






注:并发问题请往下翻
语音识别完整代码
由于我使用的网络音频,会在请求URL中携带一些参数信息,funasr是不支持待参数的链接的,所以下面我会把所有的音频先下载至本地,并且会去判断音频的格式,非mp3和wav格式的音频会进行音频格式的转换。
注:请先下载安装ffmpeg,因为音频格式的处理依赖与ffmpeg
ffmpeg Windows下载路径 https://github.com/BtbN/FFmpeg-Builds/releases/download/latest/ffmpeg-master-latest-win64-gpl-shared.zip
ffmpeg Linux下载链接 https://github.com/BtbN/FFmpeg-Builds/releases/download/latest/ffmpeg-master-latest-linux64-gpl-shared.tar.xz
请先安装下面两个依赖
pip install funasr
pip install pydub
import os
import threading
import uuid
from pathlib import Path
from funasr import AutoModel
import requests
from urllib.parse import urlsplit, unquote
from pydub import AudioSegment
# 创建锁
lock = threading.Lock()
# 初始化模型
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
spk_model="cam++", spk_model_revision="v2.0.2")
def get_filename_from_url(url):
"""
获取url中的文件名
:param url: 文件url
:return: 文件名
"""
# 解析URL并获取路径部分
path = urlsplit(url).path
# 获取路径的最后一部分作为文件名,并解码URL编码字符
filename = str(uuid.uuid4()) + '_' + unquote(path.split('/')[-1])
return filename if filename else None
def delete_file_os(file_path):
"""
删除临时生成的文件
:param file_path: 文件路径
"""
if os.path.exists(file_path):
try:
os.remove(file_path) # 或者使用 os.unlink(file_path)
print(f"文件 '{file_path}' 已成功删除")
