







博主最近接手了一个SSD有关的检测项目,大四的时候接触了DL,这段时间在训练mobilenet-SSD的时候想自己也努力努力对这些大牛级模型进行一些小修小补吧。SSD网络前几层用的是VGG部分网络,想了一下,接触DL有4,5个月了,对这些基本的网络还没进行一个系统的总结过,于是乎花了一下午的时间看了一些经典网络结构,话不多说转入正题。
LeNet
这是入门级网络模型,没什么好说的,一个字:经典。
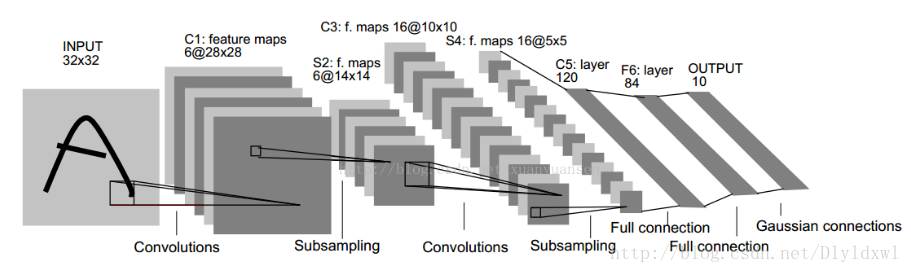
有关卷积,池化等计算在此不做赘述。该网络很基础,有不清楚的可以看这篇博客
AlexNet
2012年ILSVRC竞赛中该网络获得了第一名,这个网络和前一个网络在结构上区别不大。具体见博客。
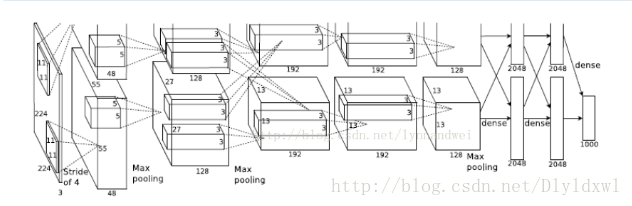
AlexNet有八层,60M以上的参数量。前五层是卷积层,后三层是全连接层。该网络的创新点有以下几个:
数据增强。
Dropout的使用。
每次输入一个样本,网络会随机的“丢失”一些“结点”,这样相当于给神经网络尝试了一个新的结构,降低了神经元之间的复杂的互适应关系,避免过拟合的发生。激活函数。
Relu代替了Sigmoid,Relu得到的SGD的收敛速度明显快于sigmoid/tanh等,但是Relu也有明显的缺点,例如Relu将左侧值全部置零,容易导致一些结点一直被忽略。。所以后续也有对Relu改进的一些激活函数。多GPU。
这个可以说是贡献了比一臂之力还大的洪荒之力重叠池化和LRN局部响应归一化等。
总的来说,AlexNet较LeNet做出了较大的改进,但是参数量过大是除不去的诟病。。
VGGNet
VGGNet在2014年ILSVRC竞赛拿下亚军位置。VGGNet常见的有五种结构:
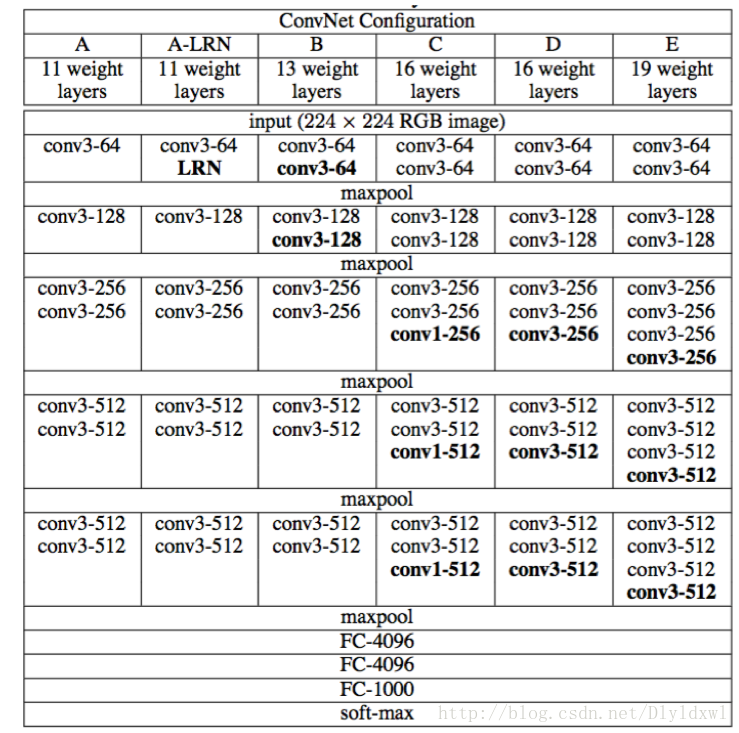
一般用的比较多的是VGG16(D网络)和VGG19(E网络)。每个网络结构增加的层数和位置可以从表中看出。
相较于AlexNet,VGG有以下创新:
VGG所有的卷积层均只使用3*3的filter,这个地方有个比较难理解的问题,就是说为什么5*5和7*7的filter可以看成2个或3个filter。以5×5filter举例,解释如下:
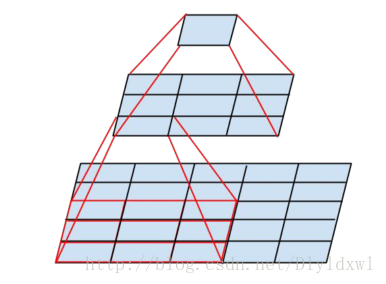
在一个5*5图像上,用2个3*3的filter可以将其卷积为1*1的图像,这和使用一个5*5的filter结果是一样的,也就是达到一样的感受野,但是使用多个filter增强了网络的非线性程度,此外还减少了参数量(2个3*3的参数有2*3*3*channel,1个5*5有5*5*chanel).
2. Multi-Scale训练。
首先将原始图片等比例缩放,保证短边大于224,再在图片上随机提取224*224的windows,因为物体尺度变化多样,Multi-Scale可以更好的识别物体,VGG有两种多尺度训练方法。一是不同scale下训练多个分类器,S=短边长度,训练S=256和384两个分类器;二是训练一个分类器,每次数据输入时,S随机从[Smin, Smax]中选择。实验证明,在scale区间上训练比固定S效果好。
总结一下VGGNet,一个字:深;两个字:更深。
GooLeNet
这是2014年力压VGGNet勇夺冠军的网络模型!~~
不多BB,开门见山的说,个人觉得这个网络就是因为Goole对AlexNet的参数量太多看不下去了才产生的。。GooLeNet的层数为22层。。该网络最大的创新点在与inception结构的提出,减少了因为网络规模的增大而导致参数爆炸的问题。Inception结构如下:
