







 本文介绍了GoogLeNet的核心结构Inception模块,从V1到V4的演变,探讨了如何通过1x1卷积、批量归一化、卷积分解等方法降低模型复杂度并提高性能。Inception V4结合ResNet,进一步优化了网络性能。
本文介绍了GoogLeNet的核心结构Inception模块,从V1到V4的演变,探讨了如何通过1x1卷积、批量归一化、卷积分解等方法降低模型复杂度并提高性能。Inception V4结合ResNet,进一步优化了网络性能。
环境:Win8.1 TensorFlow1.0.1
软件:Anaconda3 (集成Python3及开发环境)
TensorFlow安装:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
TFLearn安装:pip install tflearn
参考:
1. Inception[V1]: Going Deeper with Convolutions
2. Inception[V2]: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
3. Inception[V3]: Rethinking the Inception Architecture for Computer Vision
4. Inception[V4]: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
1. 前言
上篇介绍的 NIN 在改造传统 CNN 结构上作出了瞩目贡献,通过 Mlpconv Layer 和 Global Average Pooling 建立的网络模型在多个数据集上取得了不错的结果,同时将训练参数控制在 AlexNet 参数量的 1/12。
本文将要介绍的是在 ILSVRC 2014 取得了最好的成绩的 GoogLeNet,及其核心结构—— Inception。早期的V1 结构借鉴了 NIN 的设计思路,对网络中的传统卷积层进行了修改,针对限制深度神经网络性能的主要问题,一直不断改进延伸到 V4:
- 参数空间大,容易过拟合,且训练数据集有限;
- 网络结构复杂,计算资源不足,导致难以应用;
- 深层次网络结构容易出现梯度弥散,模型性能下降。
2. Inception
GoogLeNet 对网络中的传统卷积层进行了修改,提出了被称为 Inception 的结构,用于增加网络深度和宽度,提高深度神经网络性能。
其各个版本的设计思路:
2.1 Inception V1

Naive Inception
Inception module 的提出主要考虑多个不同 size 的卷积核能够增强网络的适应力,paper 中分别使用1*1、3*3、5*5卷积核,同时加入3*3 max pooling。
随后文章指出这种 naive 结构存在着问题:每一层 Inception module 的 filters 参数量为所有分支上的总数和,多层 Inception 最终将导致 model 的参数数量庞大,对计算资源有更大的依赖。
在 NIN 模型中与1*1卷积层等效的 MLPConv 既能跨通道组织信息,提高网络的表达能力,同时可以对输出有效进行降维,因此文章提出了Inception module with dimension reduction,在不损失模型特征表示能力的前提下,尽量减少 filters 的数量,达到降低模型复杂度的目的:
