







 本文详细介绍了DeepClosestPoint(DCP)模型在点云配准任务中的应用。DCP通过四个关键步骤:初始特征生成、注意力机制、虚拟点对匹配及SVD求解位姿变换来实现点云配准。实验结果展示了该方法在不同条件下的性能。
本文详细介绍了DeepClosestPoint(DCP)模型在点云配准任务中的应用。DCP通过四个关键步骤:初始特征生成、注意力机制、虚拟点对匹配及SVD求解位姿变换来实现点云配准。实验结果展示了该方法在不同条件下的性能。

Deeo Closest Point(DCP[1])可以算是小数据集ModelNet40上使用深度学习做配准的开山之作了,首先呈现整体模型架构图:
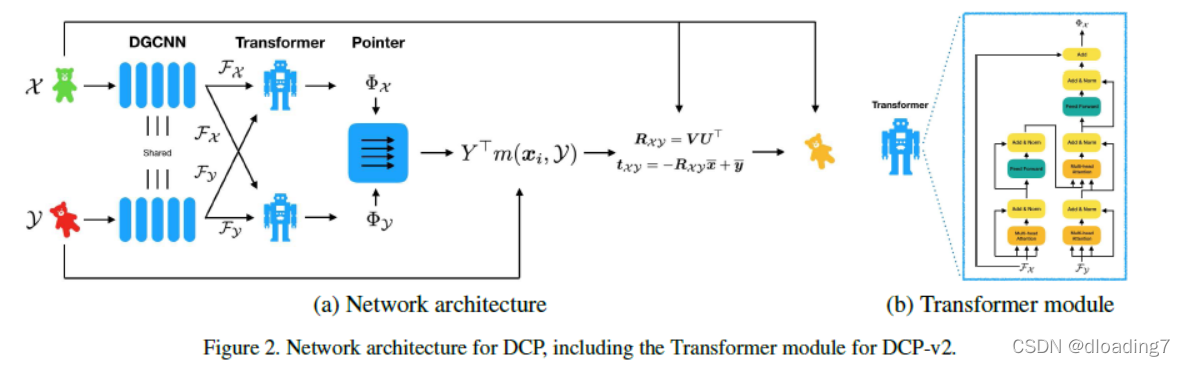
总体来说,DCP模型主要由4个部分构成:
1. 初始特征生成(Initial Feature Embedding)
2. 注意力机制模块(Attention)
3. 虚拟点对匹配关系生成(Pointer Generation)
4. SVD求解位姿变换
下面按照这几个模块的顺序依次进行分析:
Network
- Initial Feature Embedding
对于输入的 X X X(source)与 Y Y Y(target)点云,首先使用DGCNN[2]架构或者PointNet[3]进行特征提取Feature Embedding,给点云中的所有点生成一个初始的逐点特征,即:
X → D G C N N F X , Y → D G C N N F Y X\mathop \to \limits^{DGCNN} {F_X},Y\mathop \to \limits^{DGCNN} {F_Y} X→DGCNNFX,Y→DGCNNFY - Attention
由于以上Feature Embeddings F X , F Y {F_X},{F_Y} FX,FY的计算是相互独立的,即 F X {F_X} FX与 F Y {F_Y} FY是没有任何交互的,因此进一步为了使两点云的特征能够进行相互感知,DCP使用Attention模块以进行信息交互:
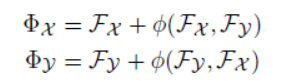
ϕ ( ⋅ ) \phi ( \cdot ) ϕ(⋅)即transformer操作,可以看出,上式相当于对 F X {F_X} FX与 F X {F_X} FX多加了一个信息余项(residual term) ϕ ( ⋅ ) \phi ( \cdot ) ϕ(⋅).
经过以上操作, ϕ X , ϕ Y {\phi _X},{\phi _Y} ϕX,ϕY为新的 X X X与 Y Y Y的逐点特征。 - Pointer Generation
经过以上的Feature Embedding操作,接着给点云 X X X中的每一个点,利用点云 Y Y Y,生成匹配点对correspondences. 例如对 x i ∈ X {x_i} \in X xi∈X,生成一个点 y ^ i {\hat y_i} y^i与之形成匹配对关系:
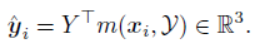
可以看到, y ^ i {\hat y_i} y^i的形成相当于对点云 Y Y Y中的所有点进行加权求和,即利用点云 Y Y Y生成一个对应匹配点,而权重由以下式子生成:
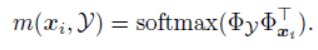
可以看到,即使用 x i {x_i} xi的feature与点云 Y Y Y的feature做了一个向量内积,接着softmax成概率。
利用以上公式,即可对点云 X X X中的所有点 x i {x_i} xi生成一个correspondence y ^ i {\hat y_i} y^i. - SVD Pose Estimation
利用以上得到的点对对应关系: x i ↔ y ^ i {x_i} \leftrightarrow {\hat y_i} xi↔y^i
利用SVD进行位姿求解,这里文章提到传统SVD是不可微的,因此使用[4]中的SVD,以便于梯度反向传播。
Loss & Supervision
这里使用的loss比较直接,使用gt进行监督即可:
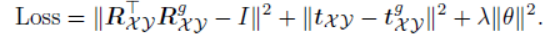
正则项为了减少模型的复杂程度。
Experiment
ModelNet40共由40个label下的12311个点云(2048 points)所组成,作者在DCP中将9843/2468个点云划分为训练及测试集。一共进行了三组测试:
- Full Dataset Train & Test (9840/2468 for training/testing)
第一组实验是在全类别下进行,在40个labels下的训练集(大小为9840)下进行网络训练,在测试集(大小为2468)上进行测试,目的是检测DCP在unseen point clouds上的配准效果:
| DCP_v2 | comment | rot_MSE | rot_RMSE | rot_MAE | trans_MSE | trans_RMSE | trans_MAE |
|---|---|---|---|---|---|---|---|
