







第一次接触pytorch,本贴仅记录学习过程,侵删
在B站看完了视频的P8 08.加载数据集。
附上视频地址:《PyTorch深度学习实践》完结合集_08. 加载数据集
先记录一些笔记。
Dataset和DataLoader都是用于加载数据的重要工具类。
Dataset:构造数据集,满足我们索引的需求。
DataLoader:用于训练时快速拿出Mini-Batch来供我们使用。
之前在做前馈时,我们是把所有的数据都放进来了。
在之前的课中有讨论过,在进行梯度下降的时候,目前主要有两种选择:
- Batch:全部数据都用,可以最大化的利用向量计算的优势来提升计算速度,但在性能上可能会有一些问题。
- 随机梯度下降:只用一个样本,能够在优化中克服鞍点问题,性能可能会更好,但有可能会导致优化时用时过长。
所以在深度学习中,我们会使用Mini-Batch来均衡我们在性能和时间上的平衡需求。
使用Mini-Batch的重要概念:
在使用Mini-Batch训练方法之后,我们的训练循环需要写成嵌套的循环,外层表示训练周期,内层来对Batch进行迭代。
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
Epoch:把所有训练样本进行正馈、反馈传播。
Batch-Size(批量大小):进行一次正馈、反馈、更新所用的样本数量。
Iteration:Batch总共分为多少个Mini-Batch,也就是内层的迭代进行了多少次。
当一个数据集的Dataset能够支持索引[i]、获取长度len,将来DataLoader就可以对这个数据集进行自动的、小批量的数据集生成。
shuffle=True 即打乱样本顺序。
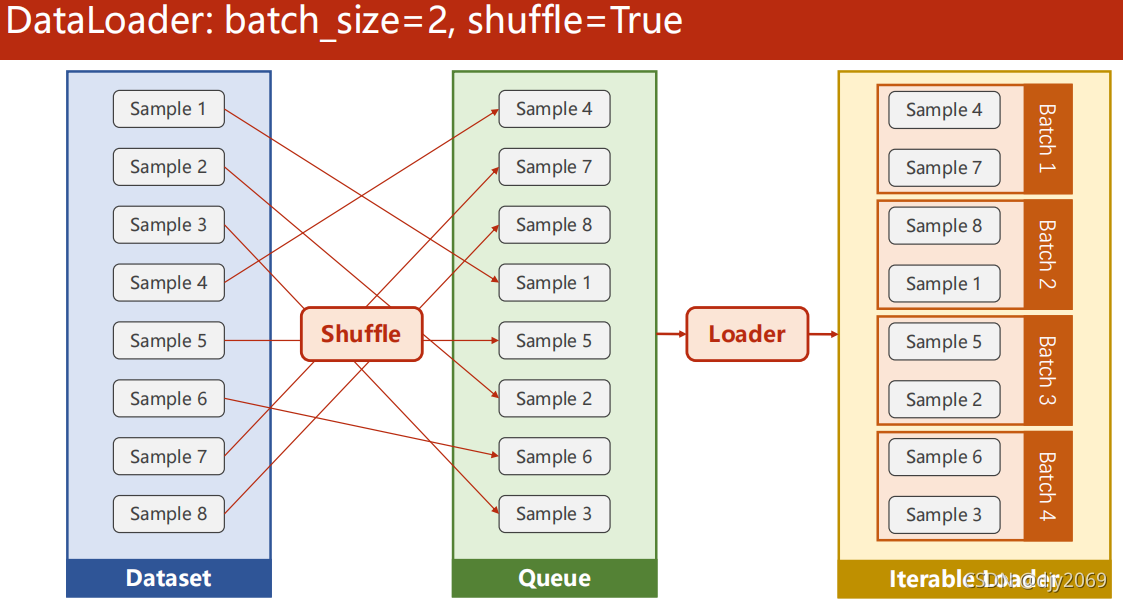
Dataset是一个抽象类,也就是不能被实例化,只能被其他的子类继承。
DataLoader是用来帮助我们加载数据的,可以实例化DataLoader来帮助我们做这些工作。
如何定义 Dataset
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
在定义init设置数据集时,主要有两种方式:
- 如果数据集本身容量不大,那么就可以直接全部读取进来。
- 如果Y是简单分类或回归的数值就可以都加载进来,如果Y是一个非常复杂的张量,这时就把它的文件名放到列表中,等到在getitem里时就可以读取第i个元素,X和Y里的第i个元素现去文件中把它读出来再返回,这样才能保证内存的高效使用。简单来说,Y若是一个非常复杂的张量, 那么就只读文件名,根据文件名加载文件。
注意!!!:设置num_works之后,在windows下容易报错。

