






关注我的小伙伴都看过我之前的这篇python拼接全景图的文章:
关于Python全景图像拼接的探索和实践(其中包括对Opencv Stitcher类、PhotoShop MergeImage插件、PTGui Pro12全景图拼合软件的一些横向比较和探究) https://blog.csdn.net/donglxd/article/details/137228325 在这篇文章中,我们很好的利用了python的opencv视觉开源库中的sift算法,编写了可以拼合多张图片的拼接代码,在我们测试的大多数正常情况下,这个拼接代码都比较好的完成了任务,但是作为主例子的test1图片中,第3和第4张图片拼接时会有bug,具体就是使用我的矩形对角线过渡时,会有所谓的鬼影存在,当时我是通过设置一个手动计算的对角线绕过了鬼影部分解决了这个问题,后来有网友在和我聊天的过程中,说了他在360°全景拼接时,也碰到了这样的鬼影问题。
https://blog.csdn.net/donglxd/article/details/137228325 在这篇文章中,我们很好的利用了python的opencv视觉开源库中的sift算法,编写了可以拼合多张图片的拼接代码,在我们测试的大多数正常情况下,这个拼接代码都比较好的完成了任务,但是作为主例子的test1图片中,第3和第4张图片拼接时会有bug,具体就是使用我的矩形对角线过渡时,会有所谓的鬼影存在,当时我是通过设置一个手动计算的对角线绕过了鬼影部分解决了这个问题,后来有网友在和我聊天的过程中,说了他在360°全景拼接时,也碰到了这样的鬼影问题。
我上网搜索了下,鬼影和重影问题是拼接时经常发生的问题,原因有几点:
1.拼接算法的匹配度的问题,如果两张图片拼接的不正确,他们中间重叠的部分,因为有羽化之类的算法过渡,所以会出现不匹配的残影,在羽化过渡的部分,这种情况发生的最明显。这个问题,在有特别明显边界的物体上最突出,如下图所示:

因为我的拼接算法是从左至右的,所以越往右,形变越厉害,拼接的单应性矩阵变换的幅度越大,图片边缘的拼接误差越大 。在融合两张图片的重叠部分就会产生错位的鬼影。
2.拼接时,有移动的物体,左图和右图的物体位置有差异时,也会出现鬼影,如下图:
那么,怎么解决鬼影问题?其实这个问题是一个图像拼接上的老问题了,在很早以前就开始有人尝试解决这个问题,时至今日的AI时代这个问题还是不能很好的解决,经过一阵论文搜索,扒出一篇比我儿子年纪还大的论文,是一个日本人于2010年写的论文(Yu Tang, Jungpil Shin. De-ghosting for Image Stitching with Automatic Content-Awareness. Pattern Recognition (ICPR), 2010 20th International Conference on 23-26 Aug. 2010 2210 – 2213.),看完翻译后,我终于对日本人英文不好有了深刻的认识,一句话有N个"for"和"of",就像人家写作文不写逗号一样,看着很累,但是有一说一,我们知道日本人的软件技术还是很厉害,只是现在被阿三超过了。
因为我的代码基本就是复原了这篇论文,所以需要简单介绍下这篇论文的总体思路,首先,他这篇论文的一个前提是他是架设了相机支架拍摄的,这点请注意,所以他的拼接质量可以非常高,他使用了左右各拍三张不同曝光的照片,通过他的亮度融合算法,生成左右两张曝光合适的,类似HDR技术的堆栈曝光融合图片,如下图:
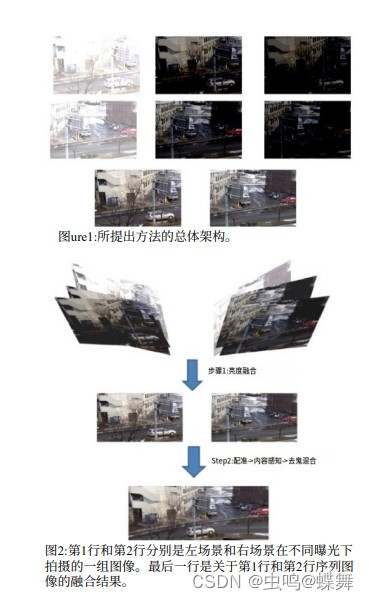
那么大家会很奇怪,他为什么要这么麻烦的拍三张曝光的照片?其实他的这个算法就是建立在左右两张图片曝光需要相对一致的情况下,才能有比较柔和融合效果的,这个问题我会放到后面讲。
这个日本人最大的创新就是下面讲的内容:能量图和突出图的标注问题。可能有人需要问了,拼接两张图片需要这么麻烦吗?我可以很明确的告诉你,使用程序自动处理鬼影很麻烦,而且如果你想适配所有的情况很难 ,不说题外话了。接着讲,为什么需要能量图和突出图,因为就像我之前写的拼接程序一样,我们需要绕开鬼影部分,挑一些不明显的、没主要物体的地方下刀融合(请参阅我之前的图像拼接博文),所以我们需要使用梯度图制作的能量图,标注图片拼接时,重叠部分的显著物体,而显著物体对于计算机而言就是一些像素点,根据作者的算法,就是先计算出左右两图的拼合后的重叠部分,这样就得到左图的重叠(i1)和右图的重叠(i2),然后把两者相减得到一个两者的差值图,里面包含了拼接图的差异部分(鬼影),是不是很奇妙,我当时也没想到简简单单的减法就能提取出鬼影,顺便说一句这个思路,不是这个日本人想出来的,是我们沈阳的东北大学软件学院的作者比他早一年写的。如下图(此为翻译图片,Yu Tang, Huiyan Jiang. Highly efficient image stitching based on energy map. CISP’09 , pp.1-5, Oct. 2009.):

