







前言
本文将总结扩散模型DDPM的原理,首先介绍DDPM的基本流程,接着展开介绍流程里的细节,最后针对DDPM的优化函数进行推导,以让读者明白DDPM参数估计的原理。
本文不会对扩散模型的motivation进行讲解,作者有点鬼才,完全想不到他是怎么想出这种训练范式的
生成式模型的代表作为GAN,然而,GAN的训练十分困难,对抗训练稍有不慎便会陷入模式坍塌(model collapse)。在此背景下产生了Diffusion Model,其具备训练简单,生成图像多样化的特点,DDPM便是其中的代表作。
以下推导如有错误,欢迎指出
DDPM的基本流程
DDPM分为前向过程与逆向过程。
前向过程
前向过程发生在训练时:
- 从均匀分布Uniform(1,2,3…,T)中采样一个样本 t t t。
- 对一张图像 x 0 x_0 x0添加 t t t次从标准正态分布 N ( 0 , I ) \mathcal N(0,\mathcal I) N(0,I)中采样到的高斯噪声( ϵ 1 \epsilon_1 ϵ1、 ϵ 2 \epsilon_2 ϵ2、…、 ϵ t \epsilon_t ϵt),得到噪声图像 x t x_t xt。
- x t x_t xt输入到U-Net结构的网络,网络的输出将拟合添加到 x 0 x_0 x0中的噪声 ϵ \epsilon ϵ。
在DDPM中,神经网络扮演的角色为预测添加到图像 x 0 x_0 x0中的噪声(其实本质是预测马尔科夫状态链中 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)的均值)。当 t t t足够大时,即 t = T t=T t=T时, x T x_T xT为将服从标准正态分布。
反向过程
反向过程发生在推断时:
- 从标准正态分布 N ( 0 , I ) \mathcal N(0,\mathcal I) N(0,I)中采样一个"噪声图像" x T x_T xT。
- 将 x T x_T xT输入到U-Net结构的网络中,网络输出高斯噪声 ϵ T \epsilon_T ϵT。
- 从标准正态分布 N ( 0 , I ) \mathcal N(0,\mathcal I) N(0,I)中采样得到 z z z
- 利用噪声图像 x T x_T xT 、 ϵ T \epsilon_T ϵT、 z z z,依据重参数化公式得到(采样)图像 x T − 1 x_{T-1} xT−1,重参数化公式可看下一章节中的Sampling。
- 重复上述过程 T T T次,即可生成图像 x 0 x_0 x0。
DDPM训练与测试伪代码

上图中的
ϵ
θ
\epsilon_\theta
ϵθ即神经网络。
从前向过程和反向过程可以看出DDPM的训练和推断过程都需要耗费大量的计算资源。后续的DDIM有效降低了推断过程所需的计算资源,而stable diffsuion 则同时降低了训练和推断过程中所需的计算资源。后续的博客将对两者进行总结
后续内容将延续上述符号定义
在详细介绍前向过程和反向过程前,我们需要知道DDPM将图像生成看成一种马尔科夫链,即
x
t
x_t
xt的生成仅依赖于
x
t
−
1
x_{t-1}
xt−1或
x
t
+
1
x_{t+1}
xt+1,则前向过程(虚线)和反向过(实线)程可以表示为下图
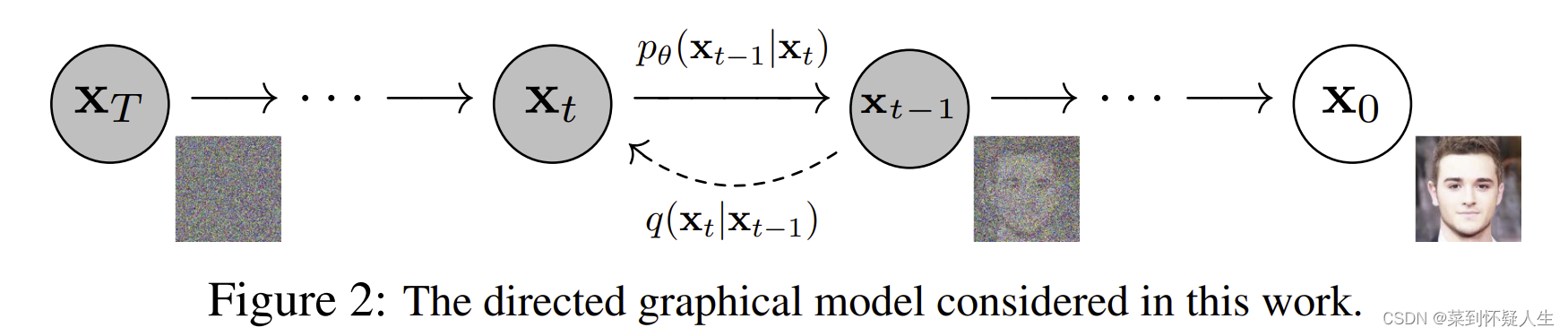
为了书写方便,除非特殊提及,在以下的所有推导中,所有的 x x x、 ϵ \epsilon ϵ符号都表示随机变量,而不是一个样本。
前向过程详解
依据马尔科夫链的特性,在前向过程中,定义
x
t
x_t
xt可从
x
t
−
1
x_{t-1}
xt−1中按下式得到:
x
t
=
1
−
β
t
x
t
−
1
+
β
t
ϵ
t
(1.0)
x_t=\sqrt{1-\beta_t} x_{t-1}+\sqrt{\beta_t} \epsilon_{t}\tag{1.0}
xt=1−βtxt−1+βtϵt(1.0)
β
t
\beta_t
βt是一个人为设定的常数,取值为(0,1)。其满足以下特性
β
1
<
β
2
<
.
.
.
<
β
T
\beta_1<\beta_2<...<\beta_T
β1<β2<...<βT
从式1.0可知 x t x_t xt的生成仅仅依赖 x t − 1 x_{t-1} xt−1,与 x 0 x_0 x0无关,因此有 x t ∼ q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) (1.1) x_t\sim q(x_t|x_{t-1})=\mathcal N(x_t;\sqrt{1-\beta_t} x_{t-1},\beta_t \mathcal I)\tag{1.1} xt∼q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(1.1)
