







 本文介绍了如何使用Jupyter Notebook集成IBM Spectrum Symphony进行金融分析。Jupyter Notebook是一个开源交互式笔记本,适合数据科学和机器学习。IBM Spectrum Symphony是强大的并行计算平台,尤其在金融领域。文章详细阐述了Jupyter的特性、架构,以及Symphony在蒙特·卡罗模拟方法中的应用,并提供了在Linux环境下部署Jupyter集成Symphony的步骤。
本文介绍了如何使用Jupyter Notebook集成IBM Spectrum Symphony进行金融分析。Jupyter Notebook是一个开源交互式笔记本,适合数据科学和机器学习。IBM Spectrum Symphony是强大的并行计算平台,尤其在金融领域。文章详细阐述了Jupyter的特性、架构,以及Symphony在蒙特·卡罗模拟方法中的应用,并提供了在Linux环境下部署Jupyter集成Symphony的步骤。
简介
Jupyter Notebook是一种开源的基于Web的交互式笔记本,便于管理分享程序文档,支持实时代码,可视化,以及Markdown语法,目前支持40多种编程语言,是数据科学生态圈的开发利器,与Docker技术紧密结合,用jupyterhub中的Docker镜像可以快速创建一个jupyter环境。同时与github也有结合,可以将程序文件可视化的分享给别人。使用Jupyter notebook感觉就像在草纸上作画,可以将你的思维探索过程展示出来,和众多开源软件发生碰撞,任你想象和发挥。
Jupyter作为一种交互式笔记本,具有很好的扩展性和兼容性,在数值模拟,统计建模,机器学习等方面应用非常广泛,基本上都作为这些应用的入口与后端计算平台对接,相比于直接使用单一的语言和平台,Jupyter具有很好的集成度可以将这些语言和平台集成在一起,同时借助于Python语言的灵活性和便利性,给Jupyter Notebook带来非常丰富的交互体验。使用Jupyter工具就可以得到Python丰富的数学库,Spark的内存计算能力和Tensorflow的多层神经网络。
IBM Spectrum Symphony作为一套优秀的并行计算和应用网格管理系统软件,可以为众多企业提供理想的大数据分析解决方案,尤其在金融分析领域。因此,本文将着重为大家介绍如何使用Jupyter集成IBM Spectrum Symphony的高性能计算能力,将Symphony强大的计算能力集成到Jupyter Notebook中。
表1 Jupyter的主要特性
| 特性 | 简述 |
|---|---|
| Language of choice | Jupyter支持超过40中编程语言包括Python,R,Julia和Scala。 |
| Share notebooks | Notebook可以通过有哦见,Dropbox, Github和Jupyter Notebook Viewer进行非常方便的分享。 |
| Interactive output | 你的代码可以生成丰富的交互式输出:HTML,图像,视频,Latex和其它自定义类型。 |
| Big data integration | 利用Python、R,和Scala等工具,与Spark、pandas、scikit-learn、ggplot2、TensorFlow等集成。 |
Jupyter简介
Jupyter基于开放标准,在Web前端使用HTML和CSS的交互式计算,在后端采用可扩展的kernel架构,内部使用WebSocket和ZeroMQ进行通信交互。核心是通过IPython实现,由IPython提供终端,IPython内核提供的计算和通信的前端界面。
- Notebook Document Format:基于JSON的开放文档格式,记录用户的会话(sessions)和代码、说明性的文本、方程以及富文本输出。
- Interactive Computing Protocol:该协议用于连接Notebook和内核,基于JSON数据、ZMQ以及WebSockets。
- Kernel:Jupyter的内核指的是后台计算的语言环境,是实际执行Notebook代码的地方,将输出返回给用户。
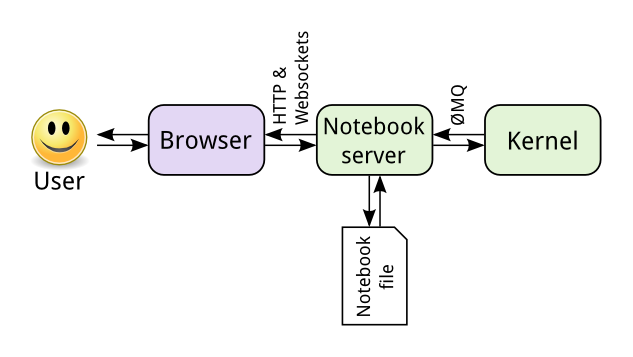
Symphony(IBM Spectrum Symphony)
IBM Spectrum Symphony 作为可伸缩性极强的企业级运算服务管理软件,可用于在可扩展、共享、异构的网格中运行分布式应用服务。它充分利用可用的计算资源,提高并行应用的运行速度并快速得到计算结果,良好的满足数据密集型与计算密集型应用,全面提升系统性能。在全球,IBM Spectrum Symphony 正在为世界 75%的金融机构提供服务。在流计算,大数据处理和计算,公有云方面都走在前沿领域。

1. Monte Carlo (蒙特·卡罗模拟方法)
蒙特·卡罗是一种以概率统计理论为指导的一类非常重要的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。与它对应的是确定性算法。蒙特·卡罗方法在金融工程学,宏观经济学,计算物理学(如粒子输运计算、量子热力学计算、空气动力学计算)等领域应用广泛。
最经典的就是用蒙特•卡罗方法计算圆周率,其思想就是在一个正方形的面积上随机撒点(总点数为M),假设有一个圆(面积为T)与正方形内切,随机点在圆内的数量N满足下面等式:
N/M=T/4,从而得出PI=4*M/N
Spark网站有关于PI的Python计算源码,非常简短:
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(xrange(0, NUM_SAMPLES)) \
.filter(inside).count()
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)该方法常用于金融领域股票期权定价,以大规模短作业为主,考研集群的调度性能和计算能力,而Symphony则是该领域的利器,支持多种编程语言,其中就包括Python,在Symphony集群上用Python实现该算法同样非常方便。
部署Jupyter环境
本文以Linux RedHat7.3操作系统为例,来说明如何安装和部署Jupyter并集成到Symphony集群。
1. 安装Symphony集群,Master host为docker.eng.platformlab.ibm.com
[root@docker sym]# soamview app
APPLICATION STATUS SSM HOST SSM PID CONSUMER
symexec7.2 disabled - - /SymExec/SymExec72
symping7.2 disabled - - /SymTesting/Symping72
2. 部署一个Python application,实现蒙特•卡罗的Server端:
[root@docker sym]# soamview app LoggingPython
APPLICATION STATUS SSM HOST SSM PID CONSUMER
LoggingP 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