当然了,日本作者也是引用了这篇论文,有兴趣的朋友可以去看看(PS:和以前一样,所有的相关资料和论文、翻译我都会上传CSDN) ,说回日本作者的突出图的问题,因为我们的鬼影已提取出来,但是就如同下面的效果:

可以看到图片是彩色的,因为我们是做的三通道差值计算,很好的把鬼影都分离出来了,但是里面有很多噪声干扰(其实就是两张图片拼接时没有完整对齐的部分),所以老外提出了下面的一些算法,通过特定的阈值控制噪声,并标注出显著点与邻域点,如下图:

可以看到下面的图片里,左边第一张,先通过全局平均对比度(Lab图像空间)与阈值st找到零散的显著点,然后以显著点为圆心做半径R的邻域,所以邻域的面积就是(2R+1,2R+1)的正方形,然后做3种半径的邻域效果并取最大那个半径邻域,当然这个邻域也是有阈值控制的,就是把2R+1面积的邻域计算lab空间的均值与邻域的阈值dt比较后,大于阈值的标注邻域点。
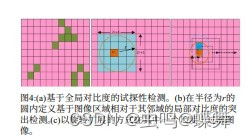
论文中的标注例子如下:

可以看到图片中的艺妓被很好的突出显示,第一、二行的第三张图片比较黑是梯度图,拼接线如论文所述不能很好的绕开艺妓主体。
说明了老外的思路后,我们再来说说沈阳的作者发现的拼接线算法。两人差别就是我们使用了梯度图,而老外使用了突出图,但是在中国的作者唐煜的拼接线算法却是拼接算法的主要部分,因为唐没有使用突出图也实现了比较好的去除鬼影图片,同时他使用了Alpha通道的拉普拉斯融合图片,并尝试了复杂的GIST1全局融合算法,最后选择了计算比较快的质量可以的拉普拉斯融合,日本人也是使用了这种融合算法。
回到拼接线算法上来,唐使用了贪心算法来计算拼接线,读取他之前计算的梯度能量图后,找出每行的最小能量点,然后连接起来,具体算法如下:

