






5.Transformer
【内含公式,建议PC端浏览器阅读】
编码与解码
位置编码
多头自注意力
以上3个小节的内容请见《鞋匠的AI之旅》- 5. Transformer【上】
综合决策
鞋匠假想着要为自己的擦鞋事业举办一个大型宣传活动,需要协调多个方面的工作,比如,场地布置、音响设备、节目安排、会员办理、抽奖活动等等,每一个方面都需要细致入微的处理。为此鞋匠特地雇佣了几个专业小组来分别负责上面各方面的工作,比如
- 小组A负责场地布置
- 小组B负责音响设备
- 小组C负责节目安排
- 小组D负责会员办理
- 小组E负责抽奖活动
每个小组根据他们的专长,分别提出自己的建议和方案。这些方案最终汇总到了鞋匠这里。鞋匠是擦鞋界最为知名的擦鞋工作者,在技术上有着深厚的积淀,对未来有着长远的规划,对业界有着深入的洞察。他以业界的上帝视角综合各个小组的建议,做出最终的决策。
这里的小组安排就是典型的工作分类并把每个分类并行处理。这和前面章节里的多头自注意力机制很相似。鞋匠觉得其实可以把多头自注意力机制想象成这里的多个专家小组,而鞋匠以上帝视角的综合决策过程则需要另外的模块来承载。顺着Transformer编码器的多头自注意力子层再往上攀登,鞋匠看到了一个前馈神经网络(Feed Forward),那里应该就是“综合决策”的地方。对于解码器来说,需要跨过一个类似多头自注意力的子层,才能来到前馈神经网络。鞋匠打算后面再来研究这个被跨过的子层。
要以上帝视角做综合决策,不仅需要考虑各小组提报的方案,还需要掌握很多其它方面的信息,把具体的方案放到一个有很多方面信息的大环境里来评估。如果把每个方面看作一个维度的话,鞋匠认为自己是站在了更高的维度上来评估专家小组提报的方案。然后根据评估结果对方案进行调整,最后形成最终的方案,这个方案里包含了大环境的影响,但已经看不到大环境原本的信息了。从这个层面来讲,鞋匠觉得自己利用了高维信息,但最终调整后,方案又回到了其原本的现实维度。如果按照这个思路的话,鞋匠觉得这个前馈神经网络子层应该是一个两层的全连接神经网络,第一层负责将多头自注意力子层的输出映射到更高维空间,即在更高的维度来评估各“专家小组”提报的方案,综合审视多头自注意力的拼接输出。第二层是把这个在更高维空间的评估结果降维映射回原来的维度空间,形成对最终方案的调整,即新的输入向量矩阵的表示,这个新的表示综合了多头自注意力捕捉到的更为细节的局部关联信息,并结合了更高维度的信息对这个向量矩阵的调整。
鞋匠沿用前面多头自注意力子层的输出,继续研究着这个前馈神经网络的计算过程:
C = Concat(C1, C2, C3, C4) = [8 × 256]
这是针对![]() 应用多头自注意力机制得到的上下文向量矩阵,是对
应用多头自注意力机制得到的上下文向量矩阵,是对![]() 的新的表示。它就是前馈神经网络的输入,按照上面的推理,在前馈神经网络的第一层应该将C映射到更高维的空间。鞋匠假设这个更高维的维度为512,这一层的输入权重矩阵为
的新的表示。它就是前馈神经网络的输入,按照上面的推理,在前馈神经网络的第一层应该将C映射到更高维的空间。鞋匠假设这个更高维的维度为512,这一层的输入权重矩阵为![]() ,偏置项为
,偏置项为![]() ,激活函数为ReLU。显然这里
,激活函数为ReLU。显然这里![]() 的形状为256 × 512,
的形状为256 × 512,![]() 的形状为1 × 512。
的形状为1 × 512。
