







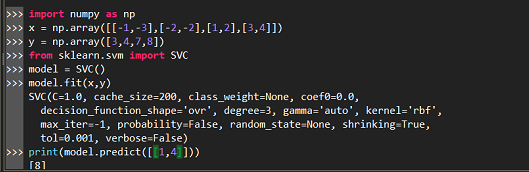
1.SVM二分类
2.SVM多分类(一对多)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
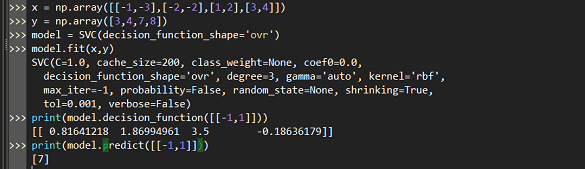
model.predict(x) 预测是类别的label值。
model.decision_function(x) 返回的是样本到超平面的距离。
优点:训练k个分类器,个数较少,其分类速度相对较快。
缺点:
(1)每个分类器的训练都是将全部的样本作为训练样本,这样在求解二次规划问题时,训练速度会随着训练样本的数量的增加而急剧减慢;
(2)同时由于负类样本的数据要远远大于正类样本的数据,从而出现了样本不对称的情况,且这种情况随着训练数据的增加而趋向严重。解决不对称的问题可以引入不同的惩罚因子,对样本点来说较少的正类采用较大的惩罚因子C;
(3)还有就是当有新的类别加进来时,需要对所有的模型进行重新训练。
3.SVM多分类(一对一)
其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
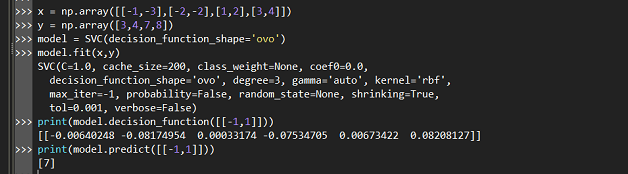
构造的分类器:(3,4)(3,7)(3,8)(4,7)(4,8)(7,8)
预测的类别:[4,7,3,7,4,7]
得票最多的类别是:7
优点:不需要重新训练所有的SVM,只需要重新训练和增加与样本相关的分类器。在训练单个模型时,相对速度较快。
缺点:所需构造和测试的二值分类器的数量关于k成二次函数增长,总训练时间和测试时间相对较慢。















 7775
7775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