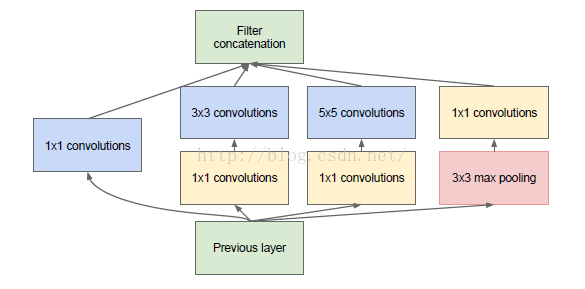
Inception Module
Inception Module 的4个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合,在 TensorFlow 中使用 tf.concat(3, [], []) 函数可以实现合并)。
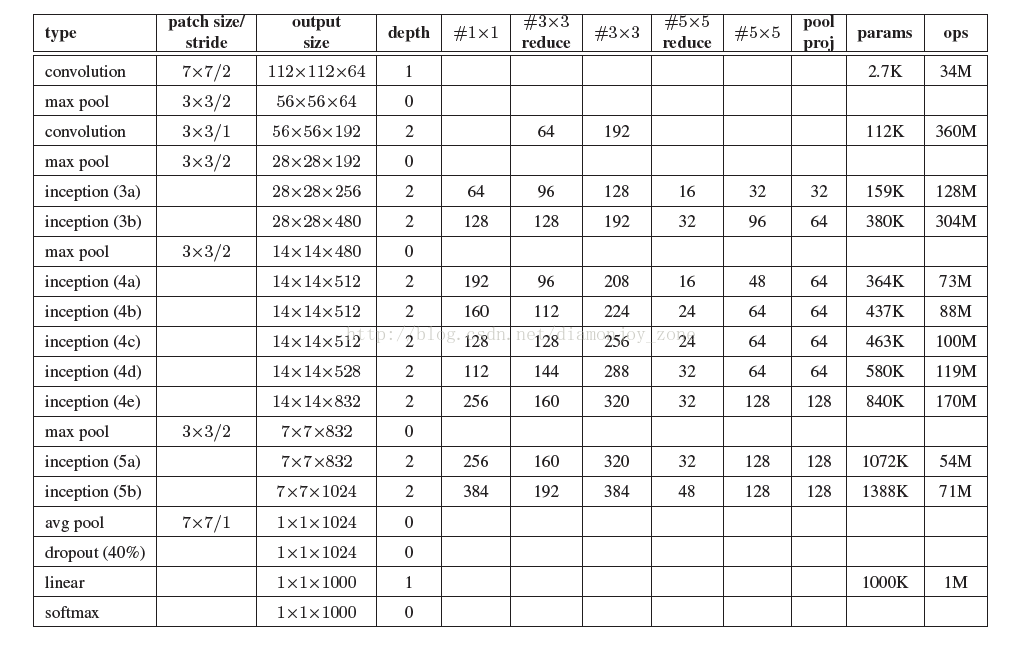
完整的 GoogLeNet 结构在传统的卷积层和池化层后面引入了 Inception 结构,对比 AlexNet 虽然网络层数增加,但是参数数量减少的原因是绝大部分的参数集中在全连接层,最终取得了 ImageNet 上 6.67% 的成绩。
2.2 Inception V2
Inception V2 学习了 VGG 用两个3´3的卷积代替5´5的大卷积,在降低参数的同时建立了更多的非线性变换,使得 CNN 对特征的学习能力更强:
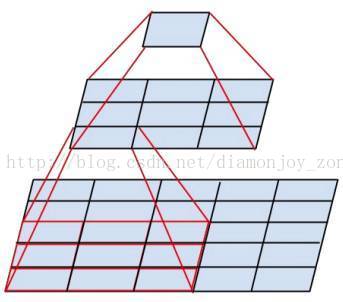
两个3´3的卷积层功能类似于一个5´5的卷积层
另外提出了著名的 Batch Normalization(以下简称BN)方法。BN 是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN 在用于神经网络某层时,会对每一个 mini-batch 数据的内部进行标准化(normalization)处理,使输出规范化到 N(0,1) 的正态分布,减少了 Internal Covariate Shift(内部神经元分布的改变)。
补充:在 TensorFlow 1.0.0 中采用 tf.image.per_image_standardization() 对图像进行标准化,旧版为 tf.image.per_image_whitening。
BN 的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用 BN 之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/14,训练时间大大缩短。而达到之前的准确率后,可以继续训练,并最终取得远超于 Inception V1 模型的性能—— top-5 错误率 4.8%,已经优于人眼水平。因为 BN 某种意义上还起到了正则化的作用,所以可以减少或者取消 Dropout 和 LRN,简化网络结构。
2.3 Inception V3
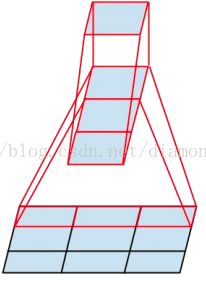


将一个3´3卷积拆成1´3卷积和3´1卷积
一是引入了 Factorization into small convolutions 的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7´7卷积拆成1´7卷积和7´1卷积,或者将3´3卷积拆成1´3卷积和3´1卷积,如上图所示。一方面节约了大量参数,加速运算并减轻了过拟合(比将7´7卷积拆成1´7卷积和7´1卷积,比拆成3个3´3卷积更节约参数),同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
