







目录
1.引言
1.1算法的个人印象
所谓小马过河是摸着石头过河,而所谓梯度下降,就是探着山坡下山。“下山本没有路,探过的山坡多了,便有了路”(doge)。
咳咳~,严肃点。
机器学习的一种算法,目的是求函数的最小值,特点是通过梯度下降的方法找最小值,前提是初始位置和步长(学习率)确定。当然这里还是附个图印象更深(嫖的图)。

1.2为什么用这个算法
1.刚才已经说过,该算法的目的是求函数的最小值。
2.该算法在深度学习中应用广泛,在最小化损失函数函数和线性回归等问题中都需要用到该算法。(不知道比喻是否恰当,我想就像格林公式对于多元函数积分问题的重要性一样)
3.很多已经对该算法由颇深了解的大佬已经会认为这是理所当然,但作为一个小白,我其实并没有被以上两点所说服。既然求函数最小值,那直接求不就行了,高数不都学了,就算计算量大,那也可以用计算机算对吧?为什么有这个算法,后来想想,我确实是个傻叉。对于求函数的最小值,如果按书上的知识结合技巧来求,也许确实很快,但每个不同类型函数的最小值的求法不同,那么求法不一,程序也就千变万化,而该算法恰恰就是一个通用的算法,可以对任意函数求最小值(尽管是接近的),就是说我所不明白的点是该算法对于求任意函数最小值的通用性。
2.梯度下降算法
2.1场景设定
我们把梯度下降比作人下山的场景。
话说一位爬山爱好者爬到了山上,突然天空乌云密布,山上大雾重重,于是他不得不下山。然而由于大雾,山上能见度较低,无法确定长久的路径,所以他只得充分利用周围的信息来探索出下山的路。
首先,他以当前位置为基准,疯狂试探,找到了最陂的地方,然后顺着这个方向往下走两步,然后,他又以当前位置为基准,疯狂试探,又找到了最陂的地方,反反覆覆,最终下了山。