鞋匠觉得现实生活中本来就充满了尖尖角角,没有一帆风顺的平滑,所以按照现实的指引在这个前馈神经网络里引入非线性还是有必要的,因此选择了ReLU这样的激活函数。应用前面总结的神经网络输入输出的计算方法,第一层的输出计算过程如下:
![]()
仅从矩阵点积算法来看,![]() 形状应为[8 × 256]·[256 × 512] + [1 × 512] = [8 × 512]。显然这里
形状应为[8 × 256]·[256 × 512] + [1 × 512] = [8 × 512]。显然这里![]() 从256维升维到了512维。其中
从256维升维到了512维。其中![]() 和
和![]() 都是在Transformer模型训练的过程中待优化的参数。在更高维度(512维)得出的输出,会经过前馈神经网络的第二层重新映射回原来的维度,即完成对原输入
都是在Transformer模型训练的过程中待优化的参数。在更高维度(512维)得出的输出,会经过前馈神经网络的第二层重新映射回原来的维度,即完成对原输入![]() 的调整。其计算过程如下:
的调整。其计算过程如下:
![]()
由于第二层是把第一层的输出映射回原维度空间,所以这里![]() 和
和![]() 形状应该是一致的,都是8 × 256。按照点积算法,那么这里
形状应该是一致的,都是8 × 256。按照点积算法,那么这里![]() 的形状应该维512 × 256,而
的形状应该维512 × 256,而![]() 应该是1 × 256,分别代表第二层神经元输入权重矩阵和偏置项。它们也是在Transformer模型训练的过程中待优化的参数。
应该是1 × 256,分别代表第二层神经元输入权重矩阵和偏置项。它们也是在Transformer模型训练的过程中待优化的参数。
通过这种方式,前馈神经网络子层对多头自注意力子层的输出进行进一步的处理,使得最终的信息更加全面、优化和精炼,能够更好地指导后续的工作。鞋匠把这种多头自注意力子层和前馈神经网络子层组合在一起,就形成了一个Transformer基本块,把它应用到编码器,就称为一个编码器层,把它放到解码器就称为一个解码器层,如图22所示,左侧是一个编码器层,右侧是一个解码器层。解码器层和编码器层稍有不同,在解码器层中间多了一个子层。这就是刚刚被跨过的子层,鞋匠打算放到后面再研究。
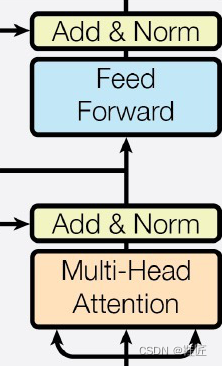
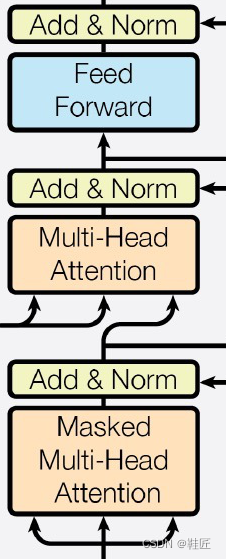
图22,编码器层和解码器层
考虑到信息关联提取和整合的复杂性,一个Transformer模型中,往往会在解码器侧同时串联多个编码器层,而在解码器侧串联多个解码器层,它们的层数保持一致。具体的层数选择是基于实验结果和模型复杂性之间的权衡。但随着层数的增加,又引入了新的问题:在靠后的编码器层或者解码器层中,其激活函数在输入的向量矩阵所确定的高维点处得到一个偏导数较小的结果,在这个结果非常小的情况下,会得到一个非常小的梯度向量。按照前面在推导梯度的例子中所说明的,在3维空间下,梯度非常小可以想象成输入向量矩阵所确定的3维点处其坡度很缓,或者几乎没有坡度,变成一个几乎与地面平行的平面了。在这种情况下,按照前面推导的梯度下降法来调整AI模型的参数将会变得极其缓慢,增加训练时长,相应地也会增加计算资源的消耗。这主要是因为,一方面调整步长会变得很小,另一方面如果要捕捉到更为细小的梯度,就要增加计算精度,但计算精度受到AI模型整体的数值稳定性要求和硬件支持的计算精度的限制。鞋匠把这类梯度变得很小的问题称为梯度消失问题。他觉得需要想个办法来解决。
残差与归一化
