






参考图
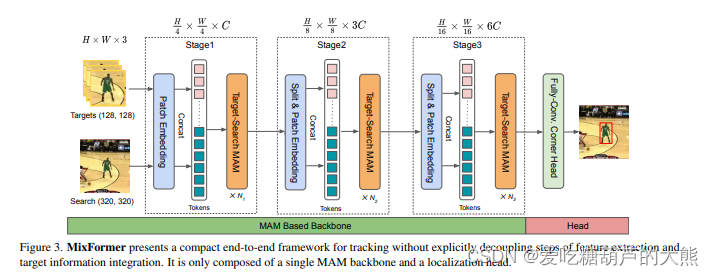
Stage1
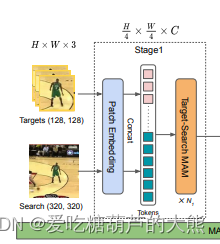
1、 输入:模板,在线模板,搜索三组图像
2、为每个输入添加位置编码
(实际上是nn.Conv2d( 通道3->64, 卷积核大小(7, 7), 步长(4, 4), 填充(2, 2))的卷积操作,然后归一化)
3、模板,在线模板和搜索做拼接(以组和通道做高宽,以原始的(w,h)拉伸作为拼接的通道)
4,然后进入block
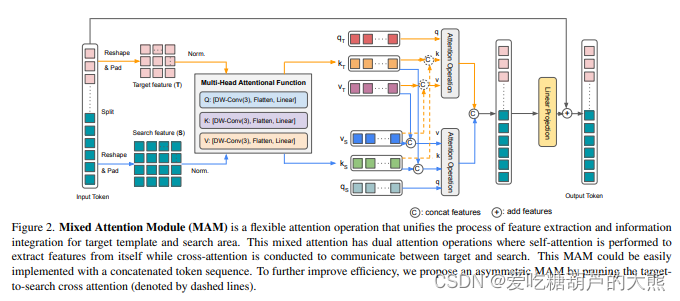
4.1、Norm归一化
4.2、进入Att模块
4.2.1、 生成q, k, v = self.forward_conv(x, t_h, t_w, s_h, s_w)
生成步骤是将模板在线模板通过一个卷积和归一化层,然后以(bach,(h*w),c)格式输出,其中k和v的尺寸是变小了的,将模板,在线模板和搜索的q,k,v以在h*w维度上拼接。然后再将q,k,v过一个线性层,然后将q,k,v分为模板+在线模板,搜索两组
4.2.2、transformer
模板进行transformer中的自注意力,搜索组以搜索部分的q和所有(包括模板,在线模板和搜索的k,v)做互注意力,然后再将两组重新拼接在一起,过个线性层
4.3,将所得的注意力结果与block的原始输入相加
4.4,这里还有个操作在论文中没有体现,就是最后的输出还过了一个MLP结构并和自身相加
5.然后将模板,在线模板,搜索图像分开
Stage2,Stage3
就是stage1的重复,但Stage2中block会重复4次,Stage3中block会重复16次
预测头
角位预测,giou,iou和L1作为损失
















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