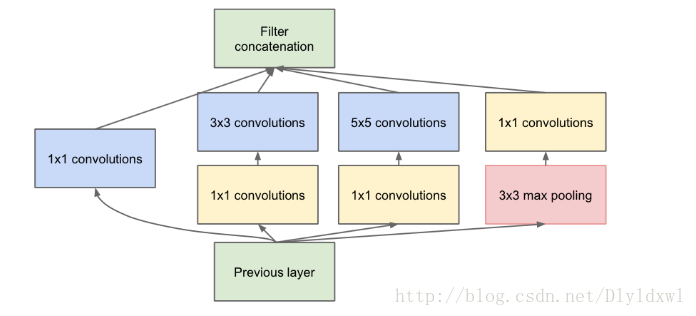
使用不同的filter,意味中感受野不同,最后的拼接意味着不同尺度性的融合,1,3,5的filter尺寸可以通过改变pad来达到相同维度的特征。网络越深,需要提取的特征越抽象,因此需要增加3*3和5*5的filter数量,随之而来的问题是参数量会爆炸,因此在这些卷积前面进行了1*1的卷积操作来达到降维目的,这个地方也比较难理解,下面贴出未加1*1filter的inception图和GooLeNet结构图:
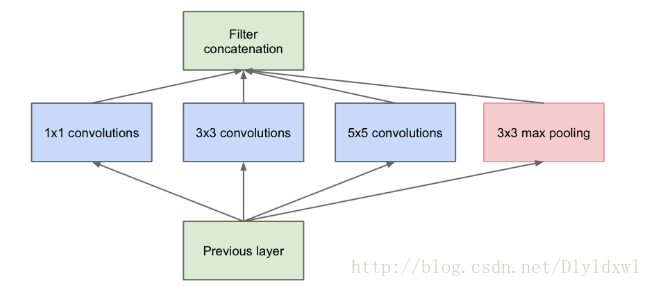
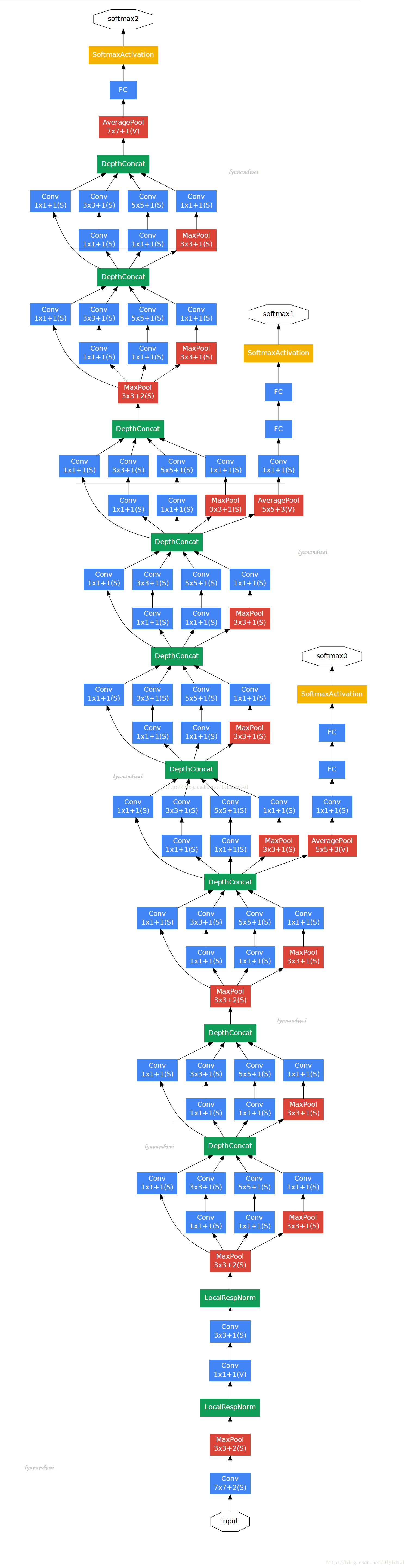
以Inception moudle 3a为例进行说明:上一步输出是28*28*192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,未加1*1卷积核时,参数数量为64*1*1*192+128*3*3*192+32*5*5*192
加了1*1卷积核后,参数量为64*1*1*192+96*1*1*192+128*3*3*96+16*1*1*192+32*5*5*16,参数量减少了约三分之一。因为1*1filter可以改变该层feature map 的“厚度”.摘抄一句话,1*1filter可以实现跨通道的交互和信息整合和进行卷积核通道数的降维和升维。
GooLeNet的创新点主要在于inception结构,使得其参数量大约只有7M。相较于VGGNet,分类成功率有所提升,但是在多个迁移学习任务中的表现劣于VGGNet.
