







1. 索引类型
1.1 联合索引
多个字段组个成一个索引,使用时遵循最左原则。
联合索引的查询???
1.2单列索引
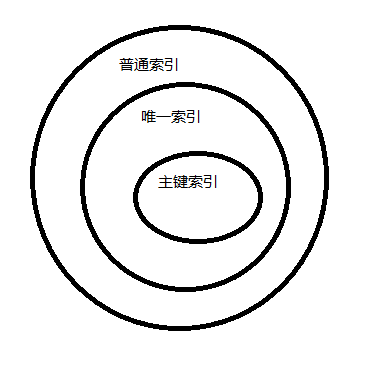
1.2.1 普通索引
可重复 空NULL
1.2.2唯一索引
不可重复 可有一个NULL
1.2.3主键索引
不可重复 不可NULL 没有定义自动选择一个索引作为主索引,没有符合条件的默认生成一个。
1.2.4全文索引
文本关键字查找
2. mysql数据落地文件形式
2.1MYISAM
- Frm:表的定义文件。
- MYD:数据文件,所有的数据保存在这个文件中。
- MYI:索引文件。
2.2INNODB
- Frm文件:表的定义文件。
- Ibd文件:数据和索引存储文件。数据以主键进行聚集存储,把真正的数据保存在叶子节点中。
3.索引数据结构
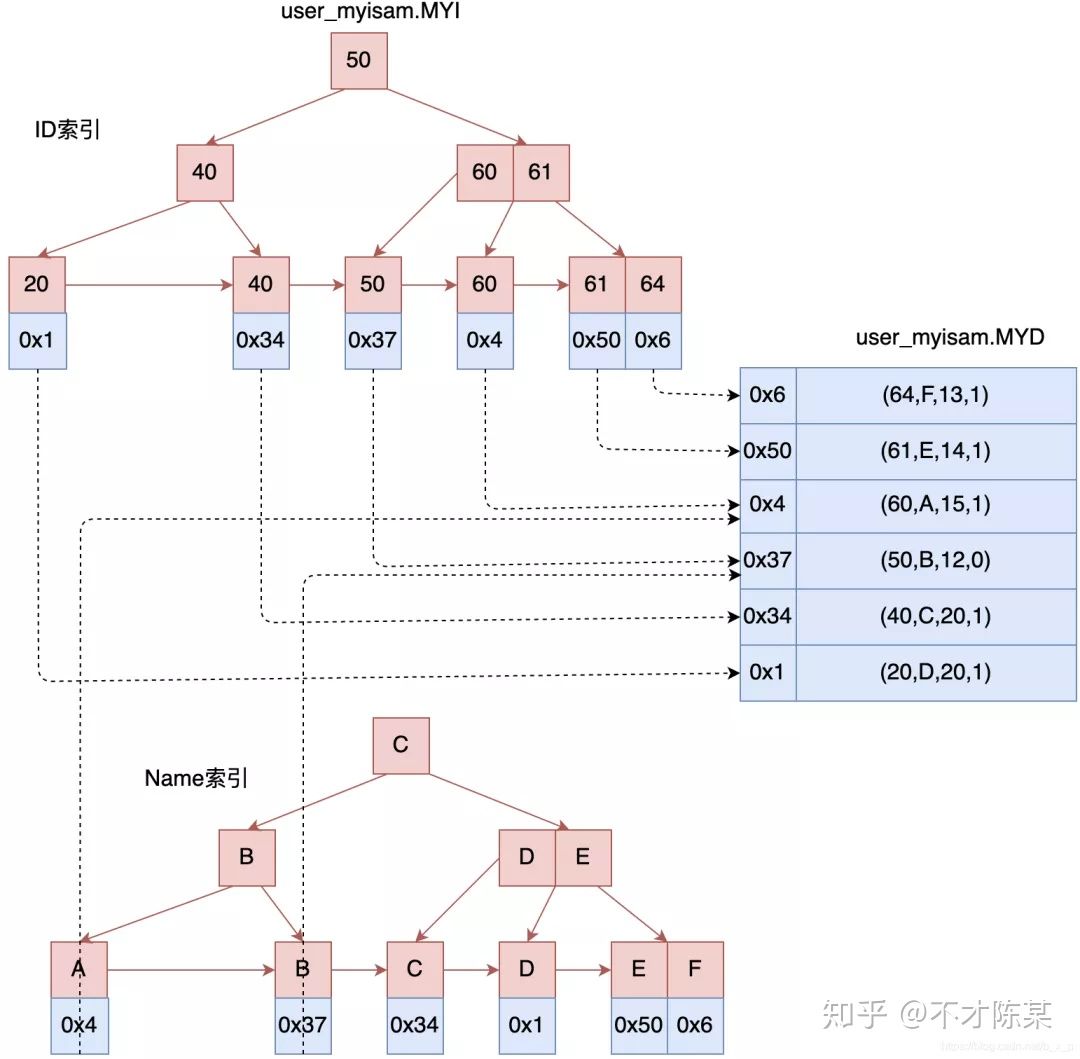
3.1myisam
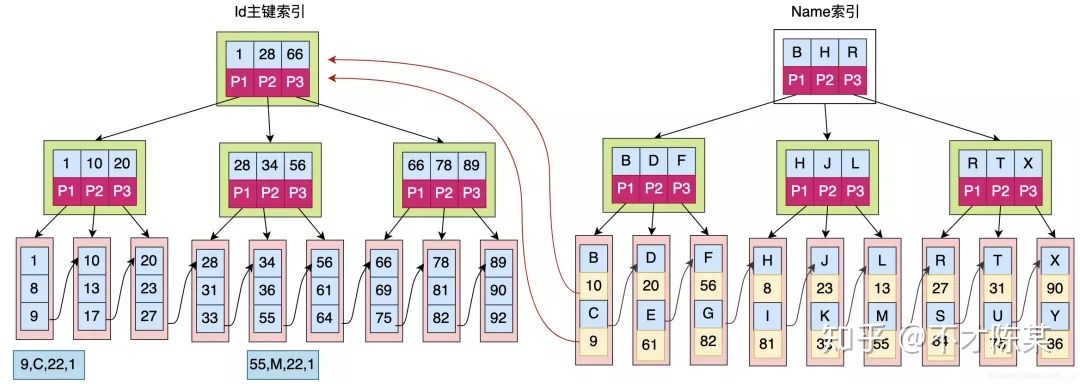
3.2innodb
3.3myisam 与 innodb比较
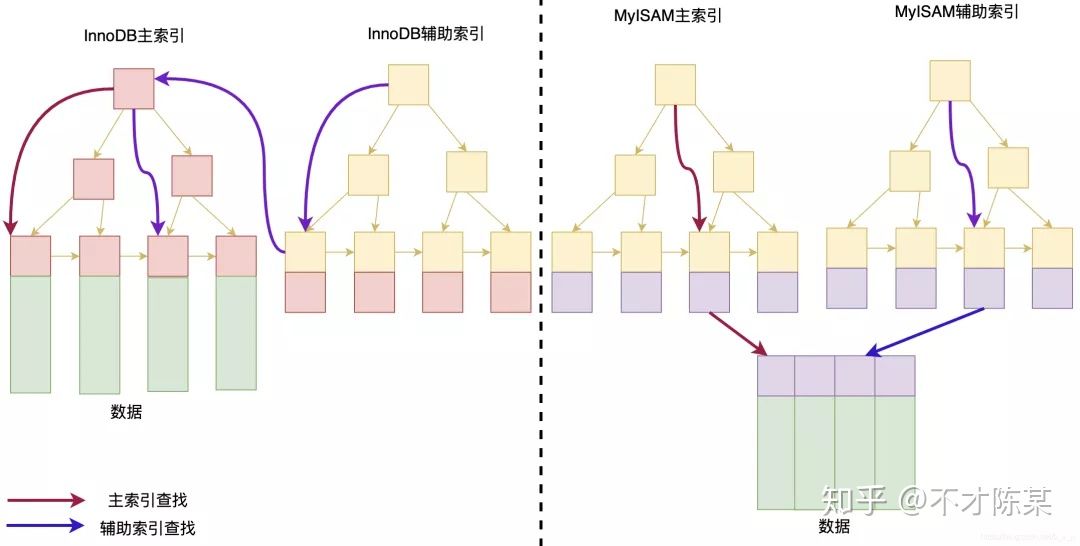 MyISAM索引:非聚集索引,数据和索引分开存储。叶子节点data存储记录的页指针,通过页指针将记录所在页从磁盘加载到内存上。 Innodb:聚集索引,主索引和数据放在一起。辅助索引data域中保存主键的值,通过这个值在主索引上找到数据。
MyISAM索引:非聚集索引,数据和索引分开存储。叶子节点data存储记录的页指针,通过页指针将记录所在页从磁盘加载到内存上。 Innodb:聚集索引,主索引和数据放在一起。辅助索引data域中保存主键的值,通过这个值在主索引上找到数据。