利用重参数化的技巧,从式1.0中的形式可以得出式1.1。
重参数化: X ∼ N ( 0 , I ) X\sim \mathcal N(0,\mathcal I) X∼N(0,I),则 μ + δ X ∼ N ( μ , δ 2 ) \mu +\delta X \sim N(\mu,\delta^2) μ+δX∼N(μ,δ2)
前向过程需要对式1.0重复t次,非常耗时,能否仅采样一次,就得到状态t时刻的样本呢?
为了实现上述想法,我们需要得到分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)的具体形式,
为了后续推导出的式子更加简洁,设
α
t
=
1
−
β
t
α
ˉ
t
=
α
t
α
t
−
1
.
.
.
α
0
\begin{aligned} \alpha_t&=1-\beta_t\\ \bar \alpha_t & = \alpha_t\alpha_{t-1}...\alpha_0 \end{aligned}
αtαˉt=1−βt=αtαt−1...α0对式1.0进行展开可得
x
t
=
1
−
β
t
x
t
−
1
+
β
t
ϵ
t
=
1
−
β
t
(
1
−
β
t
−
1
x
t
−
2
+
β
t
−
1
ϵ
t
−
1
)
+
β
t
ϵ
t
=
α
t
(
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
ϵ
t
−
1
)
+
1
−
α
t
ϵ
t
=
α
t
α
t
−
1
x
t
−
2
+
α
t
(
1
−
α
t
−
1
)
ϵ
t
−
1
+
1
−
α
t
ϵ
t
=
α
t
α
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
ϵ
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
t
(1.2)
\begin{aligned} x_t&=\sqrt{1-\beta_t} x_{t-1}+\sqrt{\beta_t} \epsilon_{t}\\ &=\sqrt{1-\beta_t} (\sqrt{1-\beta_{t-1}}x_{t-2}+\sqrt{\beta_{t-1}}\epsilon_{t-1})+\sqrt{\beta_t} \epsilon_{t}\\ &=\sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}\epsilon_{t-1})+\sqrt{1-\alpha_t}\epsilon_t\\ &=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}+\sqrt{1-\alpha_t}\epsilon_t\\ &=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}\epsilon_{t}\\ &=\sqrt{\bar \alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon_t\tag{1.2} \end{aligned}
xt=1−βtxt−1+βtϵt=1−βt(1−βt−1xt−2+βt−1ϵt−1)+βtϵt=αt(αt−1xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1xt−2+αt(1−αt−1)ϵt−1+1−αtϵt=αtαt−1xt−2+1−αtαt−1ϵt=αˉtx0+1−αˉtϵt(1.2)
上述等式的倒数第二行推导逻辑如下,已知
ϵ
t
\epsilon_{t}
ϵt、
ϵ
t
−
1
\epsilon_{t-1}
ϵt−1服从标准正态分布,依据重参数化可知:
α
t
(
1
−
α
t
−
1
)
ϵ
t
−
1
∼
N
(
0
,
α
t
(
1
−
α
t
−
1
)
)
1
−
α
t
ϵ
t
∼
N
(
0
,
1
−
α
t
)
\begin{aligned} \sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}&\sim \mathcal N(0,\alpha_t(1-\alpha_{t-1}))\\ \sqrt{1-\alpha_{t}}\epsilon_{t}&\sim \mathcal N(0,1-\alpha_{t}) \end{aligned}
