







算法的由来:
我们假设下面四个词:i | like | my | job ,每个词的概率 p(i) = p1 , p(like) = p2 , p(my) = p3 , p(job) = p4,这四个词有4的阶乘种组合,现在是要求解含有这四个词的句子,怎么排列每个词使得句子的概率是最大的,句子可能有i like my job, l like job my,I job like my,I my job like......等等
p(i|like)就是i|like这俩词我的排列是like i的概率,p(job|i like)就是i like job这样排列的概率,
我们是要求解包含有这四个词的句子的联合概率,使它最大。
但是每个概率都是0-1之间的数,多次相乘以后小数位数过多,可能会超过inf溢出,所以我们对每个概率取对数,如果把每个词都看成一个独立事件,log p(i like my job) = log p(i) + log p(like) + log p(my) + log p(job),非独立事件log p(i like my job) = log p(i) + log p(like|i) + log p(my|i like) + log p(job|i like my),这样子不会出现小数位数溢出了,但是通过log函数性质我们知道,这几个log值都是负数,然后我们通过在前面取负号,即得到了一系列正数相加,-log p(i) , -log p(like) , -log p(my) , -log p(job)就是我们需要带入程序去求解的数,维特比算法实际上是把每个词的条件概率看作图中的一条边,这样一个求最大概率问题,通过取对数加负号就转换成了一个求最短路的问题
假设p(like|i) = 0.7 ,p(my|i) = 0.3 ,p(job|i) = 0.1 ,p(my|like) = 0.8, p(job|like) = 0.2,
p(job|my)=0.75
联合概率:
P(x1,x2,x3,x4) = p(x1)p(x2|x1)p(x3|x1x2)p(x4|x1x2x3)
现在假设每个词的概率只和它前一个词有关,即p(i like my job)=p(i)*p(like|i)*p(my|like)*p(job|my),,初始的每个词的概率可以给定,不管x1是选i 还是like还是my还是job,p(x1)都可以看作一个常数项,剩下的条件概率会标记为图的边,求最短路后乘个常数项p(x1)比较一下即可,所以核心还是求出最短路。
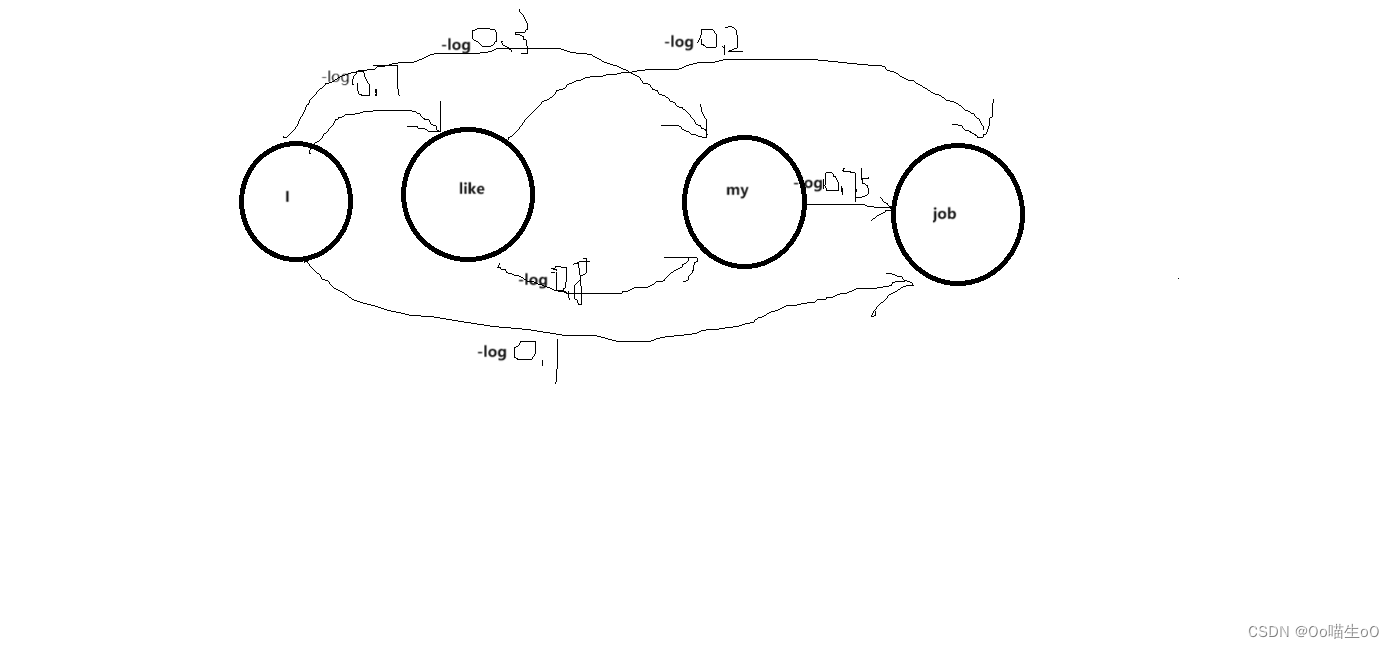
我理解的算法简化:
再简化一下,把开始和结束的点都置为1个,共有m层,除第一层和最后一层只有1个点外,其他层可能有若干个不同的点,求从第一层的点到最后一层的最短路(每一层经过且只经过一个点,除第一层外,每一层所有点都和它前一层的所有点有边),如下图:
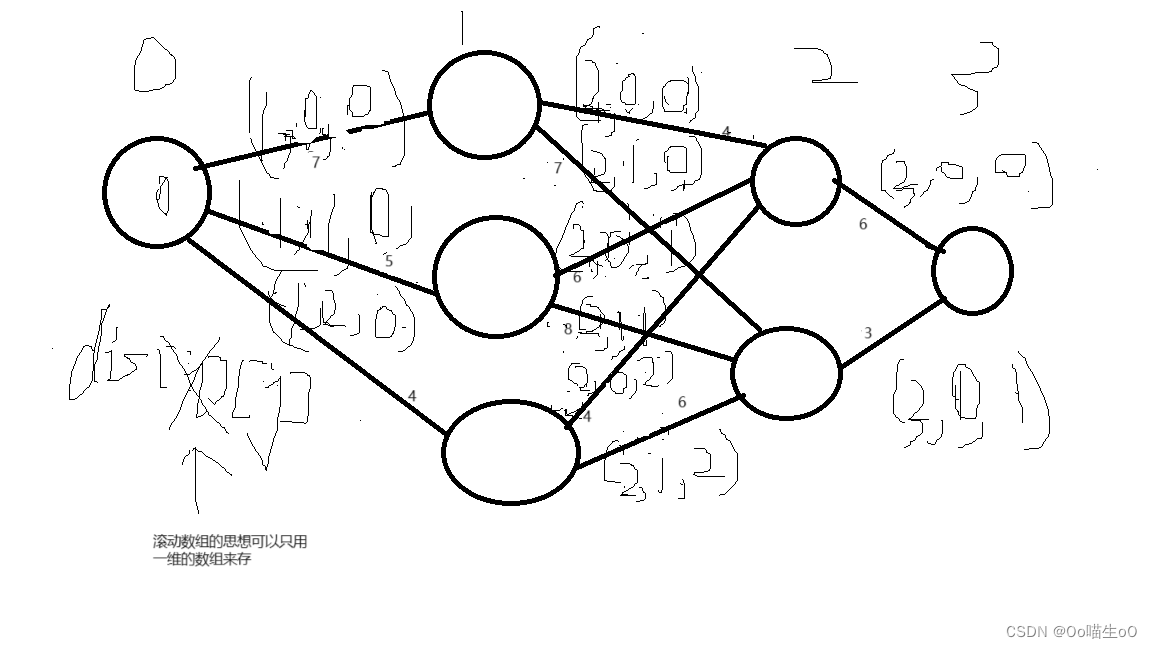
算法具体描述:
维特比算法:对起点到第 i层第j个点的最短路径,先求出起点到第i-1层每个点的最短路,对起点到第i-1层所有点的最短距离 加上 第i -1层所有点到第i层第j个点的距离之中 取一个最小值,即为起点到第i层第j个点的最短距离
如上图,层数和点都从0开始,我要求第0层第0个点到第3层第0个点的最短距离,我需要先知道 第0层第0个点到第2层第0个点的最短距离 和 第0层第0个点到第2层第1个点的最短距离,然后将这两个距离分别加上6 和 3(图上标的两个权重),之中取一个最小值,即得到第0层第0个点到第3层第0个点的最短距离。要求第0层第0个点到第2层第0个点的距离,需要先知道第0层第0个点到第1层第0,1,2个点的最短距离。。。。。。