后续还有很多网络的提出,例如Inception V2,3,4等,还有待学习。博主本科接触最多的是CNN系列,所以对CNN系列有种莫名的感情~过几天会总结一下faster rcnn和SSD等模型。之后可能会努力两个星期更新一下自己对这些模型的源代码的理解,在此也算是给自己一个督促吧~~
2017.9.15补充
看了看mobilenet的论文,感觉它采用的depthwise separable convolutions(以下简称dw结构)和Inception(以下简称in结构)很像,在此说明两方法的区别:
1.in结构提出主要是因为使用密集成分来近似最优的局部稀疏结构,从而模型A结构提出,但是当特征越来越抽象时,3*3和5*5的filter越来越多,参数量会爆炸,这时需要1*1的filter上场了,用1*1的filter来改变feature map的厚度,参数量减少;dw结构的提出主要就是减少参数量,得到一个更轻型的结构,个人觉得,in中1*1的地位不是老大,是被迫上场的,但是dw中1*1就是其不可或缺的组成部分。
2.用数字来说明。in结构中,1*1的filter已经将feature map的多个channels融合了也就是说它的维度是4维,和3*3,5*5一样的维度;但是dw结构中3*3的filter是三维的,无法融合feature map 的各个channels的信息,只有在1*1中才能融合,这是本质上的区别。
2017.10.27补充
最近课程较多,用 github上一个mobilenet预训练比较好的一个模型,结合ssd算法,自己添加了8个卷积层,也算成功训练起来了,效果目前感觉还不错。以下记录总结一下自己在对mobilenet的prototxt实现的理解和训练的一些的参数设计:
1. dw结构是通过group来实现的,sep层的输出通道数和下一dw层的卷积核个数以及group相等,这意味着每个dw层的每个卷积核只和前一层的一个通道相连接,sep层的1*1的filter实现通道间的融合。有关group参数的理解如下:100x100x32 , 100x100是图像数据shape,32是通道数,要经过一个3x3x48的卷积,group默认是1,就是全连接的卷积层。
如果group是2,那么对应要将输入的32个通道分成2个16的通道,将输出的48个通道分成2个24的通道。对输出的2个24的通道,第一个24通道与输入的第一个16通道进行全卷积,第二个24通道与输入的第二个16通道进行全卷积(在每一个group里面相当于进行group为1的全卷积操作)。极端情况下,输入输出通道数相同,比如为24,group大小也为24,那么每个输出卷积核,只与输入的对应的通道进行卷积。
2. 使用SSD算法时,选了6个不同像素级的层进行一系列“操作”,分别为38*38,19*19,10*10,5*5,3*3,1*1。在训练时有过报错:
Check failed: num_priors_ * loc_classes_ * 4 == bottom[0]->channels() (41424 vs. 27616) Number of priors must match number of location predictions
这是因为mbox_loc层的numoutput设计的不正确,最终可以训练的output是这样的:38*38像素级的output为16,其他均为24.(我检测3类物体)
3. mobilenet每一卷积层后面都跟有bn层和scale层以及relu层,relu层不做赘述,另外两个层理解如下:feature map的batchnormal做了两件事 :