看到编码器层和解码器层的信息层层传递,鞋匠想起了小时候玩过的一个“传词接龙”的游戏。游戏里小朋友排成一排,从前往后通过口头传递信息的方式,逐一向后传递最前面一位小朋友看到的一个名词,比如苹果、汽车、大象,等等。这个名词只有最前面一个小朋友能看到。第一位小朋友在传递给第二位小朋友时不能说出他看到的这个名词,如此传递到最后一个小朋友处,请最后的小朋友猜出那个名词。由于传递过程中的解释和描述可能产生偏差,最后的答案往往会与最初的名词相去甚远,从而带来趣味性和娱乐效果。在这个过程中,每个小朋友都接收前一个小朋友的输入,这个输入是经过前一个小朋友的处理的,是这个小朋友思考后整理的出来的结果。这像极了以上编码器和解码器对信息的层层加工和传递过程。鞋匠想如果每个小朋友都有机会直接将自己掌握的信息传递给下一位的同时,也传递给下下一位,这种信息在传递过程中产生较大偏差的情况可能会大大减少,因为除了最前面的小朋友外,其他每个小朋友都会有两个信息来源,提升了他对所传递信息的理解,从而在一定程度上纠正了偏差。而最前面的小朋友接收的是原始输入,他接收的是全量信息,也就不需要并且没有什么另外的信息来源了。如图23所示,橙色的信息流向就是信息直接传递给下下一个小朋友的过程。
![]()
图23,传词接龙游戏的改进
同样的道理,鞋匠觉得这种机制也可以应用到编码器层和解码器层。为方便描述,他把上图中的橙色连接称为残差连接。
梯度除了会变得很小外,鞋匠觉得它可能还会变得很大,甚至可能会出现发散的情况,这对AI模型的训练来说也是极为不利的。鞋匠把这种变得很大的问题称之为梯度爆炸。无论是梯度消失还是梯度爆炸,在数学的意义上都是在该层的输入向量矩阵所确定的高维点处其梯度变得太小或者太大,而这个高维点落在何处是由该层的输入向量矩阵来决定的,因此比较直观有效的方法就是调整输入向量矩阵,控制其对应的高维点落在一个合理的区间。“控制某些数值落在某一区间”这让鞋匠想起了归一化。比如一个班级有30位同学,期中考试一共测试了两门课程,学科A满分是120分,学科B满分是100分。显然这里学科A的110分比学科B的满分100分从分值上看是多出10分,但就考察效果来看110分说明该学生对学科A考察的内容没有完全掌握,而对满分的学科B掌握的却很好。所以老师希望以百分制来对同学们的成绩进行评价,这就要求把同学们的学科A的考分转化到百分制分值来进行综合评估。显然这里的转化是这样的:
学科A百分制得分 = (学科A的考分 / 120) × 100
上面的例子是一个线性化的转化过程,当然也有一些非线性的转化,这依赖于需要解决的问题。鞋匠觉得可以把同样的机制应用到对AI模型某层输入的处理上,使其所对应的高维点落在一个合理的区间,从而在一定程度上解决梯度变的太大或者太小的问题,即在一定程度上解决梯度爆炸和梯度消失的问题。
回到Transformer论文中的架构图上,如图24所示,图中红线重绘的连接即是残差连接。以一个编码器层为例,其对应的多头自注意力子层和前馈神经网络子层都有对应的残差连接将该子层的输入和输出连接在一起,汇聚于黄色填充的功能块处。这里黄色填充功能块代表的就是刚刚推导的归一化,鞋匠称之为归一化模块。在这里,上一子层的输入(即上上一子层的输出)与上一子层的输出(即该归一化模块的输入)会先相加,并对其相加结果进行归一化处理。按照上面的分析,这在一定程度上将减少这两个子层在信息提取和传递上的偏差。在残差连接和归一化两种机制的加持下,提升了AI模型的训练速度和稳定性,加快了收敛。
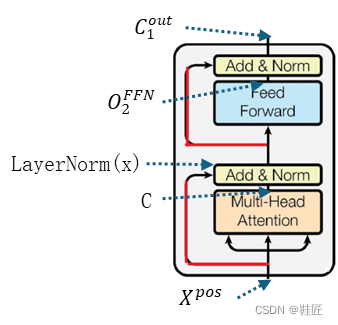
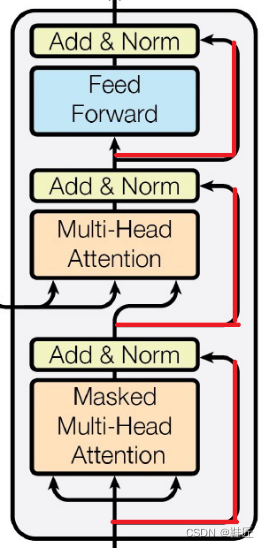