αt(1−αt−1)ϵt−11−αtϵt∼N(0,αt(1−αt−1))∼N(0,1−αt)
两个均值为0的高斯分布相加具备以下性质
N ( 0 , δ 1 2 ) + N ( 0 , δ 2 2 ) = N ( 0 , δ 1 2 + δ 2 2 ) \mathcal N(0,\delta_1^2)+\mathcal N(0,\delta_2^2)=\mathcal N(0,\delta_1^2+\delta_2^2) N(0,δ12)+N(0,δ22)=N(0,δ12+δ22)
则有
α
t
(
1
−
α
t
−
1
)
ϵ
t
−
1
+
1
−
α
t
ϵ
t
∼
N
(
0
,
1
−
α
t
)
+
N
(
0
,
α
t
(
1
−
α
t
−
1
)
)
=
N
(
0
,
1
−
α
t
α
t
−
1
)
\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}+\sqrt{1-\alpha_t}\epsilon_t \sim \mathcal N(0,1-\alpha_{t})+ \mathcal N(0,\alpha_t(1-\alpha_{t-1}))=\mathcal N(0,1-\alpha_{t}\alpha_{t-1})
αt(1−αt−1)ϵt−1+1−αtϵt∼N(0,1−αt)+N(0,αt(1−αt−1))=N(0,1−αtαt−1)
因此我们可以利用分布
N
(
0
,
1
−
α
t
α
t
−
1
)
\mathcal N(0,1-\alpha_{t}\alpha_{t-1})
N(0,1−αtαt−1)中的随机变量来替代
α
t
(
1
−
α
t
−
1
)
ϵ
t
−
1
+
1
−
α
t
ϵ
t
\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}+\sqrt{1-\alpha_t}\epsilon_t
αt(1−αt−1)ϵt−1+1−αtϵt,利用重参数化技巧推出式1.3
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
ˉ
t
x
0
,
(
1
−
α
ˉ
t
)
I
)
(1.3)
q(x_t|x_0)=\mathcal N(x_t;\sqrt{\bar \alpha_t}x_0,(1-\bar\alpha_t)\mathcal I)\tag{1.3}
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)(1.3)
利用式1.2,我们可以仅通过一次采样就能获得状态 t t t时刻的样本。
反向过程详解
依据马尔科夫链的性质,我们需要得到分布
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt)的具体形式,进而通过重参数化技巧进行采样。对其展开可得
q
(
x
t
−
1
∣
x
t
)
=
q
(
x
t
−
1
x
t
)
q
(
x
t
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
)
q
(
x
t
)
\begin{aligned} q(x_{t-1}|x_{t})&=\frac{q(x_{t-1}x_t)}{q(x_t)}\\ &=\frac{q(x_t|x_{t-1})q(x_{t-1})}{q(x_t)} \end{aligned}
q(xt−1∣xt)=q(xt)q(xt−1xt)=q(xt)q(xt∣xt−1)q(xt−1)
我们无法知晓
q
(
x
t
−
1
)
q(x_{t-1})
q(xt−1)、
q
(
x
t
)
q(x_t)
q(xt)的具体分布形式,因此
q
(
x
t
−
1
∣
x
x
t
)
q(x_{t-1}|x_{x_t})
q(xt−1∣xxt)是intractable的。作者在此用了一个trick,在反向过程的马尔可夫链中,随机变量
x
t
−
1
x_{t-1}
xt−1仅仅依赖于
x
t
x_t
xt,不依赖于
x
0
x_0
x0,利用这个特性,我们有
q
(
x
t
−
1
∣
x
t
)
=
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
−
1
,
x
t
,
x
0
)
q
(
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
,
x
0
)
q
(
x
t
∣
x
0
)
q
(
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
0
)
q
(
x
t
