






SinGAN: Learning a Generative Model from a Single Natural Image(2019)阅读笔记
此篇文章是2019年CVPR的最佳文章
Introduction
生成对抗网络(GAN)是Ian goodfellow等人在2014年提出的一个生成模型。它由两个部分组成,一个是生成器,另一个是鉴别器,它与发生器是一种对立的关系。该生成器的目的是生成假目标,并试图完全欺骗鉴别器的识别。鉴别器通过学习真实目标和虚假目标,提高自我识别能力,不让虚假目标欺骗自己。
生成式对抗网(GANs)在建模视觉数据的高维分布方面取得了巨大的飞跃。然而,捕获具有多个对象类的高度不同的数据集的分布仍然被认为是一个主要的挑战,通常需要根据另一个输入信号调整生成,或者为特定的任务训练模型。
一般来说,GAN的训练集类别比较具体,需要大量的训练图像。但是作者将GANs的使用带入了一个新的领域——从单一的自然图像中无条件地生成图像。
Contribution
1.SinGAN可以在一个简单的统一学习框架中使用,解决各种图像处理任务,包括从一张图像到另一张图像的绘制、编辑、协调、超分辨率和动画。
2.该模型产生了高质量的结果,保持了训练图像的内部patch统计量。
3.所有的任务都是在相同的生成网络中完成的,没有任何额外的信息或原始训练图像之外的进一步训练。
Multi-scale architecture

这个网络的pipeline如图所示,是由许多GANs组成的一个金字塔,所有的训练和推理都是由粗到细的方式进行的。在每个尺度模块上,Gn学习生成图像样本,用Dn进行识别。当往上移动时,有效块会减小(黄色部分),这是因为首次输入的是一个缩小很小的原图,Dn和Gn都有较大的接受域(感觉可以理解为视角域),对应到原尺寸大小的图上就会显得有效块很大,随着输入尺寸增大,接受域也在逐渐减小,黄色的区域也会减小,同时也意味着生成的更加精确。
主要公式:
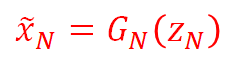
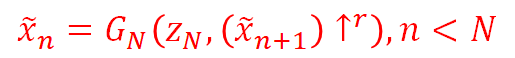

在每一个尺度上,Zn为添加的随机噪音,xn+1是上一个尺度生成器生成的图像,在被上采样并和Zn一起输入五个conv层,输出的是一个参加图像xn。
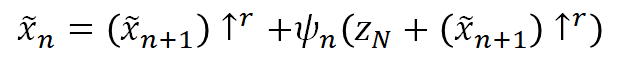
Training
从粗粒度到细粒度,一旦每一个GAN被训练后他就会一直保持不变。故对第n个GAN的训练损失包含一个对抗损失和从简损失:
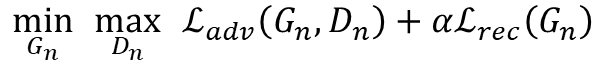
具体细节看文章。
Experience
从不同的尺度生成的图像:

从图中可以看到不同的尺度层生成的图像还是有很大差异的,例如,在粗粒度N层我们可以保留斑马的形状和姿势,只有从(𝑛=𝑁−1)开始生成才能改变其条纹纹理。 使之正常。
不同尺度的训练结果:

尺度数量对结果有很大的影响。只有少量比例的模型只能捕获纹理。随着尺度数量的增加,SinGAN成功地捕获了更大的结构和全局结构。
至于他的应用文章介绍的很清楚,包括超分辨率、图画、协调、编辑等等。本文就不细说了。
可以说SinGAN可以为广泛的图像处理任务提供一个非常强大的工具。但是也有局限性,因为SinGAN是根据单一图像生成的,所以如果训练图像包含一条狗,我们的模型将不会生成不同犬种的样本。















 8180
8180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