except OSError as e:
print(f"删除文件时出错: {e}")
else:
print(f"文件 '{file_path}' 不存在")
# 注:我手动创建了temp_file的文件夹
def conversion_format(source_path: str):
"""
音频的格式转换,由于funasr支持的格式有限,故此次将非mp3和wav格式的音频转为mp3,tip:mp3格式的音频占用空间更小
:param source_path: 文件路径
:return: 转换后的文件路径,如果不需要转换则返回None
"""
extension = Path(source_path).suffix[1:]
file_name = Path(source_path).stem
if ['mp3', 'wav'].count(extension):
return None
audio = AudioSegment.from_file(source_path, format=extension)
# 导出为 mp3 文件,由于wav为无损格式,导出过大,所以此处统一采用mp3格式进行音频的转换,输出文件更小
new_file_name = f"{str(uuid.uuid4())}{file_name}.mp3"
new_file_path = os.path.join(os.getcwd(), 'temp_file', new_file_name)
audio.export(new_file_path, format=Path(new_file_name).suffix[1:])
return new_file_path
def audio2text_executor(input_url: str, hw: str = ""):
"""
语音转换执行方法,由于我使用的网络音频,会在请求URL中携带一些参数信息,
funasr是不支持待参数的链接的,所以下面我会把所有的音频先下载至本地,并
且会去判断音频的格式,非mp3和wav格式的音频会进行音频格式的转换
:param input_url: 文件下载路径
:param hw: 热词
:return: 处理结果
"""
# 本地保存路径和文件名,由于在线资源
base_path = os.path.join(os.getcwd(), 'temp_file', get_filename_from_url(input_url))
new_path = None
try:
response = requests.get(input_url)
if response.status_code == 200:
with open(base_path, 'wb') as f:
f.write(response.content)
else:
raise Exception(f"下载附件失败,状态码: {response.status_code}")
new_path = conversion_format(base_path)
transfer_file_path = base_path
if new_path:
transfer_file_path = new_path
# 加锁处理并发问题
with lock:
return model.generate(input=transfer_file_path, batch_size_s=300, hotword=hw)
finally:
# 删除临时文件
delete_file_os(base_path)
# 判断是否进行了文件格式转换,如果转换过则删除转换后的临时文件
if new_path:
delete_file_os(new_path)
并发问题
在单线程使用的时候是没有任何问题的,但是一但并发高了就导致各种错误,比如索引越界等情况,错误如下图
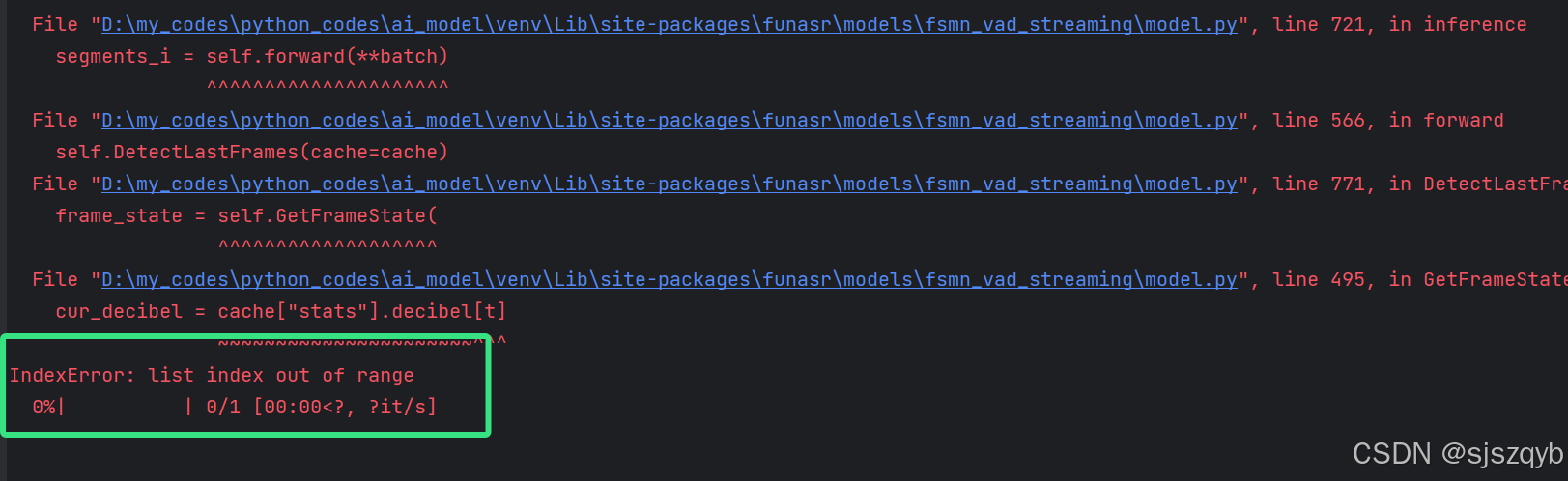
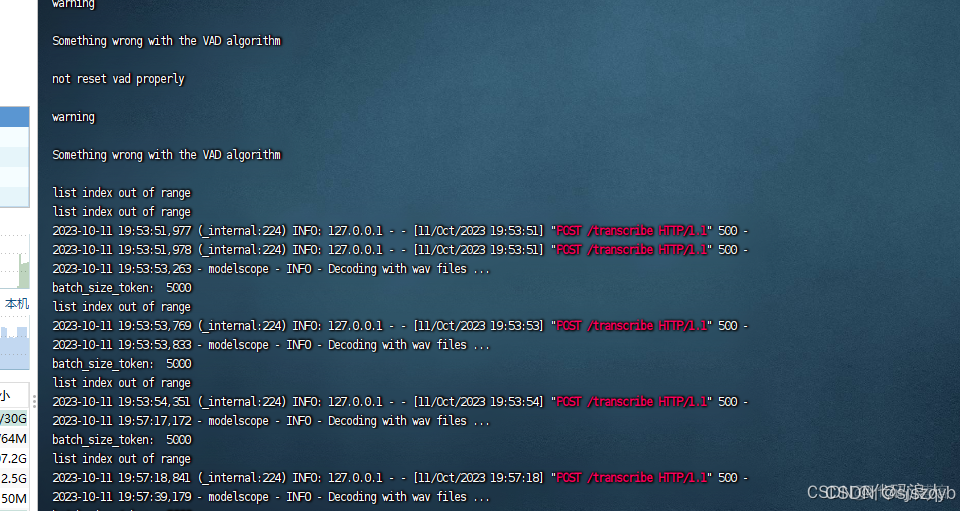
错误产生的原因
通过查看funasr的源码定位到错误为使用fsmn-vad模型进行语音端点检测的时候导致的,导致错误产生的文件为funasr/models/fsmn_vad_streaming/model.py,产生错误的原因为并发的时候系统生成的cache没有得到正确的处理,具体错误的代码如下图
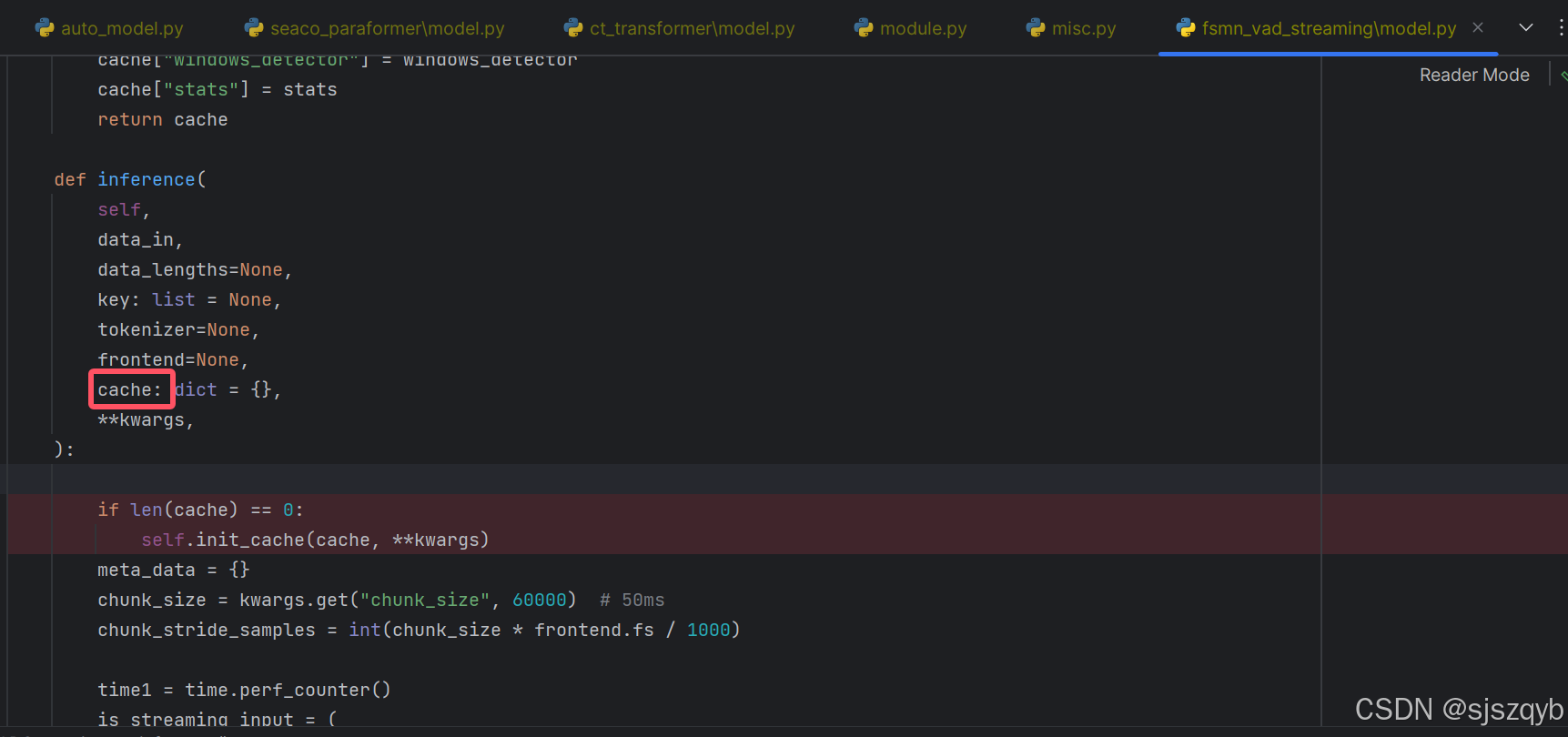
如果每次调用此方法就执行一次init_cache(cache, **kwargs)的话是能处理此问题的,但是治标不治本,问题实际上还是存在,只是这样能避免报错后整个系统不可用的问题,由于涉及到修改源码了,我就并未深究。
并发问题解决方案
由于我们项目并不需要特别高的并发,所以我采取了加锁的方式来处理此类问题,虽然降低了并发速度,但是好过cache出现问题导致整个项目需要重新运行才能再次执行语音识别要强。下面上解决的代码:
import os
import threading
from funasr import AutoModel
lock = threading.Lock()
def audio2text_executor(input_url: str, hw: str = ""):
with lock:
# 锁会在with代码块结束时自动释放
return model.generate(input=input_url, batch_size_s=300, hotword=hw)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