3.4 覆盖索引
如果查询的列全部是索引,那么可以直接在索引中查找。避免了读取整行数据,效率更高。
4.不同实现结构的比较
4.1 hashmap
定位快 无法排序 范围查找
4.2 平衡二叉树
数据量大时 树高 每次查询 IO次数多 范围查找排序困难
4.3 B-树
非叶子节点也包含数据。相对于B+树,相同数据下 树高更大。 范围查找,排序能力弱。
4.4 B+树
B+树:所有关键字在叶子节点中 叶子节点串联 并且有序 非叶子节点起到索引的作用 范围查找快.
5.索引优缺点
索引相当于一本书的目录,加快了查找,和排序。缺点由于维护了索引结构,增加了内存消耗,当增删改时需要维护结构,降低了操作的速度。
6. explain sql语句分析
id:表执行顺序。大优先 相同按顺序
type:
All 全表扫描
Index Index表全扫描,与All是读磁盘读比 index是从索引读 ,索引的数据量相对要小
range 索引中范围查找
ref 索引中多值扫描
eq_ref 索引唯一确定了一个值用于主键和唯一键扫描
rows:查找所需扫描的行
key_length:使用的索引列最大字节长度
extra:
using filesort:排序没有使用到索引
using temporary:使用了临时表保存排序结果
using index:使用了覆盖索引
6.索引失效
6.1索引列进行计算
6.2发生隐式类型转换
6.3范围查询右列
6.4null is null or != <> like %
参考文章:
https://www.zhihu.com/question/26113830














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