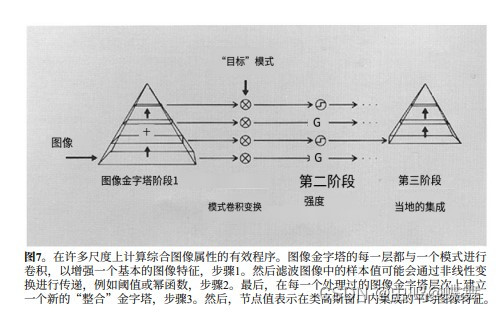
最后说下Alpha通道的拉普拉斯融合,这也是个老算法了,应该比我的年龄都要大了,研究这个方向的作者一大堆(E. H. Adelson | C. H. Anderson | J. R. Bergen | P. J. Burt | J. M. Ogden),论文也有一堆,讲的比较详细的是这篇Pyramid methods in image processing(E. H. Adelson | C. H. Anderson | J. R. Bergen | P. J. Burt | J. M. Ogden),总体思路就是先建立逐步缩小分辨率的高斯金字塔(每次减小一半),然后拉普拉斯金字塔则通过从金字塔的下一层级中减去每个高斯金字塔层级来获得,并且最小的顶层就是高斯金字塔的顶层,然后再从最小的顶层拉普拉斯上采样重建回来。如下图所示:
1.高斯金字塔:

2.拉普拉斯金字塔(因为也是差值运算,所以保留了上层的细节):
 3.重建过程(中文机翻):
3.重建过程(中文机翻):
因为左右有两张图,还有Alpha通道的掩模图,所以实际有三张图需要分别建立高斯金字塔、拉普拉斯金字塔,然后把左右的拉普拉斯金字塔,根据掩模图的拉普拉斯金字塔,每一层都做融合处理,生成新的融合拉普拉斯金字塔,最后就是还原处理,最终结果如下,苹果橘子合体图:

所有的算法来龙去脉讲清了,现在来说说我的程序。先看看效果:
test1效果对比:

test2效果对比:

在test1的效果对比图中,可以看到我的代码解决了之前帖子中手动调整拼合线的问题,现在可以自动完成了,同时这个图里的物体都是相同的。
在test2的效果图中,可以看到右图有一个小椅子,这是左图中没有的,但是这个椅子的位置在左右两图的重合位置,所以按照一般的算法会产生鬼影,但是我的代码处理后,基本完美拼接,并显示了小椅子。
现在来说说我的开发过程吧!参考了日本人的例子后,我先尝试编写了显著点和邻域点标注的问题,这是算法之重,通过GPT的帮助和自己的不断调试后,基本编写成功,达到老外90%的效果,如下图:
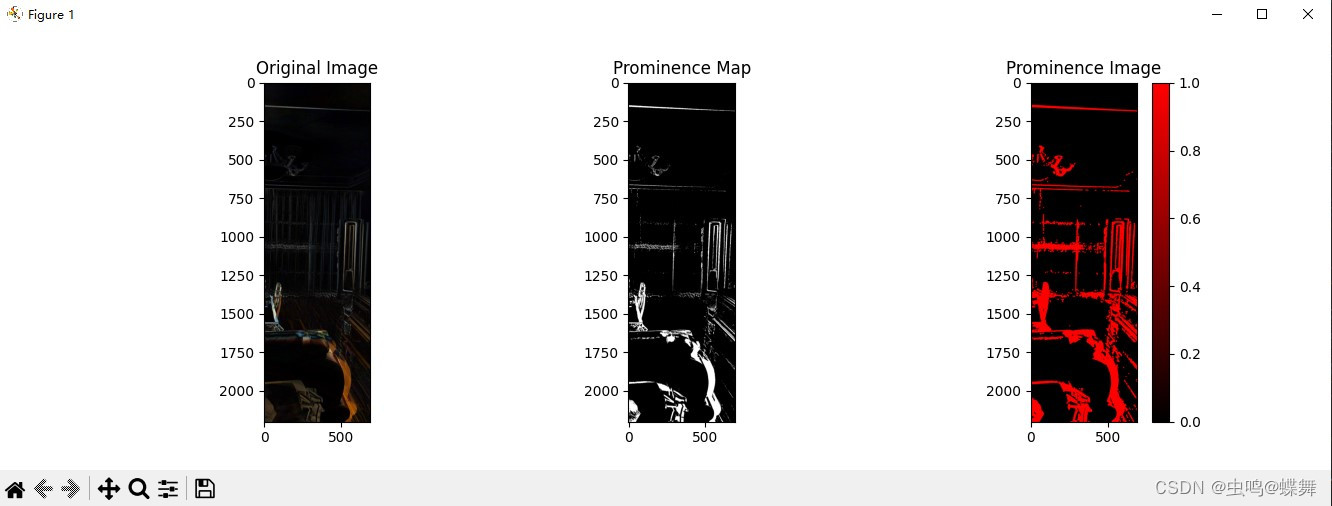
剩下的10%有一大半是再调试显著点阈值ST和邻域点ET中不停试错,如下图的大量尝试:

而且因为刚开始编写,代码没有优化,所以计算邻域极慢,通常一张图片要等3-4分钟左右才能出结果,早知如此,当时就下决心,好好研读论文,优化好代码再试, 太依靠GPT只能失败。因为GPT差点把我气死,所以再认真读了一遍又一遍论文,检查每个步骤后,总算输出了上面的邻域效果,当时试的就是艺妓的图。

就是在这张艺妓图中,不停尝试两个阈值后,发现还是需要做个自动调整阈值功能,所以最终的程序中我做了自动和手动两种功能,大家可以优先使用自动的,不行再慢慢调手动阈值,如下图:
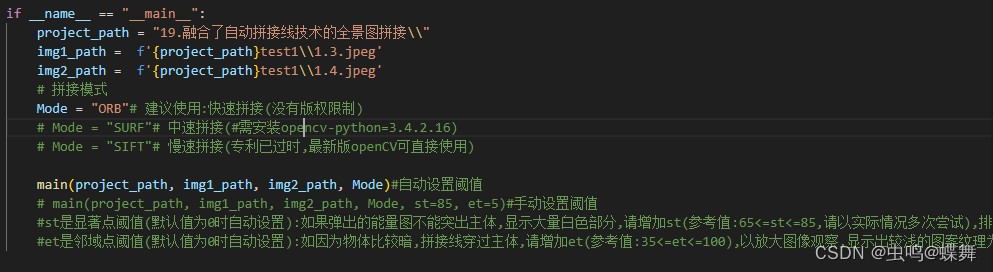
上图中,main(project_path, img1_path, img2_path, Mode)这行就是自动调整阈值的代码,默认就是这个,下面的那行就是手动的,需要时,把自动这行注释就成,把手动的代码main(project_path, img1_path, img2_path, Mode, st=85, et=5)取消注释后,里面的显著点st和邻域点et就是手动设置,st和et的值越大,显著点和邻域点越少,如果碰到上面的3个能量图中显示了太多的噪声,可以适当增大阈值,程序的消息输出中,有自动阈值时的值可以供参考调整。
然后说说自动拼接线的编写,我使用了唐煜的第一种动态规划的算法,实际运算时间估计也就3秒以内,还能接受。使用了之前邻域点生成的能量图,代入到自动拼接线函数中计算,效果如下:

上面的效果图中,绿线就是拼接线,可以看到它比较准确的绕过了左上的吊灯,右边的空调和复杂的地板,从下方不明显的沙发接缝中通过,首先我要说明一点,这个只是一个简单的动态规划算法,规划的方针是从上向下的(我也写了从下向上的代码,具体见代码中的注释)最大化的避开复杂的重叠图的大量鬼影(白色部分都是鬼影,有一些明显,另一些不明显,拼接线从全局层面绕开了主要的鬼影),但是大家也看到了,有时拼接线避无可避,只能穿过一些鬼影部分,尽量从纵向最小总和能量的路径规划。
最后,关于alpha通道的拉普拉斯的算法,我参考了 这篇c++的拉普拉斯算法改写python版本的,谢谢这位作者的免费分享。
【OpenCV 学习笔记】—— 基于拉普拉斯金字塔的图像融合原理以及C++实现【或许是全网最通俗易懂的讲解】https://blog.csdn.net/weixin_44586473/article/details/105893478如下我的拉普拉斯融合效果图:

我在代码中设置了调试debug开关,用于在每一步拉普拉斯融合中,调试查看图片使用,默认是关闭的(False),设置成True可以查看每一步计算效果(注:打开开关后,会弹出每一步的效果图片,如上面的,而且会弹出比较多的图片,只要关闭就能进入下一步的图片,另外需要注意的是,不要在弹出图片的时候终止程序运行,这样的话会打不开图片,如死机的状态,这时只要把代码中的imshow的图片名称改一下就行了,所以,如不是调试需要,请不要打开这个开关),如图debug开关:
我把整个Alpha通道的拉普拉斯融合做了一张图,方便大家理解,如下:
最终生成的融合图如下:
顺便说一句,刚刚的调试debug开关开启后,会缩小输出图片的尺寸为600*600 ,所以此开关只供调试使用,如需原图大小输出,请设置如下:
# 如需直接输出原图拉普拉斯融合,请把Debug=False
blender = ImageBlender(Debug=False)还有如需使用我的程序,请设置如下3条代码的路径和图片名称(project_path表示图片的主目录,最好把这个目录设置成绝对路径,比如"C:\\project\\",如和我一样是VSCode调用把代码文件夹添加到VSCode项目空间后,右击文件夹复制相对路径后,粘贴到这个project_path变量后,注意所有路径都需双斜杠,img1_path表示左图路径,img2_path表示右图路径,以自己图片的路径设置,请不要搞错左右图的顺序,不然输出结果会在左图中缺失一大块图像内容,而变成黑色):
 程序的开头有一个debug开关控制一些详细调试消息的输出,默认关闭(False).
程序的开头有一个debug开关控制一些详细调试消息的输出,默认关闭(False).