∣
x
0
)
q
(
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
(2.0)
\begin{aligned} q(x_{t-1}|x_{t})&=q(x_{t-1}|x_{t},x_0)\\ &=\frac{q(x_{t-1},x_t,x_0)}{q(x_t,x_0)}\\ &=\frac{q(x_{t}|x_{t-1},x_0)q(x_{t-1},x_0)}{q(x_t|x_0)q(x_0)}\\ &=\frac{q(x_{t}|x_{t-1},x_0)q(x_{t-1}|x_0)q(x_0)}{q(x_t|x_0)q(x_0)}\\ &=\frac{q(x_{t}|x_{t-1},x_0)q(x_{t-1}|x_0)}{q(x_t|x_0)}\\ &=\frac{q(x_{t}|x_{t-1})q(x_{t-1}|x_0)}{q(x_t|x_0)}\tag{2.0} \end{aligned}
q(xt−1∣xt)=q(xt−1∣xt,x0)=q(xt,x0)q(xt−1,xt,x0)=q(xt∣x0)q(x0)q(xt∣xt−1,x0)q(xt−1,x0)=q(xt∣x0)q(x0)q(xt∣xt−1,x0)q(xt−1∣x0)q(x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)(2.0)
结合式1.1、1.3,利用高斯分布的具体表达式,对式2.0(忽略高斯分布的系数)进行进一步推导有
q ( x t − 1 ∣ x t ) = exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) (2.1) \begin{aligned} q(x_{t-1}|x_t)&=\exp(-\frac{1}{2}(\frac{(x_t-\sqrt{\alpha_t}x_{t-1})^2}{\beta_t}+\frac{(x_{t-1}-\sqrt{\bar\alpha_{t-1}}x_0)^2}{1-\bar\alpha_{t-1}}-\frac{(x_t-\sqrt{\bar\alpha_t}x_0)^2}{1-\bar \alpha_t}))\\ &=\exp(-\frac{1}{2}(\frac{x_t^2-2\sqrt{\alpha_t}x_tx_{t-1}+\alpha_tx_{t-1}^2}{\beta_t}+\frac{x_{t-1}^2-2\sqrt{\bar\alpha_{t-1}}x_0x_{t-1}+\bar\alpha_{t-1}x_0^2}{1-\bar\alpha_{t-1}}-\frac{(x_t-\sqrt{\bar\alpha_t}x_0)^2}{1-\bar \alpha_t}))\\ &=\exp(-\frac{1}{2}((\frac{\alpha_t}{\beta_t}+\frac{1}{1-\alpha_{t-1}})x_{t-1}^2-(\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\bar\alpha_{t-1}}}{1-\bar\alpha_{t-1}}x_0)x_{t-1}+C(x_t,x_0)))\tag{2.1} \end{aligned} q(xt−1∣xt)=exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))(2.1)
等式的最后一列就是合并同类项,不包含 x t − 1 x_{t-1} xt−1的项都合并到了 C ( x t , x 0 ) C(x_t,x_0) C(xt,x0)中,我们对高斯分布的展开形式做个回顾:
N ( μ , δ 2 ) = 1 2 π δ exp ( − ( x − μ ) 2 2 δ 2 ) = 1 2 π δ exp ( − ( 1 2 δ 2 x 2 − μ δ 2 x + μ 2 δ 2 ) ) \begin{aligned} \mathcal N(\mu,\delta^2)&=\frac{1}{\sqrt{2\pi}\delta}\exp(-\frac{(x-\mu)^2}{2\delta^2})\\ &=\frac{1}{\sqrt{2\pi}\delta}\exp(-(\frac{1}{2\delta^2}x^2-\frac{\mu}{\delta^2}x+\frac{\mu^2}{\delta^2})) \end{aligned} N(μ,δ2)=2πδ1exp(−2δ2(x−μ)2)=2πδ1exp(−(2δ21x2−δ2μx+δ2μ2))
依据上述展开,以及
α
ˉ
t
=
α
t
α
t
−
1
.