图24,残差连接与归一化
那么,这里的归一化一般是怎么做的呢?鞋匠继续沿用前面的例子来推导计算过程,这里以一个编码器层为例。在这个例子当中:
![]() 是多头自注意力子层的输入,也就是这个编码器层的输入;
是多头自注意力子层的输入,也就是这个编码器层的输入;
![]() 是多头自注意力子层的输出;
是多头自注意力子层的输出;
![]() 是前馈神经网络的输出;
是前馈神经网络的输出;
![]() 是这个编码器层的输出;
是这个编码器层的输出;
![]() 是归一化函数;
是归一化函数;
图24中标出了以上每个矩阵在该编码器层内部被计算出来的位置。
这里![]() 是待求的矩阵,而LayerNorm是一个新引入的函数。其它都是前例中已经得出的结果。
是待求的矩阵,而LayerNorm是一个新引入的函数。其它都是前例中已经得出的结果。
先来看紧跟多头自注意力子层的归一化模块的输出的计算,如下:
![]()
这里![]() 是对
是对![]() 的新的表示,它们的形状都是8 × 256。
的新的表示,它们的形状都是8 × 256。![]() 表示将多头自注意力子层的输入与其输出相加(这是由残差连接的机制保证的),其相加结果通过归一化函数进行转化,得到归一化结果
表示将多头自注意力子层的输入与其输出相加(这是由残差连接的机制保证的),其相加结果通过归一化函数进行转化,得到归一化结果![]() ,其形状为8 × 256。
,其形状为8 × 256。
同理,将归一化函数应用到紧跟前馈神经网络子层的归一化模块,其输出结果为:
![]()
这里![]() 是前馈神经网络子层的输出。该前馈神经网络子层的输入
是前馈神经网络子层的输出。该前馈神经网络子层的输入![]() (多头自注意力子层的归一化结果)与
(多头自注意力子层的归一化结果)与![]() 相加,之后经过归一化函数进行转化,得到归一化结果
相加,之后经过归一化函数进行转化,得到归一化结果![]() ,这也是该编码器层的输出,其形状为 8 × 256。
,这也是该编码器层的输出,其形状为 8 × 256。
为进一步理解LayerNorm的计算过程,鞋匠选了两个小的矩阵来演算计算细节:
假设一个子层的输入为![]() ,输出为
,输出为![]() ,它们的大小都是2 × 4,分别表示为
,它们的大小都是2 × 4,分别表示为
![]() = [
= [ ![]()
![]() ]
]
![]() = [
= [ ![]()
![]() ]
]
就像上面的例子,![]() 和
和![]() 都会输入给一个归一化模块。在这里,首先计算出两者之和:
都会输入给一个归一化模块。在这里,首先计算出两者之和:
![]()
= [ ![]()
![]() ]
]
= [ ![]()
![]() ]
]
这里![]() ,
,![]() 表示行数,共2行,即
表示行数,共2行,即![]() ,
,![]() 表示列数,共4列,即
表示列数,共4列,即![]() 。对照前面对多头自注意力子层或者前馈神经网络子层的归一化运算,这里可以把同样的算法应用于
。对照前面对多头自注意力子层或者前馈神经网络子层的归一化运算,这里可以把同样的算法应用于![]() ,用数学表达式表示则为
,用数学表达式表示则为![]() 。鞋匠正在演算的就是怎么计算
。鞋匠正在演算的就是怎么计算![]() 的每个元素的值。
的每个元素的值。
接下来求出![]() 在4个维度上特征的均值:
在4个维度上特征的均值:
![]()
![]()
这里 ![]() ,
,![]() 表示行数,共2行,即
表示行数,共2行,即![]() ,