所以不难看出,维特比算法是dp,这和迪杰斯特拉基于贪心的松弛思路是有本质区别的
我实现的思路:
我想用python实现,之前没用过python,可能写的比较笨拙,大佬看到不要笑,递推是很容易想到的,问题是在程序中该怎么存这种数据结构,本科阶段讲的邻接表和邻接矩阵我感觉都不太合适,邻接表不方便遍历查找,临界矩阵占空太大了,而且也难以体现一层一层传过来这种思路,所以综合考虑之下,我决定用一个列表里套二维数组的形式存这个图,e[i][j][k]表示第i-1层第k个点到第i层第j个点的权重(即第i层第j个点到它前面一层的第k个点的权重),dis[]数组表示第0层第0个点到遍历到当前层的所有点的最短路,path[]存的是路径
代码实现如下:
columnCnt指的是每一层的节点数量,disLen代表边的权重,dis代表从第0层第0个点到第i层的所有点的最短路径,当i取m的时候,即可得到起点到终点的最短路径,disTmp是暂时存储dis,如果直接滚动数组更新dis会影响下一次更新,因为每一层所有点都有到下一层所有点的边。
import numpy as np
def Viterbi(e,dis,m,columnCnt,inf,path):
for i in range(1, m):
disTmp = []
for j in range(columnCnt[i]):
minLen = inf
for k in range(columnCnt[i - 1]):
if e[i][j][k] + dis[k] < minLen:
minLen = e[i][j][k] + dis[k]
path[i - 1] = k
disTmp.append(minLen)
for j in range(columnCnt[i]):
dis[j] = disTmp[j]
print("最短路长度为:")
print(dis[0])
print("路径为:")
for i in range(0, m):
print(path[i])
if __name__ == '__main__':
m = input()
m = int(m)
inf = 99999
columnCnt = []
dis = []
path = []
for i in range(0, m):
num = input()
num = int(num)
columnCnt.append(num)
path.append(0)
dis = np.zeros(np.max(columnCnt))
#print(dis)
e = []
e.append([])
for i in range(0, m - 1):
e.append([])
for j in range(0, columnCnt[i + 1]):
e[i + 1].append([])
for k in range(0, columnCnt[i]):
e[i + 1][j].append([])
disLen = input()
disLen = int(disLen)
e[i + 1][j][k] = disLen
#print(e)
Viterbi(e, dis, m, columnCnt, inf, path)














 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