.
.
α
0
\bar \alpha_t = \alpha_t\alpha_{t-1}...\alpha_0
αˉt=αtαt−1...α0、
α
t
=
1
−
β
t
\alpha_t=1-\beta_t
αt=1−βt,
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
t
x_t=\sqrt{\bar \alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon_t
xt=αˉtx0+1−αˉtϵt,我们对式2.1进行补齐缺失项后可得
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_t)
q(xt−1∣xt)的均值
μ
t
\mu_t
μt和方差
δ
t
2
\delta_t^2
δt2为
δ
t
2
=
1
α
t
β
t
+
1
1
−
α
t
−
1
=
1
α
t
−
α
ˉ
t
+
β
t
β
t
(
1
−
α
ˉ
t
−
1
)
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
μ
t
=
(
2
α
t
β
t
x
t
+
2
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
/
(
α
t
β
t
+
1
1
−
α
t
−
1
)
=
(
2
α
t
β
t
x
t
+
2
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
x
0
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
ϵ
t
α
ˉ
t
)
=
1
α
t
(
x
t
−
1
−
α
t
1
−
α
ˉ
t
ϵ
t
)
(2.2)
\begin{aligned} \delta_t^2&=\frac{1}{\frac{\alpha_t}{\beta_t}+\frac{1}{1-\alpha_{t-1}}}=\frac{1}{\frac{\alpha_t-\bar\alpha_t+\beta_t}{\beta_t(1-\bar\alpha_{t-1})}}=\frac{1-\bar\alpha_{t-1}}{1-\bar\alpha_t}\beta_t\\ \mu_t&=(\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\bar\alpha_{t-1}}}{1-\bar\alpha_{t-1}}x_0)/(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\alpha_{t-1}})\\ &=(\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\bar\alpha_{t-1}}}{1-\bar\alpha_{t-1}}x_0)\frac{1-\bar\alpha_{t-1}}{1-\bar\alpha_t}\beta_t\\ &=\frac{\sqrt{\alpha_t}(1-\bar\alpha_{t-1})}{1-\bar\alpha_t}x_t+\frac{\sqrt{\bar\alpha_{t-1}}\beta_t}{1-\bar\alpha_t}x_0\\ &=\frac{\sqrt{\alpha_t}(1-\bar\alpha_{t-1})}{1-\bar\alpha_t}x_t+\frac{\sqrt{\bar\alpha_{t-1}}\beta_t}{1-\bar\alpha_t}(\frac{x_t-\sqrt{1-\bar\alpha_t}\epsilon_t}{\sqrt{\bar\alpha_t}})\\ &=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar\alpha_t}}\epsilon_t) \end{aligned}\tag{2.2}
δt2μt=βtαt+1−αt−111=βt(1−αˉt−1)αt−αˉt+βt1=1−αˉt1−αˉt−1βt=(βt2αtxt+1−αˉt−12αˉt−1x0)/(βtαt+1−αt−11)=(βt2αtxt+1−αˉt−12αˉt−1x0)1−αˉt1−αˉt−1βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βt(αˉtxt−1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)(2.2)
上式中的
ϵ
t
\epsilon_t
ϵt可以由神经网络预测得到(可回顾“DDPM基本流程章节”)。依据式2.2,利用重参数化从样本
x
t
x_t
xt得到样本
x
t
−
1
x_{t-1}
xt−1的流程为
- 从 N ( 0 , I ) \mathcal N(0,\mathcal I) N(0,I)采样得到 z z z
- 将 x t x_t xt输入到网络中,由网络预测 ϵ t \epsilon_t ϵt
- x t − 1 x_{t-1} xt−1= 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) + δ t z \frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar\alpha_t}}\epsilon_t)+\delta_tz αt1(xt−1−αˉt1−αtϵt)+δtz