2.2梯度下降
梯度下降就如这下山一般。
我们把山看作一个函数,这人就是函数上的一个点,我们的目的是使人走到函数的最低点。开始的时候,人在的位置称为当前的初始点,我们需要找到该点的梯度,然后顺着梯度的反方向下降,到达下一个点,此时当前初始点变化,接着找当前点的梯度,直到函数最小值。
有梯度下降,我们想也有梯度上升吧,当然梯度上升就是上山。
2.2.1梯度
我们反复说到的梯度是什么?初学该算法的我,掏出来积灰已久的高数书,哦,我竟然学过。
对于一元函数,梯度就是函数在该点导数的值。
对于多元函数,梯度就是函数在该点对每一个变量求导的值组成的向量。
三位坐标中,函数的梯度表示:
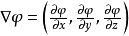
举个计算例子(嫖的):
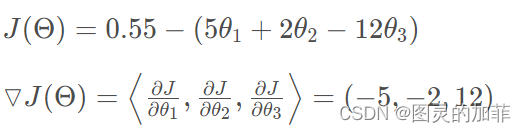
2.2.2梯度指出了定点上升的最快方向
在下山的时候,那位大佬每走几步就要疯狂试探,寻找当前位置最陡的坡,而梯度的反方向恰好就是最陡的那个坡,指出了函数下降最快的方向。
这里就不再证明为什么了,打字不易,请看高数书。
ps:这里又嫖了个图。
2.3数学解释
2.3.1 核心公式:
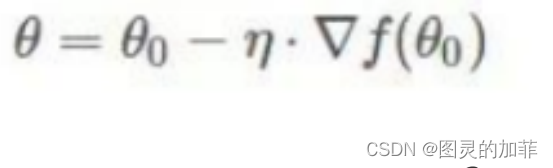
解释:f是关于Θ的一个函数,(Θ是函数上一点的坐标,比如(Θ=(x,y,z))),Θ0是初始位置,η是步长(后有解释),η后面乘了Θ0的梯度,Θ是下降后的位置。整个函数描述了下山的一个循环过程,确定初始点,求出初始点的梯度,下降相应步长,到达下一个点。
2.3.2 η
在梯度下降算法η中被称作为学习率或者步长,意味着我们可以通过η来控制每一步走的距离,以保证不要步子跨的太大扯着蛋,哈哈,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以η的选择在梯度下降法中往往是很重要的!η不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!
2.3.3 怎么停下来——阈值/迭代次数
其实不难发现,梯度下降求出的最小值只是接近实际最小值,就像下山一样,我们不是非要到山最低处,我只要看一眼“欢迎下次再来”的标语,就知道我们下山了。那么,梯度下降求出的最小值有多小才能看作是最小值呢?
1.我们可以定个阈值,当(Θn - Θn-1)的绝对值=步长*Θn的梯度 < 阈值时,我们将认为求出来最小值。
2.我们定个迭代次数,当程序循环次数达到该迭代次数时,我们认为求出了最大值。
2.4 梯度下降法的一般步骤
1.对于给定函数,求偏导数
2.确定初始值,步长,阈值或迭代次数
3.进行循环,判断是否满足结束条件
2.5实例
用梯度下降法求给定一元函数的最小值。(这里非常不好意思的嫖了学长的实例)
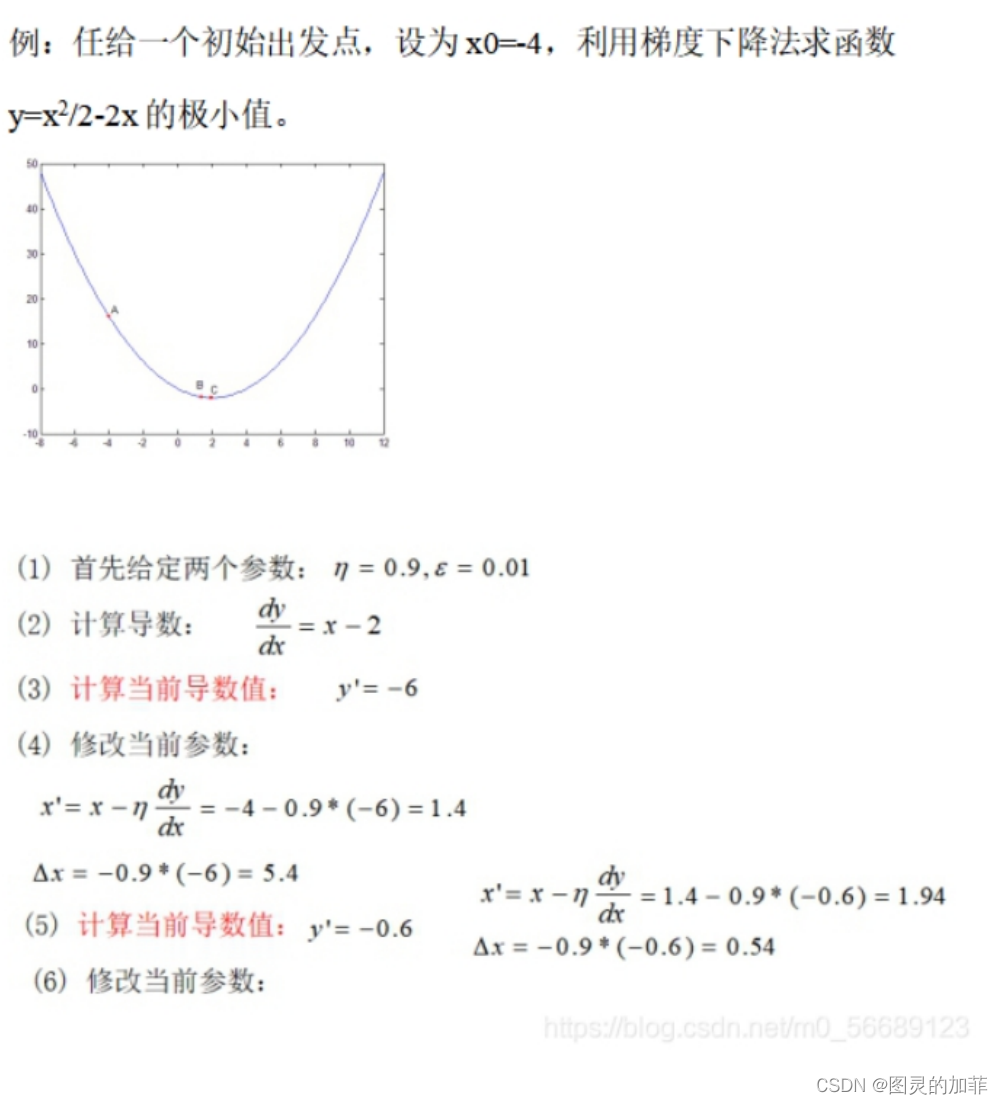