,![]() 表示列数,共4列,即
表示列数,共4列,即![]() 。
。![]() 表示第
表示第![]() 列特征的均值。
列特征的均值。![]() 表示对
表示对![]() 的每一列的2个元素求均值。
的每一列的2个元素求均值。
有了均值之后,就可以评估![]() 相对于均值之间的差异了。鞋匠知道常用的方法是方差,这种方法的好处是可以消除元素与均值之间差值的正负所导致的差异抵消问题。比如,某一列,一个元素与均值的差异为负,而另一个元素与均值的差异为正,这两个差值之和有部分就会被抵消了,导致最后的差值之和不能代表
相对于均值之间的差异了。鞋匠知道常用的方法是方差,这种方法的好处是可以消除元素与均值之间差值的正负所导致的差异抵消问题。比如,某一列,一个元素与均值的差异为负,而另一个元素与均值的差异为正,这两个差值之和有部分就会被抵消了,导致最后的差值之和不能代表![]() 与均值之间差异的真实情况。鞋匠用
与均值之间差异的真实情况。鞋匠用![]() 代表方差,得到如下算式:
代表方差,得到如下算式:
![]()
同样的,这里![]() 表示行数,共2行,即
表示行数,共2行,即![]() ,
,![]() 表示列数,共4列,即
表示列数,共4列,即![]() 。
。![]() 表示第
表示第![]() 列特征的方差。
列特征的方差。
有了这些所有的中间结果,就可以计算![]() 的每个元素的值了。鞋匠用
的每个元素的值了。鞋匠用![]() 来表示)
来表示)![]() 第
第![]() 行第
行第![]() 列的元素值,得到:
列的元素值,得到:
![]()
这里![]() 是极小的一个数,比如
是极小的一个数,比如![]() ,以防止方差等于0的情况下分母为0。
,以防止方差等于0的情况下分母为0。![]() 和
和![]() 在公式中所处的位置有点眼熟,这让鞋匠想起了前面“新生”那一章里推导神经网络中间层输入时的表达式:
在公式中所处的位置有点眼熟,这让鞋匠想起了前面“新生”那一章里推导神经网络中间层输入时的表达式:
![]()
没错,这里的![]() 和
和![]() 起到类似的作用。
起到类似的作用。![]() 用于缩放归一化后的特征值,允许AI模型在每个维度特征上学习到一个合适的尺度,这有助于增强AI模型的表达能力。
用于缩放归一化后的特征值,允许AI模型在每个维度特征上学习到一个合适的尺度,这有助于增强AI模型的表达能力。![]() 的作用是平移归一化后的特征值,使得AI模型能够学习到对应该特征的偏置量。鞋匠把这里的
的作用是平移归一化后的特征值,使得AI模型能够学习到对应该特征的偏置量。鞋匠把这里的![]() 和
和![]() 分别称之为归一化缩放系数和归一化偏置项。
分别称之为归一化缩放系数和归一化偏置项。
至此,鞋匠看清了多头自注意力、前馈神经网络、残差、归一化等这些编码器和解码器核心组件的来龙去脉。他感觉Transformer的天空一片晴空万里,但仍有两个谜题像乌云一样遮挡了阳光。如图25的橙色划线所示。
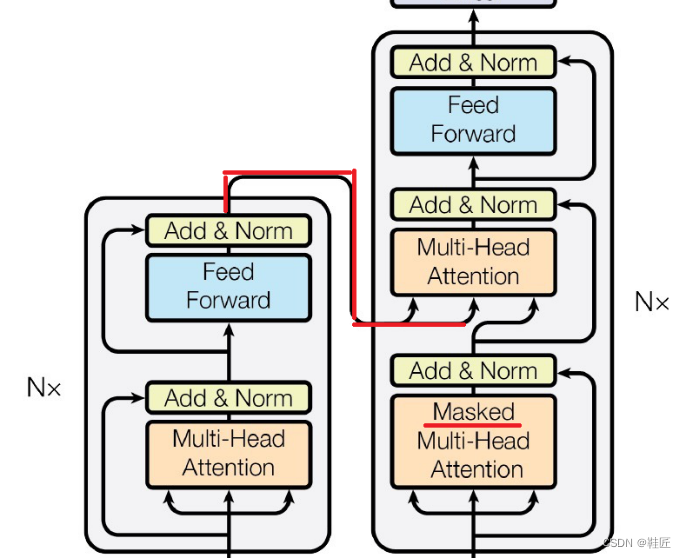
图25,忘不了的原题和看不见的未来
鞋匠把图中上面的谜题称作“忘不了的原题”,把下面的谜题称作“看不见的未来”。
>>下一章节:《鞋匠的AI之旅》- 5. Transformer【中】之“解码器的自回归”
<<上一章节:《鞋匠的AI之旅》- 5. Transformer【上】















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









