







处理数据之前,通常会使用一些转换函数将「特征数据」转换成更适合「算法模型」的特征数据。这个过程,也叫数据预处理。
比如,我们在择偶时,有身高、体重、存款三个特征,身高是180、体重是180、存款是180000;存款的数值跟其他数据不在一个数量级,这意味着存款的对择偶结果的影响比较大,但我们认为这三个特征同样重要,这时候就需要把这些规格不同的数据转换到同一规格。
「归一化」是常用的预处理方式之一,就是把数据转换到 0~1 之间。
一、数据预处理API
sklearn.preprocessing 是数据预处理的 API
sklearn.preprocessing.MinMaxScaler( feature_range=(0,1) )
MinMaxScaler.fit_transform( data ):接收array类型数据,返回归一化后的array类型数据。
参数:
feature_range=(0,1):(可选,默认0~1)指定归一化的范围,。
二、准备数据集
准备一个测试用的「数据集」,这里我们用 datasets 自带的 鸢尾花数据集
from sklearn import datasets
# 获取数据源
iris = datasets.load_iris()
# 打印数据
print(iris.data)
输出:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
......
[5.9 3. 5.1 1.8]]
从输出结果可以看到,数据规格都是有「差异」的,接下来,我们对数据进行归一。
三、归一化处理
fit_transform() 可以对数据进行「归一」处理
from sklearn import preprocessing
from sklearn import datasets
# 初始化
mm = preprocessing.MinMaxScaler()
# 获取数据源
iris = datasets.load_iris()
# 归一化处理
new_data = mm.fit_transform(iris.data)
print(new_data)
输出:
[[0.22222222 0.625 0.06779661 0.04166667]
[0.16666667 0.41666667 0.06779661 0.04166667]
......
[0.44444444 0.41666667 0.69491525 0.70833333]]
从结果可以看到,归一后的结果,数据规格都在 0~1 之间。
实际上,fit_transform() 不只可以 “归1” ,我们自己设置归一的范围。
四、设置归一化范围
实例化 MinMaxScaler 时,指定 feature_range 参数的值,可以设置归一的「范围」。
from sklearn import preprocessing
from sklearn import datasets
# 初始化
mm = preprocessing.MinMaxScaler(feature_range=(2,3))
# 获取数据源
iris = datasets.load_iris()
# 归一化处理
new_data = mm.fit_transform(iris.data)
print(new_data)
输出:
[[2.22222222 2.625 2.06779661 2.04166667]
[2.16666667 2.41666667 2.06779661 2.04166667]
......
[2.44444444 2.41666667 2.69491525 2.70833333]]
从输出结果可以看到,数据的范围变成 2~3 区间。
接下来,我们了解一下,MinMaxScaler 是如何进行归一的。
五、归一化原理
MinMaxScaler 根据以下「公式」进行归一:
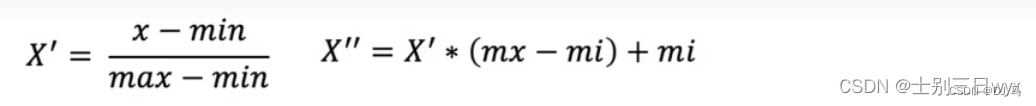
- 以列为基准,max为一列的最大值,min为一列的最小值
- mx、mi是归一指定的区间,默认mx=1,mi=0
我们准备一些测试数据:
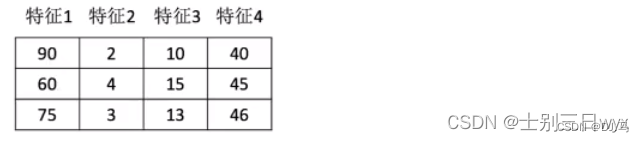
我们拿特征一这一列举例,第一个数是90,先带入第一个公式:X‘=(90-60)/(90-60)=1
再带入第二个公式:X"=1*1+0=1
那么第一个数就转换成1.
知道了归一化的计算方式后,可以发现归一化存在一定的「局限性」。
归一化是根据最大值和最小值来计算的,当最大值/最小值出现异常时,比如最大值跟其他数据差的非常多,那么这种计算方式就会存在较大的误差。只适合传统精确小数据场景,对于其他场景,可以使用标准化的方式。
六、标准化
sklearn.preprocessing.StandardScaler()
StandardScaler.fit_transform( data ):接收array类型数据,返回保准化后的array类型数据。
我们将归一化的案例,用「标准化」函数再处理一遍
from sklearn import preprocessing
from sklearn import datasets
# 初始化
ss = preprocessing.StandardScaler()
# 获取数据源
iris = datasets.load_iris()
# 标准化处理
new_data = ss.fit_transform(iris.data)
print(new_data)
输出:
[[-9.00681170e-01 1.01900435e+00 -1.34022653e+00 -1.31544430e+00]
[-1.14301691e+00 -1.31979479e-01 -1.34022653e+00 -1.31544430e+00]
......
[ 6.86617933e-02 -1.31979479e-01 7.62758269e-01 7.90670654e-01]]
标准化的计算方式和概率论的标准化公式一样:
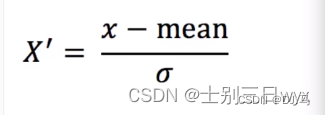
- 以列为基准,mean是平均值,0是标准差















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











