







Authors
Tamar Rott Shaham,Tali Dekel,Tomer Michaeli
Motivation
unconditional GANs 对特定类数据集进行训练时,在生成真实、高质量的样本方面取得了显著的成功。
然而,提取具有多个对象类的高多样性数据集的分布仍然是一个主要挑战(如imagenet),并且通常需要加入另一个输入信号作为condition,或者为特定任务训练模型(如超分辨率、修复、重定目标)。(该bg我不理解,引用了另一篇博客的)
GAN在最开始提出就是学习图像分布然后生成和训练图像类别相同的图像,那么这就有第一个限制,训练集的类别是具体的(Specific),一些无条件GAN通常都是这样的训练方式,在class-specific的数据集上训练,同时如果类别众多,性能就会出现下降。比如一些生成人脸的GAN用ImageNet训练,生成那些多种多样的类别的图像,效果其实很差的(这方面我做过实验),所以一般要加入其它条件来帮助训练,一般都是指定图像的类别送进网络作为条件(condition)。
另外一个限制就是图像需要很多张。如果我们仅仅在一张图片上训练, 非条件GAN中,目前这样的方法只适用于具体任务,比如超分辨,纹理扩展( texture expansion)。
原文链接:https://blog.csdn.net/qq_34914551/article/details/102812286
Novelty
- 以解决各种图像操作任务,包括从单个图像绘制到图像、编辑、协调(融合?)、超分辨率和动画。
如图所示的用途:

- 产生高质量的,能保留训练样本原始数据分布,又同时能创造新的configuration和structure的图像
- 在一个简单的统一学习框架中使用,网络结构简单
- 只在一张图上训练,不care各种分类类别(这种学习方法很有意思)
Network
G

该方法使用了patch-gan捕获global的properties,用多尺度的结构,从下往上是coarse到fine的过程。生成器的集合为![]() ,金字塔形的训练原始数据为
,金字塔形的训练原始数据为![]() ,Xn是X的n倍下采样数据,每个Gn用于生成
,Xn是X的n倍下采样数据,每个Gn用于生成![]() ,所有的G和D有这相同的结构,同样的RF。因而有
,所有的G和D有这相同的结构,同样的RF。因而有![]() ,Zn是噪点。将下一层生成的
,Zn是噪点。将下一层生成的![]() ,与本层的燥点Zn同时送入网络Gn,得到最终该scale的输出,即为:
,与本层的燥点Zn同时送入网络Gn,得到最终该scale的输出,即为:![]()
,通过融合Zn和![]() ,最终Gn的表达为
,最终Gn的表达为![]()
![]() 是5个conv-block,(i.e.,Conv(3×3)-BatchNorm-LeakyReLU),如图
是5个conv-block,(i.e.,Conv(3×3)-BatchNorm-LeakyReLU),如图

其它kernel设置的细节如下面文字所示
D
第n个GAN的loss function如下面公式,其实就是分scale进行backprog
![]() ,其中
,其中![]() 就表示对抗损失,measure了
就表示对抗损失,measure了![]() 和生成的
和生成的![]() 样本,
样本,![]() 表示重建loss,为了使得能够产生有噪声图能合成Xn,
表示重建loss,为了使得能够产生有噪声图能合成Xn,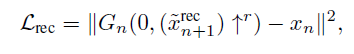 ,其中
,其中![]() ,
,![]() 是在训练过程中固定的噪点图。当n=N时,
是在训练过程中固定的噪点图。当n=N时,![]() (结合图4架构看就了然了)
(结合图4架构看就了然了)
D的结构和![]() 一样,也就是说,RF大小是11X11(i.e., patch size shi 11*11)
一样,也就是说,RF大小是11X11(i.e., patch size shi 11*11)
![]() 使用了WGAN-GP loss,值得注意的是针对整张图,而不是patch的loss。由于是multi scale的,所以batch-size为1
使用了WGAN-GP loss,值得注意的是针对整张图,而不是patch的loss。由于是multi scale的,所以batch-size为1
Zn的细节
Result
见原文效果。

















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