DDPM损失函数推导
至此,我们已经对前向过程与反向过程进行了详细的介绍,也知晓神经网络在DDPM中扮演的角色为预测最后一次添加到图像中的噪声,自然也能推断出DDPM的损失函数类似于MSE。在本章节中,博主将推导DDPM的损失函数。
深度学习领域的许多模型都通过极大化对数似然来进行参数估计,设网络为 p θ ( x 0 ) p_\theta(x_0) pθ(x0),则对数似然为 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0),最大化对数似然等价于最小化 − log p θ ( x 0 ) -\log p_\theta(x_0) −logpθ(x0),DDPM通过优化其上界进行参数估计。已知KL散度取值大于等于0,则其上界为( q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0)表示真实的数据分布)
−
log
p
θ
(
x
0
)
≤
−
log
p
θ
(
x
0
)
+
D
K
L
(
q
(
x
1
:
T
∣
x
0
)
∣
∣
p
θ
(
x
1
:
T
∣
x
0
)
)
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
/
p
θ
(
x
0
)
]
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
+
log
p
θ
(
x
0
)
]
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
p
θ
(
x
0
)
]
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
+
log
p
θ
(
x
0
)
=
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
\begin{aligned} -\log p_\theta(x_0) &\leq -\log p_\theta(x_0)+D_{KL}(q(x_{1:T}|x_0)||p_{\theta}(x_{1:T}|x_0))\\ &=-\log p_\theta(x_0)+E_{q(x_{1:T}|x_0)}[\log\frac{q(x_{1:T}|x_0)}{p_{\theta}(x_{0:T})/p_{\theta}(x_0)}]\\ &=-\log p_\theta(x_0)+E_{q(x_{1:T}|x_0)}[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}+\log p_{\theta}(x_0)]\\ &=-\log p_\theta(x_0)+E_{q(x_{1:T}|x_0)}[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}]+E_{q(x_{1:T}|x_0)}[\log p_{\theta}(x_0)]\\ &=-\log p_\theta(x_0)+E_{q(x_{1:T}|x_0)}[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}]+\log p_{\theta}(x_0)\\ &=E_{q(x_{1:T}|x_0)}[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}] \end{aligned}
−logpθ(x0)≤−logpθ(x0)+DKL(q(x1:T∣x0)∣∣pθ(x1:T∣x0))=−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)]+Eq(x1:T∣x0)[logpθ(x0)]=−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)]+logpθ(x0)=Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)]
对其展开则有
L
=
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
=
E
q
[
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
1
T
log
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
(
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
.
q
(
x
t
∣
x
0
)
q
(
x
t
−
1
∣
x
0
)
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
0
)
q
(
x
t
−
1
∣
x
0
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
T
∣
x
0
)
q
(
x
1
∣
x
0
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
