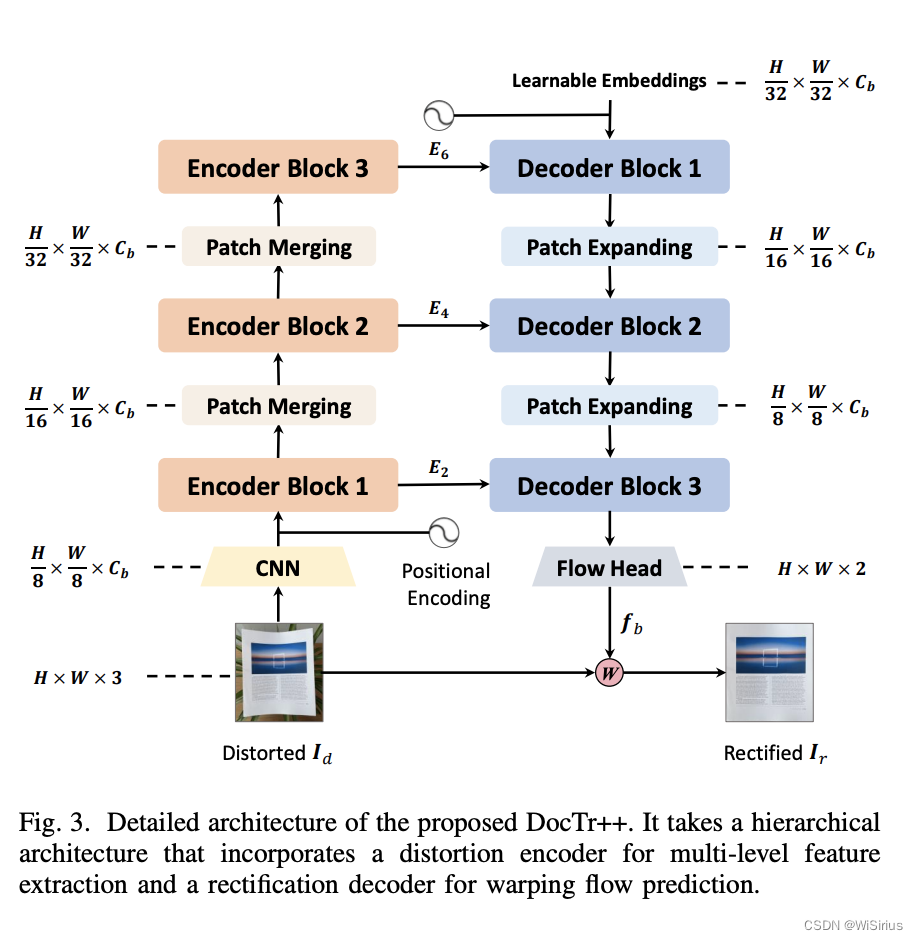
首先, 在畸变特征编码器中,DocTr++采用自注意力机制捕获形变文档的结构特征,并构建多尺度编码器,进行特征提取和融合。其中,编码器由三个子模块组成,每个子模块包含两个标准的 Transformer 编码层。这使得本方法既能编码具有高分辨率纹理细节的特征,又能获得低分辨率具有高层语义信息的特征。
接下来,矫正解码器接收编码器输出的多尺度特征以及可学习的矫正提示向量序列(Learnable Queries),输出解码后的表征用于后续坐标映射矩阵的预测。其中,可学习的矫正提示向量序列零初始化,并加上固定的位置编码。**实验发现,每一个矫正提示向量会关注输入形变文档图像中的某一特定区域,这些区域组合起来便覆盖整张输入图像。**同样,解码器由三个子模块组成,每个子模块包含两个标准的 Transformer 解码层。

三、评价指标
论文提出了两种新的评价指标 MSSIM-M 和 LD-M,用于通用形变文档图像矫正质量的评估。因为边界不完整的形变文档图像在矫正后可能会出现像素缺失,本文将有效像素区域的掩膜矩阵与目标图像进行矩阵乘法,得到更适宜进行评价的目标图像。

四、实验细节与结果
配置如下:
input:288x288
output:288x288
learning rate:1e-4
65 epochs with batch size of 12
实验结果如下:

总结
DocTr++突破了现有多数矫正方法的场景局限性,能够恢复日常生活中常见的各种形变文档图像。为了实现优秀的矫正效果,DocTr++采用了一种多尺度编解码器结构,构建各类形变文档图像与无形变文档图像之间的逐像素映射关系。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx



















 2713
2713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