1) 输入归一化 x_norm = (x-u)/std, 其中u和std是个累计计算的均值和方差。
2)y=alpha×x_norm + beta,对归一化后的x进行比例缩放和位移。其中alpha和beta是通过迭代学习的。
那么caffe中的bn层其实只做了第一件事。scale层做了第二件事。这样你也就理解了scale层里为什么要设置bias_term=True,这个偏置就对应2)件事里的beta。所以bn层和scale层一般同时出现。
将pretrain model应用到SSD算法上,有以下几点需要注意:
1. 选取6个左右conv layer,应用于后续的检测,最好都是不同像素级别的(有大有小);
2. 对于每一个conv layer,有两个卷积层(filter参数一般为kernel_size=3,pad=1,stride=1,这样可以保证feature map的大小不变),第一个卷积层mbox_loc层是用来做坐标回归的,故num_output是由default_box*4来确定的,第二个卷积层mbox_conf是用来做分类的,故num_output是由(检测的种类数+1)*default_box来确定的,每个卷积层后跟Permute层和Flatten层,是为了平铺数据,后续更容易操作。mbox_priorbox层是生成default box的操作,根据最小尺寸,最大尺寸以及横纵比来生成,step表示该层的一个像素点相当于最开始输入图像的1/32,简单讲就是感受野,源码里面是通过将原始的input image的大小除以该层feature map的大小来得到的。aspect_ratio=2.0和3.0就是生成6个,aspect_ratio=2.0就是生成3个default box。
3. 最后分别把6个conv layer的mbox_loc,mbox_conf和mbox_priorbox融合,再加上SSD作者的loss层即可,这一部分一般不用修改。
综上,如果mbox_priorbox层生成的default box个数不变的话,就不需要修改这些层的人以参数(检测种类数一定)。
可以参考博客
2017.10.28补充:
感觉mobilenet训练速度太慢了,而且后面训练精度也提不上的感觉,先放一放吧,今天弄了个densenet预训练模型(densenet169)(我用的都是shicai的预训练模型,可以在github上面搜到)。总结一下有以下几点问题:
1. 自行添加了一些层(con+bn+scale+relu),并选取了6个不同的像素层,其中38*38像素层仍然先做normalize,但是此次报错:top blob ‘conv3_blk_norm’ produced multiple sour. conv3_blk是38*38像素级。原因:该层的name和top名称相同,报错,讲name改为conv3_blk_norm_1即可。但是很不理解为什么之前用mobilenet就可以不用改,也不报这个错,搞不清楚。。但是可以明确的是跟着终端报错的信息走,总可以成功训练,哈哈~
2. 成功训练后,终端出现了无数的train net output: …..这是因为 预训练的prototxt后面有pool5和fc6层,但是在结合SSD的时候这两层根本用不上,将这两层删除即可。
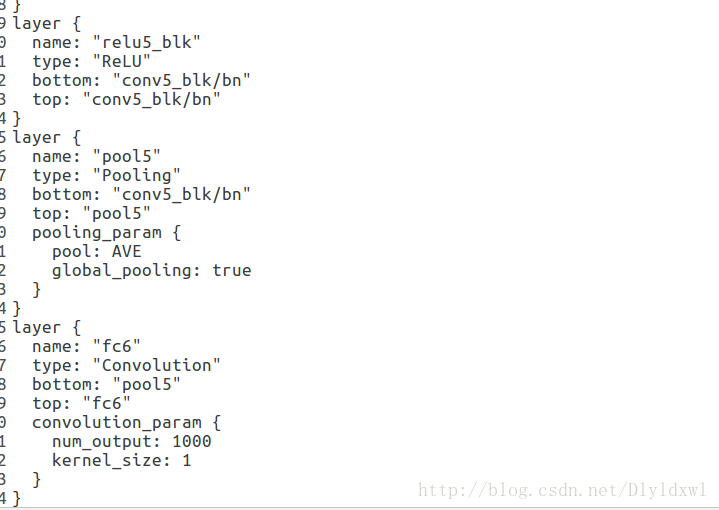
删除了pool5和fc6后,如下图