解决:
把我们需要用loader迭代的代码封装起来。封装到if语句、函数中都可以。
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
举例:Diabetes Dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
对于图像来说:
img.shape[0]:图像的垂直尺寸(高度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
对于矩阵来说:
shape[0]:表示矩阵的行数
shape[1]:表示矩阵的列数
self.len = xy.shape[0]
这样我们就可以知道数据集一共有多少个了。这个在len函数中就可以直接用。
Using DataLoader:
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# trainload中就是Dataset里实现的_getitem_()的返回值
# 0表示从0开始枚举
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
enumerate(sequence, [start=0])
enumerate() 函数:用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据下标和数据。
如果不想写
inputs, labels = data
可以在for语句中
for i, (x, y) in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = (x, y)
或是
for i, (inputs, labels) in enumerate(train_loader, 0):
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
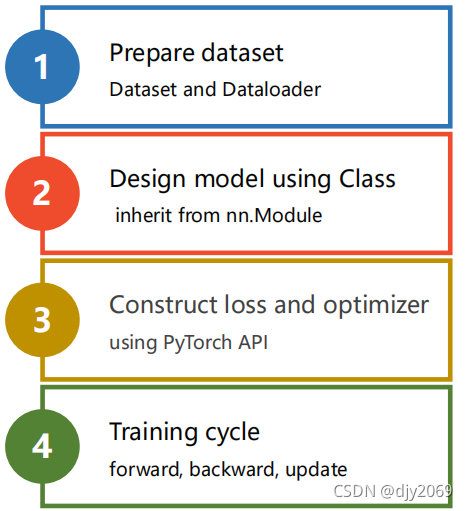
经过以上改造,总的流程为:
torchvision中内置了很多数据集,我们可以使用。
例如: MINST Dataset
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
transform= transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
transform= transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=32,
shuffle=False)
for batch_idx, (inputs, target) in enumerate(train_loader):
……
最后是作业:
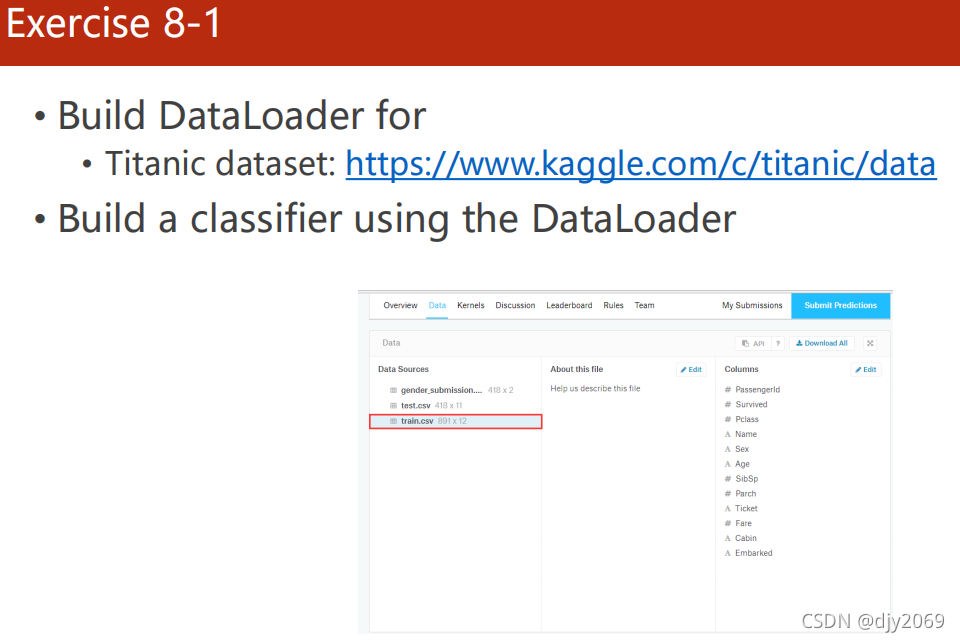
Titanic dataset: https://www.kaggle.com/c/titanic/data
首先罗列几个会用到的知识点:
1、独热表示 one-hot representation
独热码,在英文文献中称做 one-hot code。
直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制。
即使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
这样理解似乎有点抽象,可以通过举例来理解:独热表示 one-hot representation——SssattyF
2、squeeze()函数:对tensor变量进行维度压缩,去除维数为1的的维度;如果原tensor没有维度为1,则不会进行任何操作;也可以指定尝试将哪一个维度进行压缩。如果被指定的维度其维数为1,则压缩,反之不对该维度操作。
参考链接:Pytorch squeeze()的简单用法——xiongxyowo
最后代码我参考了:《PyTorch深度学习实践》-刘二大人 泰坦尼克号作业——不废江流
啥也不懂的小白欢迎指正,侵删















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