T
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
)
]
=
E
q
[
log
q
(
x
T
∣
x
0
)
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
−
log
p
θ
(
x
0
∣
x
1
)
)
]
=
E
q
[
D
K
L
(
q
(
x
T
∣
x
0
)
∣
∣
p
θ
(
x
T
)
)
q
(
x
T
∣
x
0
)
+
∑
t
=
2
T
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
q
(
x
t
−
1
∣
x
t
,
x
0
)
−
log
p
θ
(
x
0
∣
x
1
)
)
]
\begin{aligned} L&=E_{q(x_{1:T}|x_0)}[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}]\\ &=E_q[\frac{\prod_{t=1}^Tq(x_t|x_{t-1})}{p_{\theta}(x_T)\prod_{t=1}^Tp_\theta(x_{t-1}|x_t)}]\\ &=E_q[-\log p_\theta(x_T)+\sum_{t=1}^T\log\frac{q(x_t|x_{t-1})}{p_\theta(x_{t-1}|x_t)}]\\ &=E_q[-\log p_\theta(x_T)+\sum_{t=2}^T\log\frac{q(x_t|x_{t-1})}{p_\theta(x_{t-1}|x_t)}+\log\frac{q(x_1|x_0)}{p_\theta(x_0|x_1)}]\\ &=E_q[-\log p_\theta(x_T)+\sum_{t=2}^T\log(\frac{q(x_t|x_{t-1},x_0)}{p_\theta(x_{t-1}|x_t)}.\frac{q(x_t|x_0)}{q(x_{t-1}|x_0)})+\log\frac{q(x_1|x_0)}{p_\theta(x_0|x_1)}]\\ &=E_q[-\log p_\theta(x_T)+\sum_{t=2}^T\log\frac{q(x_t|x_{t-1},x_0)}{p_\theta(x_{t-1}|x_t)}+\sum_{t=2}^T\log\frac{q(x_t|x_0)}{q(x_{t-1}|x_0)}+\log\frac{q(x_1|x_0)}{p_\theta(x_0|x_1)}]\\ &=E_q[-\log p_\theta(x_T)+\sum_{t=2}^T\log\frac{q(x_t|x_{t-1},x_0)}{p_\theta(x_{t-1}|x_t)}+\log\frac{q(x_T|x_0)}{q(x_{1}|x_0)}+\log\frac{q(x_1|x_0)}{p_\theta(x_0|x_1)}]\\ &=E_q[-\log p_\theta(x_T)+\sum_{t=2}^T\log\frac{q(x_t|x_{t-1},x_0)}{p_\theta(x_{t-1}|x_t)}+\log\frac{q(x_T|x_0)}{p_\theta(x_0|x_1))}]\\ &=E_q[\log \frac{q(x_T|x_0)}{p_\theta(x_T)}+\sum_{t=2}^T\log\frac{q(x_t|x_{t-1},x_0)}{p_\theta(x_{t-1}|x_t)}-\log{p_\theta(x_0|x_1))}]\\ &=E_q[\frac{D_{KL}(q(x_T|x_0)||p_\theta(x_T))}{q(x_T|x_0)}+\sum_{t=2}^T\frac{D_{KL}(q(x_{t-1}|x_t,x_0)||p_\theta(x_{t-1}|x_t))}{q(x_{t-1}|x_t,x_0)}-\log{p_\theta(x_0|x_1))}] \end{aligned}
L=Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)]=Eq[pθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt∣xt−1,x0).q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)+logpθ(x0∣x1))q(xT∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)−logpθ(x0∣x1))]=Eq[q(xT∣x0)DKL(q(xT∣x0)∣∣pθ(xT))+t=2∑Tq(xt−1∣xt,x0)DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))−logpθ(x0∣x1))]
因此需要优化的项有三个
L
0
=
D
K
L
(
q
(
x
T
∣
x
0
)
∣
∣
p
θ
(
x
T
)
)
L
1
=
∑
t
=
2
T
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
L
2
=
log
p
θ
(
x
0
∣
x
1
)