| papers | 1.307329 | 1.143385 | 0.770573 | 0.000003 | 0.001786 | 0.001195 | |
| dcp_v2.t7 | provided by author | 1.217547 | 1.103425 | 0.750243 | 0.000003 | 0.001696 | 0.001170 |
| model.best.t7 | batch_size = 32 GPU = 3 EPOCH=250 | 29.563711 | 5.437252 | 3.530627 | 0.000177 | 0.013301 | 0.009703 |
- Category Split(unseen categories)(5112/1266 for training/testing)
第二组实验的目的是测试DCP在unseen categories上的配准效果,因此训练集只包括前20个label(大小为5112),测试集只包括后20个label(大小为1266)
| DCP_v2 | comment | rot_MSE | rot_RMSE | rot_MAE | trans_MSE | trans_RMSE | trans_MAE |
|---|---|---|---|---|---|---|---|
| papers | 9.923701 | 3.150191 | 2.007210 | 0.000025 | 0.005039 | 0.003703 | |
| unseen-clean.t7 | provided in this issue | 10.985620 | 3.314456 | 2.153236 | 0.000035 | 0.005931 | 0.004376 |
由于时间久远,之前训练保存的模型已找不到,因此这里并没有在unseen categories这个设定下重新训练,这里只evaluate了RPMNet[4]作者在this issue中提供的权重。
- Resilience to Noise(9840/2468 for training/testing)
第三组实验目的是测试DCP在噪声扰动下的配准效果,使用第一组实验(即在无噪声添加下训练)得到的权重,在添加噪声下的测试集上进行评估
| DCP_v2 | comment | rot_MSE | rot_RMSE | rot_MAE | trans_MSE | trans_RMSE | trans_MAE |
|---|---|---|---|---|---|---|---|
| papers | 1.169384 | 1.081380 | 0.737479 | 0.000002 | 0.001500 | 0.001053 | |
| dcp_v2.t7 | provided by author | 1.163321 | 1.078573 | 0.732567 | 0.000002 | 0.001505 | 0.001056 |
| model.best.t7 | batch_size = 32 GPU = 3 EPOCH=250 | 30.158920 | 5.491714 | 3.582376 | 0.000175 | 0.013214 | 0.009648 |
Analysis
从复现结果里来看,在setting-1与setting-3下效果都比较差,这里很奇怪,由于DCP的默认batch size = 32,而这在12G显存的显卡上单卡是训不起来的,因此用的是3卡同时训练,但得到的效果并没有文章中的结果那么好,这里作者也提到small batch size可能训不出一个好的结果,也许作者的模型是使用一个大batch size在单卡上训练得到的,这里由于硬件限制就没有继续做实验去探究。
另外关于如何训练得到DCP的pretrained model在这个issue中也提到了一些问题,感觉DCP难以复现的问题并不是一个个例。
Reference
[1] Wang Y, Solomon J M. Deep closest point: Learning representations for point cloud registration[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 3523-3532.
[2] Wang Y, Sun Y, Liu Z, et al. Dynamic graph cnn for learning on point clouds[J]. Acm Transactions On Graphics (tog), 2019, 38(5): 1-12.
[3] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660.
[4] Yew Z J, Lee G H. Rpm-net: Robust point matching using learned features[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 11824-11833.

















 7236
7236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









