







说明
本文是跟随一个大佬学习深度学习的日常笔记,主要记录每次学到的新的知识,希望能写下来随时翻看,大佬网页链接(https://cuijiahua.com),有兴趣的老哥可以去看他的网页,很全面。
闲话不多说,直接开始这次的学习笔记。
关于感知器
一开始听到感知器的时候,我以为是一个新的词,看上去就很厉害有没有。但是其实感知器就相当于神经网络中的神经元。我们来回顾一下,神经元是做什么的?简单来讲就是接受输入值,输出相应的结果嘛,很简单。那么感知器其实就和神经元的作用相同,主要部分如下图:
它主要包含了三个方面
- 输入与偏执单元:主要对输入的数据进行计算,其中的参数就是权重w和偏执单元b,相当于y=wx+b
- 激活:对上一步计算出来的结果进行处理,我觉得可以理解为神经网络中的softmax或者relu等激活函数
- 输出:就是最终的结果
感知器可以做什么
那么上面的一个感知器可以用来做什么呢?我们知道,使用神经网络可以根据输入和输出训练出模型参数来对之后的输入进行预测,而作为神经网络的一个单元,感知器当然也可以用于训练出参数来做预测啦!
感知器的实现
在第一部分,我们就介绍了组成感知器的三个部分,那么我们通过主要流程来介绍感知器的原理,也是三个方面:
- 输入:上面我们已经知道了,感知器的输入其实就是类似于y=wx+b的函数,写的稍微高大上一点就是:y=w1x1+w2x2+w3*x3+…+b。就是神经网络的其中一个输入部分啦。
- 激活函数加输出:激活函数可以任意选择,只要使用与你的输出相搭配的就可以了(后面我自己写的demo里面甚至都没有用激活函数 啦啦啦,你打我呀)
- 训练:当然了,最后我们要通过不断的训练来更新感知器里面的相关参数,那么如何训练呢,看来下面的图你会觉得,这也太简单了吧:
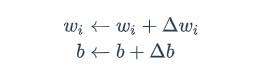
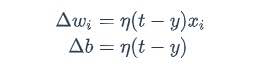
第一张图意思是不断的迭代更新,第二张图是说明每次迭代的东西是哪来的。wi是与输入xi对应的权重项,b是偏置项,t是训练样本的实际值,η是学习率。
稍微学过机器学习的人其实就可以看的出来,这不就是机器学习回归模型里面用于更新参数的式子吗,就是根据损失函数对各个参数求导,得到每个参数的导数,再每次加到参数上去。没错了,就是传说中的梯度下降,哈哈哈哈哈哈????
感知器的代码实现
既然你们已经参透了本座的奥秘,接下来就要真枪实弹的练一练了
首先我们来看看并解读一下大佬的部分代码,可以直接去我上面给出的网址找代码哟(代码主要是实现两个输入的and运算,也就是输入[0,0],输出0,输入[1,0],输出0,[0,1],输出0,[1,1],输出1 ,我们要训练参数来)
class Perceptron():
def __init__(self,input_num,activator):
self.activator = activator
self.weights = [0.0 for _ in range(input_num)]
self.bias = 0.0
def __str__(self):
return 'weights\t:%s\nbias\t:%s\n' %(self.weights,self.bias)
def predict(self,input_vec):
return self.activator(
reduce(lambda a, b: a+b, list(map(lambda x, w:x*w, input_vec, self.weights)), 0.0)+self.bias)
#该函数用于根据输入得到预测的输出#分析:上述代码中,最里层为一个lambda函数,用于定义x和w相乘,外面嵌套map函数,将序列放入(x*w)函数中运算,外面嵌套list,因为返回的是多个结果,存到list数组中
# 外层继续嵌套lambda函数,计算里边求出的总和,最外层嵌套reduce()用于将序列全部求和,最后,使用激活函数activator将算出的数值做最终的转换
# 注:我认为reduce()和map()是同级别的函数,都可以将数据映射到需要的式子中
def train(self, input_vec, labels, iteration, rate):
for i in range(iteration):
self._one_iteration(input_vec, labels, rate)
# 下方函数用于对每次输入的序列队进行计算并更新
def _one_iteration(self, input_vec, labels, rate):
samples = zip(input_vec, labels)
for (input_vec, labels) in samples:
output = self.predict(input_vec)
self._update_weights(input_vec, output, labels, rate)
# 下方函数用于对预测的值和正确的标签进行比较,并由次更新权重和偏执
def _update_weights(self, input_vec, output, label, rate):
delta = label-output
self.weights = list(map(lambda x, w: w+rate*delta*x, input_vec, self.weights))
self.bias += rate * delta
对于我这个接触python不久的人来说,刚开始看,真的是一脸蒙蔽,因为函数嵌套太多来了,看的我头晕,所以我也是边看边给大佬的代码加了一些备注。让我们来慢慢看。
-
首先,定义一个感知器类,它的init函数用于初始化各个参数项和激活函数,其中,input_num用于获取输入的个数以确定要初始化几个w的权重,意思就是我们现在只判断两个数的亦或,input_num只要是2就行了,那么在weight初始化的时候就生成两个0。
-
(str函数主要用于打印,我们跳过)predict函数:我刚开始看到的时候,龟龟,这也太长了吧,我要崩溃了。还好经过我个人的不断摸索加百度知道,终于搞懂了。首先我们看最里面的一层
map(lambda x, w:x*w, input_vec, self.weights)