另一方面,Inception V3 优化了 Inception Module 的结构,现在 Inception Module 有35´35、17´17和8´8三种不同结构。这些 Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3 除了在 Inception Module 中使用分支,还在分支中使用了分支(8´8的结构中),可以说是Network In Network In Network。最终取得 top-5 错误率 3.5%。
2.4 Inception V4
Inception V4 相比 V3 主要是结合了微软的 ResNet,将错误率进一步减少到 3.08%。
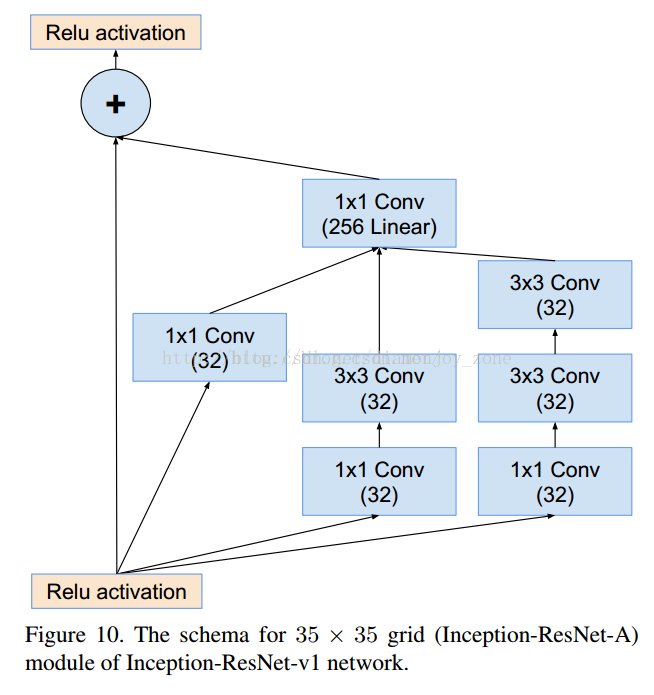
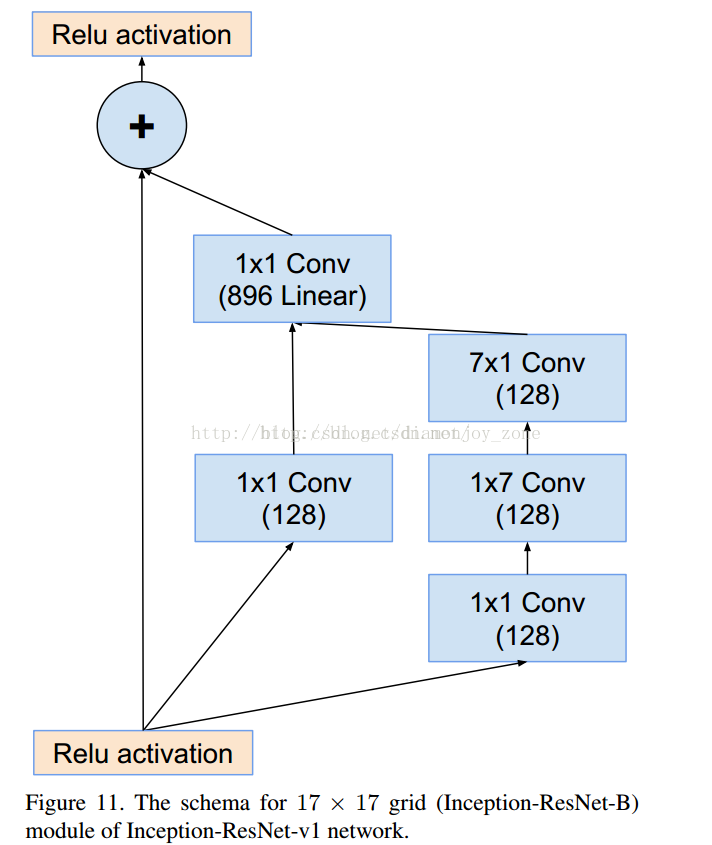
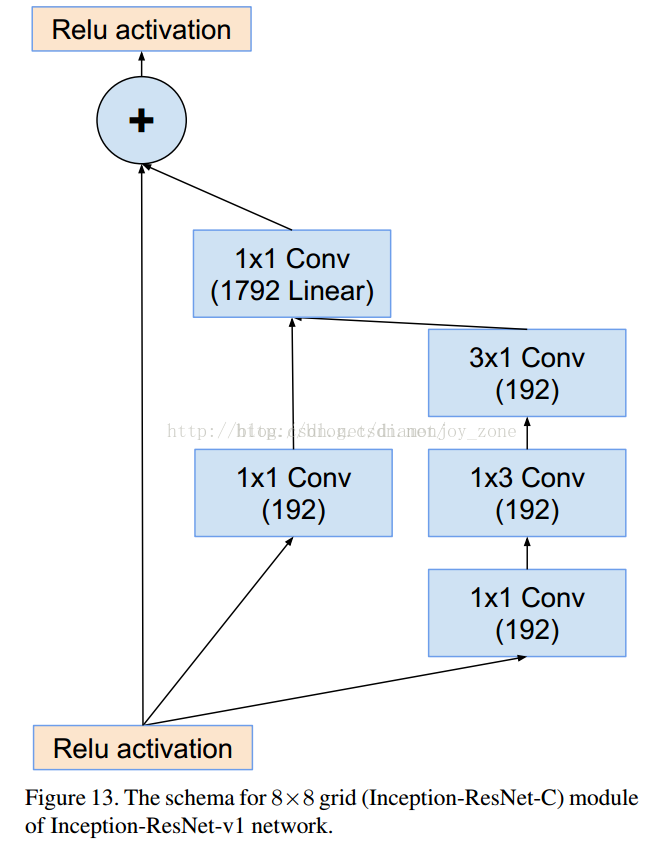
3. GoogLeNet V1
例如,在 tflearn 的 googlenet.py 中,定义 Inception(3a) 中的分支结构,用 merge 函数合并 feature map:
network = input_data(shape=[None, 227, 227, 3])
conv1_7_7 = conv_2d(network, 64, 7, strides=2, activation='relu', name = 'conv1_7_7_s2')
pool1_3_3 = max_pool_2d(conv1_7_7, 3,strides=2)
pool1_3_3 = local_response_normalization(pool1_3_3)
conv2_3_3_reduce = conv_2d(pool1_3_3, 64,1, activation='relu',name = 'conv2_3_3_reduce')
conv2_3_3 = conv_2d(conv2_3_3_reduce, 192,3, activation='relu', name='conv2_3_3')
conv2_3_3 = local_response_normalization(conv2_3_3)
pool2_3_3 = max_pool_2d(conv2_3_3, kernel_size=3, strides=2, name='pool2_3_3_s2')
inception_3a_1_1 = conv_2d(pool2_3_3, 64, 1, activation='relu', name='inception_3a_1_1')
inception_3a_3_3_reduce = conv_2d(pool2_3_3, 96,1, activation='relu', name='inception_3a_3_3_reduce')
inception_3a_3_3 = conv_2d(inception_3a_3_3_reduce, 128,filter_size=3, activation='relu', name = 'inception_3a_3_3')
inception_3a_5_5_reduce = conv_2d(pool2_3_3,16, filter_size=1,activation='relu', name ='inception_3a_5_5_reduce' )