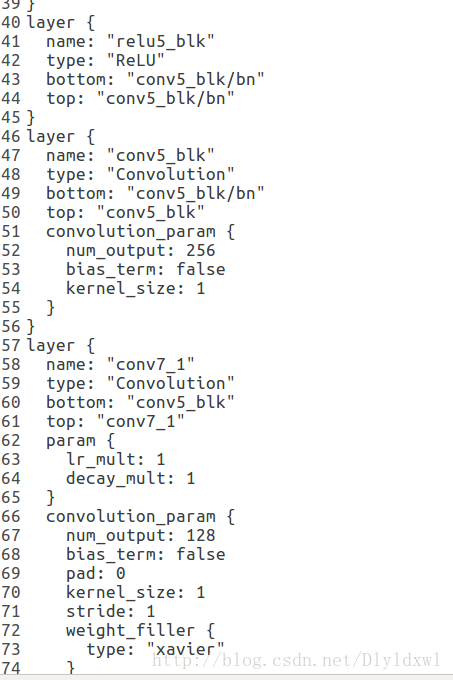
con5_blk是我为了降低con5_blk/bn的“厚度”自行添加的layer,(图中的conv layer没有设置相关的学习率,需要修改。)后面的conv7-1等等是为了获得更低的像素级特征而添加的layer。
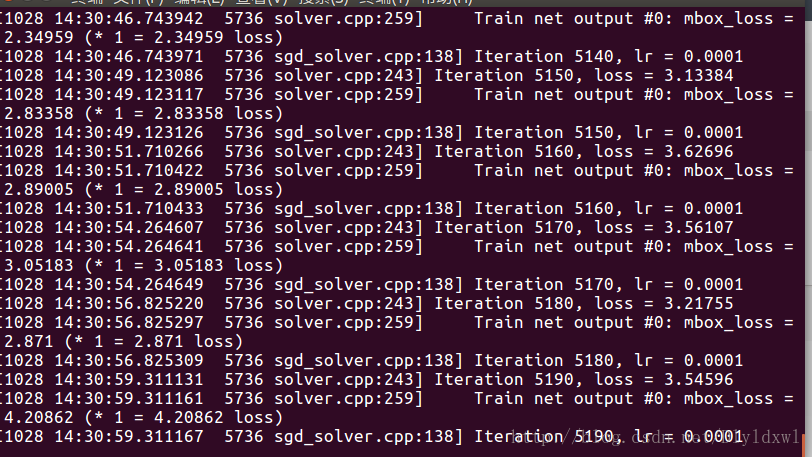
速度确实快了很多。精度还有待调整。。此外,在刚开始训练的时候可以设置记录训练日志,只需要执行语句。
./train.sh 2>&1| tee out.log
PS:densenet是真的烧内存。。titan x,12G现存batch_size设为2才能跑。。先训练个12w代看看效果吧,不行的话过几天再换个SENet预训练模型来试一试。
2017.12.5补充
因为导师要求多,被迫要修改model,稍微读了一下SSD的源码,解答了我心中的一个疑惑:在38*38像素级的conf层中,aspect_radio同样都为2,也就是定义了3个anchor(长宽比为1:1,1:2,2:1),为什么有的output channel为4*class,有的为3*class。下面贴出源码来解释。
SSD的train.pro、test.pro和slover.pro一般都是通过一个.py文件生成的,在生成net的不同像素级的定位和分类信息layer中,会引用这样一个函数:

定位到定义这个函数的文件:Python/caffe/model_libs.py,找到这个函数有关conf层的定义,如下图所示:
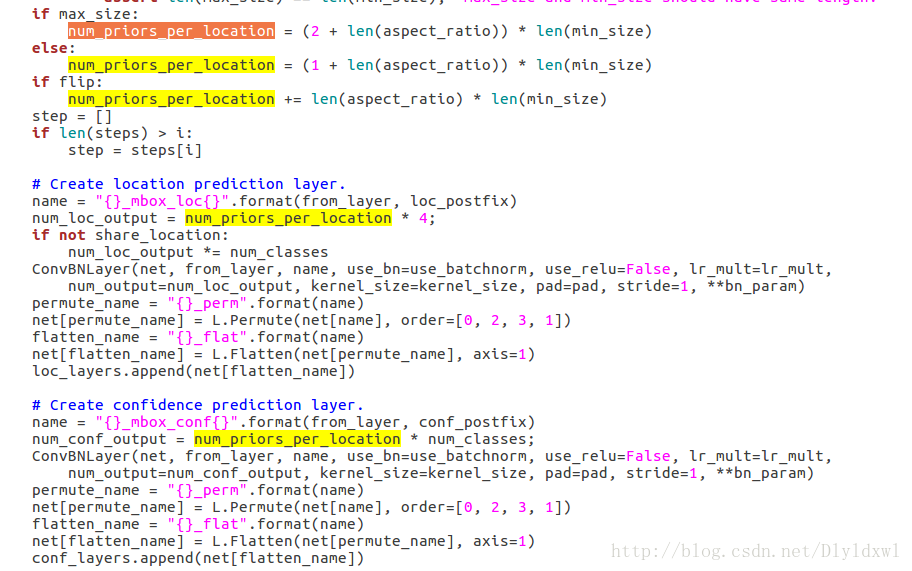
可以看到num_conf_output = num_priors_per_location * num_classes; num_priors_per_location是由aspect_ratio,min_size,max_size,flip来决定的。在作者的finetune_ssd.py里可以算出(或者train.pro里面直接看到),每个像素级的priorbox层定义了这些参数。下图是38*38像素级的priorbox层,max_size=45,aspect_ratio=2 , min_size = 21 , num_priors_per_location = (2+1)*1=3 , flip=true, num_priors_per_location=3+1*1=4,所以num_conf_output = 4*class
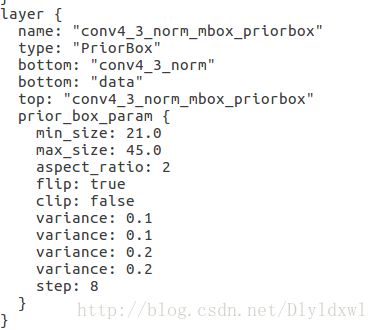
对比github上面的一个mobilenet-ssd的train.prototxt,同样是38*38像素级priorbox层,如下图所示。max_size=0,aspect_ratio=2 , min_size = 60 , num_priors_per_location = (1+1)*1=2, flip=true, num_priors_per_location=2+1*1=3, 所以num_conf_output = 3*class

同样也能回答为什么其他像素级的conv layer的output channel为6*class 了。
总结一句话:有问题去翻源码。














 9982
9982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