\begin{aligned} L_0&=D_{KL}(q(x_T|x_0)||p_\theta(x_T))\\ L_1&=\sum_{t=2}^TD_{KL}(q(x_{t-1}|x_t,x_0)||p_\theta(x_{t-1}|x_t))\\ L_2&=\log{p_\theta(x_0|x_1)} \end{aligned}
L0L1L2=DKL(q(xT∣x0)∣∣pθ(xT))=t=2∑TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))=logpθ(x0∣x1)
对于 L 0 L_0 L0项,经过 T T T次( T T T一般很大)加噪后, q ( x T ∣ x 0 ) q(x_T|x_0) q(xT∣x0)与 p θ ( x T ) p_\theta(x_T) pθ(xT)基本等价于标准正态分布,因此 L 0 L_0 L0项取值接近于0。
对于
L
2
L_2
L2,感兴趣的可以浏览原文的3.3章节(具体实现见链接),最终作者发现优化
L
1
L_1
L1项,模型的效果最佳,因此本章节只对
L
1
L_1
L1进行推导。已知高斯分布
N
(
x
;
μ
1
,
∑
1
)
\mathcal N(x;\mu_1,\sum_1)
N(x;μ1,∑1)、
N
(
x
;
μ
2
,
∑
2
)
\mathcal N(x;\mu_2,\sum_2)
N(x;μ2,∑2)的KL散度公式为(具体推导可浏览生成模型VAE):
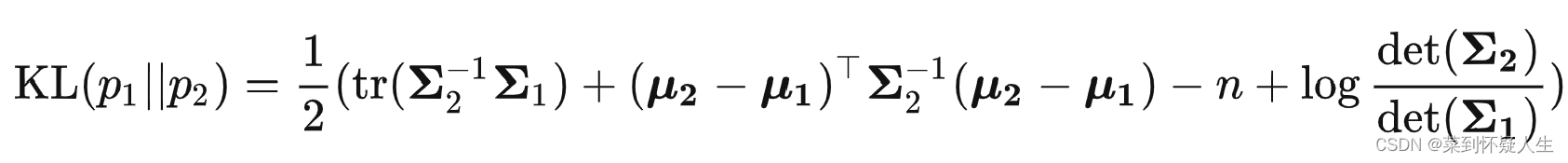
假设
p
θ
(
x
t
−
1
∣
x
t
)
p_\theta(x_{t-1}|x_t)
pθ(xt−1∣xt)服从
N
(
x
;
μ
θ
,
δ
t
I
)
\mathcal N(x;\mu_\theta,\delta_tI)
N(x;μθ,δtI),已知
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0)服从
N
(
x
;
μ
t
,
δ
t
I
)
\mathcal N(x;\mu_t,\delta_tI)
N(x;μt,δtI)(均值和方差的式子见式2.2),则有
L
2
=
∑
t
=
2
T
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
=
∑
t
=
2
T
(
1
2
(
n
+
1
δ
t
2
∣
∣
μ
t
−
μ
θ
∣
∣
2
−
n
+
l
o
g
1
)
=
∑
t
=
2
T
(
1
2
δ
t
2
∣
∣
μ
t
−
μ
θ
∣
∣
2
)
\begin{aligned} L_2&=\sum_{t=2}^TD_{KL}(q(x_{t-1}|x_t,x_0)||p_\theta(x_{t-1}|x_t))\\ &=\sum_{t=2}^T(\frac{1}{2}(n+\frac{1}{\delta_t^2}||\mu_t-\mu_\theta||^2-n+log1)\\ &=\sum_{t=2}^T(\frac{1}{2\delta_t^2}||\mu_t-\mu_\theta||^2)\\ \end{aligned}
L2=t=2∑TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))=t=2∑T(21(n+δt21∣∣μt−μθ∣∣2−n+log1)=t=2∑T(2δt21∣∣μt−μθ∣∣2)
则
μ
θ
\mu_\theta
μθ需要拟合
μ
t
\mu_t
μt,结合式2.2,
μ
θ
=
1
α
t
(
x
t
−
1
−
α
t
1
−
α
ˉ
t
ϵ
θ
(
x
t
)
)
\mu_\theta=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar\alpha_t}}\epsilon_\theta(x_t))
μθ=αt1(xt−1−αˉt1−αtϵθ(xt)),可得
L
2
=
∑
t
=
2
T
(
(
1
−
α
t
)
2
2
δ
t
2
α
t
(
1
−
α
ˉ
t
)
∣
∣
ϵ
t
−
ϵ
θ
(
x
t
)
∣
∣
2
)
L_2=\sum_{t=2}^T(\frac{(1-\alpha_t)^2}{2\delta_t^2\alpha_t(1-\bar\alpha_t)}||\epsilon_t-\epsilon_\theta(x_t)||^2)
L2=t=2∑T(2δt2αt(1−αˉt)(1−αt)2∣∣ϵt−ϵθ(xt)∣∣2)
结合式子1.2以及坐标下降法,可得DDPM最终优化目标
L
L
L为
L
=
∣
∣
ϵ
t
−
ϵ
θ
(
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
t
)
∣
∣
2
L=||\epsilon_t-\epsilon_\theta(\sqrt{\bar \alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon_t)||^2
L=∣∣ϵt−ϵθ(αˉtx0+1−αˉtϵt)∣∣2
结语
DDPM利用马尔科夫链建模图像生成的过程很巧妙,最终推导得到的式子也十分简单,确实是个很漂亮的工作


















 3041
3041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