lambda其实就是用于定义一个函数,我们自己定义函数的参数和功能,以及函数的输入,那么上面lambda代码就是定义一个xw,而map简单来讲就是将输入数据映射到我们的定义的函数中以获取计算后的值
之后外面嵌套了一层list()因为我们输入的是一个input_vec序列,所以一一计算后输出的当然也是序列啦。
上面部分的代码意思就是得到w1x1,w2x2,w3x3…这一列表
外面同样是嵌套一层lambda函数,用于做加法,但是不同的是,做外面嵌套的是reduce而不是map函数了。那么在经过度娘后,知道了reduce函数其实是将每次得到的数值继续做函数运算,类似于递归吧,比如
reduce(lambda a,b:a+b ,[1,2,3,4,5]),意思就是1+2+3+4+5 。
所以这一步的含义不难理解,就是将上面得到的list相加,w1x1+w2x2+w3*x3
最后就是添加bias了。 -
训练:一开始我看到这三个函数是一个套着一个,我就在想为什么不写一起呢?后来我把下面的三个函数写到一起,果然,报错了…
我们先来分析一下这三个逼都干了些什么。其实就是3步:1.获取迭代的步数,就是训练的次数 2.在每一步迭代中,根据输入的值获取输出的值,并传入的下一个函数 3.更新感知器参数,根据上面提到的形如梯度下降的方法,很简单。
那么坑在哪里呢,就是我尝试把三个函数写在一个函数里面的时候,zip()报错
zip argument #1 must support iteration
我简单的理解就是zip对列表对进行配对,而每次配对使用完之后需要对其进行释放,如果将两个函数拼在一起,每次使用后都没有释放当前的列表对就进行下一次的读入,因此报错,当然,这是我的小小的见解,大家可以有兴趣可以去查一下。
剩余的代码就是生成数据,调用函数,最后测试,相信大家都看的懂。
def f(x):
return 1 if x>0 else 0
def get_training_dataset():
input_vec = [[1, 1], [0, 0], [1, 0], [0, 1]]
labels = [1, 0, 0, 0]
return input_vec, labels
def train_and_perceptron():
p = Perceptron(2, f)
input_vec, labels = get_training_dataset()
p.train(input_vec, labels, 10, 0.1)
return p
if __name__ == '__main__':
and_perception = train_and_perceptron()
print(and_perception)
print('1 and 1 = %d' % and_perception.predict([1, 1]))
print('1 and 1 = %d' % and_perception.predict([0, 0]))
print('1 and 1 = %d' % and_perception.predict([0, 1]))
print('1 and 1 = %d' % and_perception.predict([1, 0]))
我的小demo
ok,对于上面大佬的代码解读就是这样了,其实理解后,感知器是很简单的。
那么在参考了别人的代码后,当然要写一下自己的小demo了,话不多说,关门,放码
# 用感知器实现简单的线形回归的预测
from functools import reduce
class Perception():
def __init__(self):
self.weight = 0
self.bias = 0
def prediction(self,input_x):
return self.weight * input_x + self.bias
def train(self, iterator, input_x, labels):
for i in range(iterator):
self._one_iterator(input_x, labels)
def _one_iterator(self, input_x , labels):
samples = zip(input_x, labels)
for (input_x, labels) in samples:
output_y = self.prediction(input_x)
delta = labels - output_y
self.weight += 0.01 * delta * input_x
self.bias += 0.01 * delta
def get_data():
x_input = [1,2,3,4,5,6,7,8,9,10]
labels = [2,4,6,8,10,12,14,16,18,20]
return x_input, labels
def train_perception():
x_input, labels = get_data()
p = Perception()
p.train(1000, x_input, labels)
return p
if __name__ == '__main__':
p = train_perception()
print(p.prediction(20))
print(p.weight)
其实就是简单的线形回归啦,最后的输出
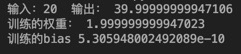
权重接近2,偏执项接近0,完美。其中有个坑,就是学习率选取的大小要适当
总结
差不多就结束了,感谢上述提到的大佬,让我能学到这一个知识,之后跟随大佬以及大佬们的脚步,多多学习
参考链接:https://cuijiahua.com/blog/2018/10/dl-7.html(https://cuijiahua.com/blog/2018/10/dl-7.html
https://www.cnblogs.com/hesi/p/7149678.html















 2778
2778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