3.简单代码
#引用库
import numpy as np
#定义原函数 f(x) = x^2
def f(x) :
return np.power(x,2)
#定义原函数求导公式1
def d_f_1(x) :
return 2.0 * x
#定义原函数求导公式2
def d_f_2(f,x,delta = 1e-4) :
return (f(x+delta)-f(x-delta)) / (2 * delta)
xs = np.arange(-10,11) #限制变量x的范围
learning_rate = 0.1#学习率
max_loop = 30#迭代次数
x_init = 10.0#x初始值
x = x_init
lr = 0.01#ε值,不过我们下面用的是迭代次数限制
for i in range(max_loop) :
#修改参数
d_f_x = d_f_2(f,x)
x = x - learning_rate * d_f_x
print(x)
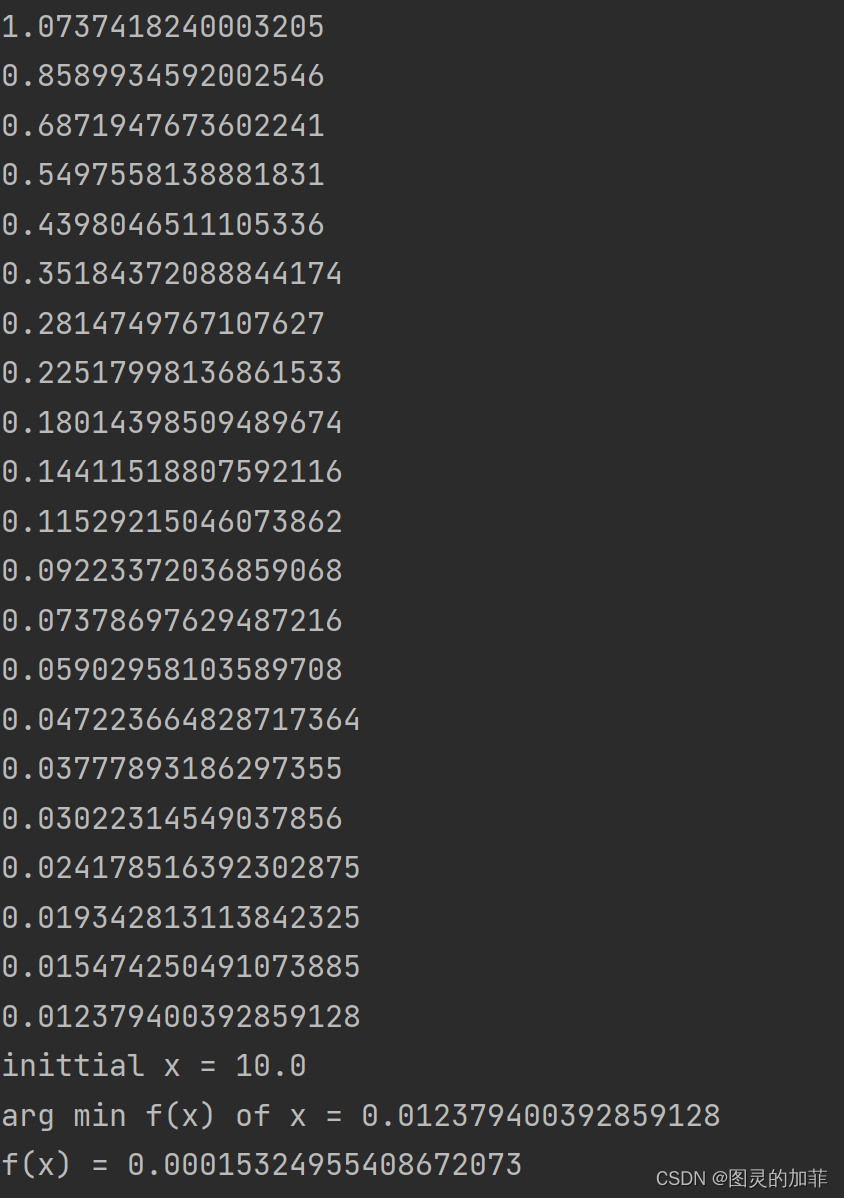
print('inittial x =',x_init)
print('arg min f(x) of x =',x)
print('f(x) =',f(x))效果:














 2375
2375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