inception_3a_5_5 = conv_2d(inception_3a_5_5_reduce, 32, filter_size=5, activation='relu', name= 'inception_3a_5_5')
inception_3a_pool = max_pool_2d(pool2_3_3, kernel_size=3, strides=1, )
inception_3a_pool_1_1 = conv_2d(inception_3a_pool, 32, filter_size=1, activation='relu', name='inception_3a_pool_1_1')
# merge the inception_3a__
inception_3a_output = merge([inception_3a_1_1, inception_3a_3_3, inception_3a_5_5, inception_3a_pool_1_1], mode='concat', axis=3)
最后对于 Inception(5b) 的7*7*1024的输出采用7*7的 avg pooling,40%的 Dropout 和 softmax:
pool5_7_7 = avg_pool_2d(inception_5b_output, kernel_size=7, strides=1)
pool5_7_7 = dropout(pool5_7_7, 0.4)
loss = fully_connected(pool5_7_7, 17,activation='softmax')由于解决 Oxford 17 类鲜花 数据集分类任务,最后的输出通道设为17。
4. 总结
Inception V1——构建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支网络,同时使用 MLPConv 和全局平均池化,扩宽卷积层网络宽度,增加了网络对尺度的适应性;
Inception V2——提出了 Batch Normalization,代替 Dropout 和 LRN,其正则化的效果让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高,同时学习 VGG 使用两个3´3的卷积核代替5´5的卷积核,在降低参数量同时提高网络学习能力;
Inception V3——引入了 Factorization,将一个较大的二维卷积拆成两个较小的一维卷积,比如将3´3卷积拆成1´3卷积和3´1卷积,一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力,除了在 Inception Module 中使用分支,还在分支中使用了分支(Network In Network In Network);
Inception V4——研究了 Inception Module 结合 Residual Connection,结合 ResNet 可以极大地加速训练,同时极大提升性能,在构建 Inception-ResNet 网络同时,还设计了一个更深更优化的 Inception v4 模型,能达到相媲美的性能。

















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









