







目标url:https://bz.zzzmh.cn/
一个图片大小10M左右吧

1.找非高清url
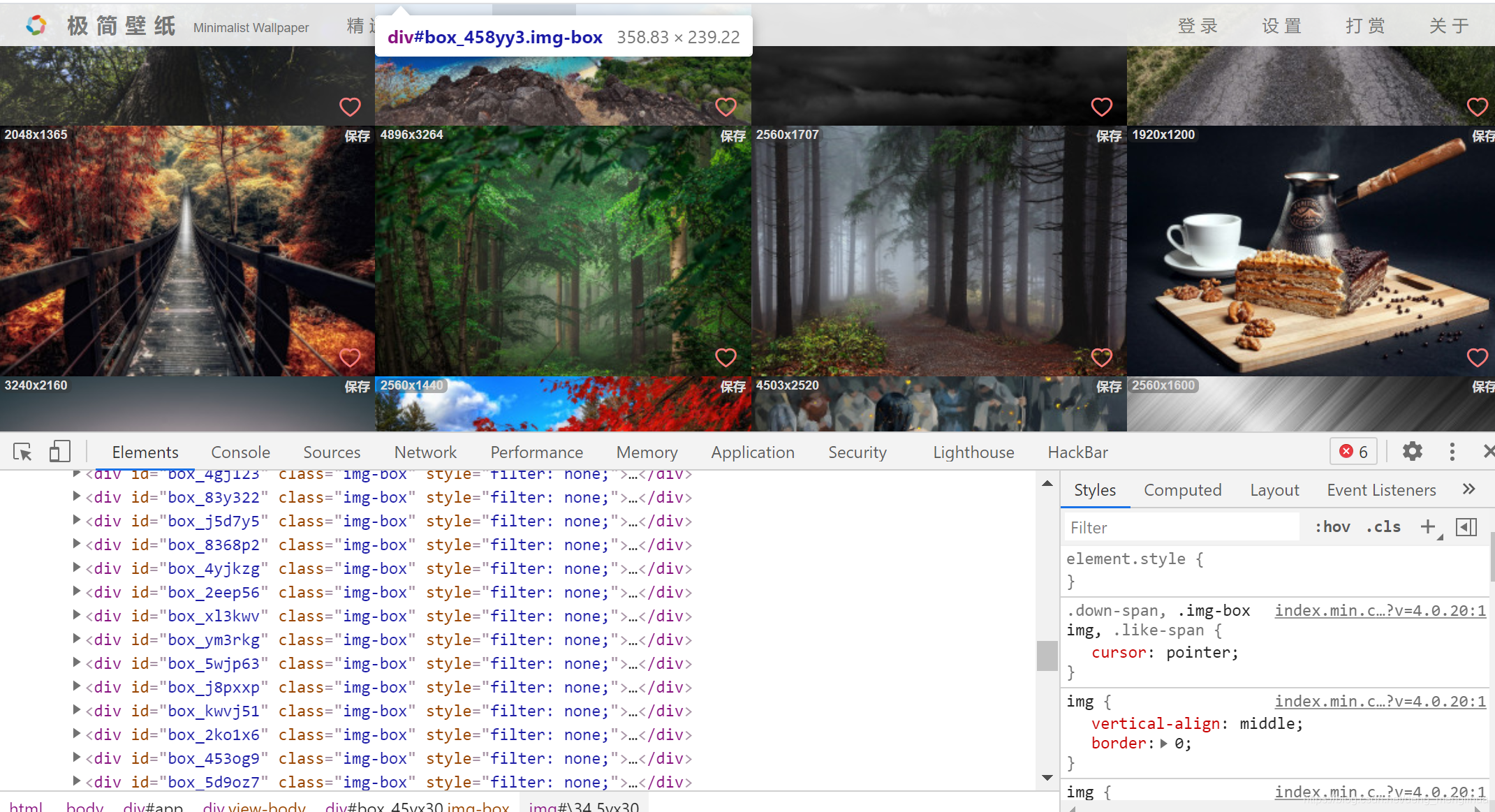
把前端保存成txt文件,里面包含非高清图的url
我保存的txt文件为:https://github.com/dengxmenglihua/files
2.找高清图对应的url特点


高清图url:https://w.wallhaven.cc/full/4g/wallhaven-4g3vm3.jpg
非高清图url:https://th.wallhaven.cc/small/4g/4g3vm3.jpg
对比一下规律,就可以根据其关系找到对应的高清图url。
3.通过脚本爬取图片
我是通过本地文件获取url关键词
import re
import requests
import os
import threading
x=1
r=[]
url1="https://w.wallhaven.cc/full/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"}
def pa(i,se):
try:
se.acquire()
global x
c=i
d=i[0:2]
#print(c,d)
m="/wallhaven-"
n=".jpg"
p=".png"
url=url1+d+m+c+n
res=requests.get(url,headers=headers)
#print(res)
if res.status_code == 200:
y = './动漫/' + str(c) + '.jpg'
else:
y = './动漫/' + str(c) + '.png'
url=url1+d+m+c+p
res = requests.get(url, headers=headers)
if res.status_code==200:
res_content=res.content
#print(res_content)
if not os.path.exists('./动漫'):
os.mkdir('./动漫')
with open(y,'wb+') as g:
g.write(res_content)
x+=1
print(x,y)
se.release()
except:
se.release()
def duo():
with open('./index.txt','r',encoding='utf-8') as f:
a=f.readline()
#print(a)
b=re.findall(r'img id="(.*?)"',str(a))
print(b)
semphore=threading.Semaphore(20)
h=0
for i in b:
h+=1
print(h)
t=threading.Thread(target=pa,args=(i,semphore))
t.start()
r.append(t)
for j in r:
j.join()
duo()
注意:此脚本要和下载的index.txt在同一文件夹下
运行结果



欢迎大家评论交流














 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