if __name__ == "__main__":
project_path = "19.融合了自动拼接线技术的全景图拼接\\"
img1_path = f'{project_path}test1\\1.3.jpeg'
img2_path = f'{project_path}test1\\1.4.jpeg'
# 拼接模式
Mode = "ORB"# 建议使用:快速拼接(没有版权限制)
# Mode = "SURF"# 中速拼接(#需安装opencv-python=3.4.2.16)
# Mode = "SIFT"# 慢速拼接(专利已过时,最新版openCV可直接使用)
main(project_path, img1_path, img2_path, Mode)#自动设置阈值
# main(project_path, img1_path, img2_path, Mode, st=85, et=5)#手动设置阈值
#st是显著点阈值(默认值为0时自动设置):如果弹出的能量图不能突出主体,显示大量白色部分,请增加st(参考值:65<=st<=85,请以实际情况多次尝试),排除多余显著点
#et是邻域点阈值(默认值为0时自动设置):如因为物体比较暗,拼接线穿过主体,请增加et(参考值:35<=et<=100),以放大图像观察,显示出较浅的图案纹理为佳
另外上面代码中的Mode一共有3种模式,分别对应了ORB、SURF、SIFT拼接模式,ORB和SURF在最新版的opencv-python中直接可用,SURF需退回版本opencv-python=V3.4.2.16 ,请注意。
关于3种拼接模式,我个人认为平时使用ORB即可,不行再尝试比较慢的SIFT,因为ORB是改进了SIFT的快速拼接模式,效果应该还行。
我来说下这个算法的缺点吧!这个算法最大的问题是:需要输入的左右两张图片的全局对比度一致,不然会有比较明显的过渡,我尝试了下平均两张图片的梯度,即把平均对比度较高的图片做基准,改变另一张图片的梯度,但是效果不好,这也是我文章开始处说的,日本人为什么需要架设相机并做HDR堆栈融合的原因。显然这个问题并不太好解决,在唐的论文里,有提到GIST1的计算全局梯度融合的方法,我会把论文上传供大家继续研究。本来我想继续弄下去的,但是最近需要外出,而且托更了好久了,所以就先留个遗憾,下次有机会再解决。
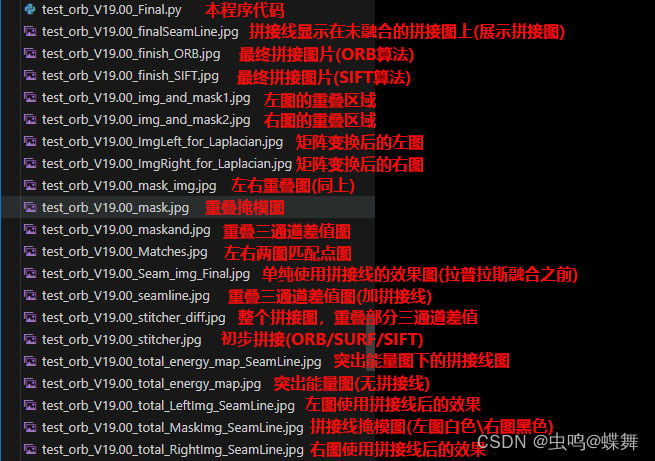
然后我下面的两张图说明了程序开头的debug开关后,输出的一些调试图片的说明,供大家参考(注:可以看到我的代码迭代版本已经到了V19.00,至于其他的分块功能的版本加起来就更多了):

接着说一下这类算法的优化和改进方向,我交叉引用查询了下,引用日本人的论文的人,发现近几年来还是有人在改进的,比较突出的方向是人工智能代替突出图,来标注显著的物体,主要使用了AI算法来实现物体的识别和标注(Image Stitching focused on Priority Object using Deep Learning based Object Detection Seongbae Rheea), Jeonho Kanga), and Kyuheon Kima)),具体使用了YOLACT(You Only Look At CoefficienTs)的神经网络识别算法(https://github.com/dbolya/yolact),如下图:

并通过智能识别,把不同重要等级的物体,标记不同的权重,如下:

因为使用了神经网络算法,所以他使用了RTX-2080的显卡计算,这样计算的门槛就会很高。

同时他也说明了他算法的一些问题,因为受限于ORB算法的拼接效果,比如中间的灯柱拼接的很好,但是远处的岸边水平拼接的不对。

还有一些新的相关论文我也会上传CSDN,比如动态缩放纵横向图片,用于网站对不同客户端设备的适配问题等图像算法。
写在最后,我要聊一聊,我的代码分享策略的问题,这个自动拼合图片的代码零零碎碎花了我差不多一个月的空闲时间编写,我的这篇博文中其实并没有放上实质性的代码,说的都是理论上的问题,有人可能说我在水文,其实我认为不然,进入AI时代以后,ChatGPT之类的软件把以前码农的编写基础代码的工作都做了,让程序员可以专注于算法上的研究,而不是辛苦的累码,编程的效率大大提高,要是以前,我的这个程序没有2个月应该编不出来,不要小看上面简单的算法,其实背后的复杂只有我自己知道,我为了程序写的不是很乱,所以每个功能都是分开测试的,然后把每个功能写成类拼接在一起,所以把每个类单独拆分开也可以运行,当然也有部分函数是参照以前的代码,这部分的代码大概有10%左右,都是一些基础的功能函数,可以给程序的每个类共用,比如中文路径的读取和保存图片、读取图片的角点等我就不一一说明了。说了这么多,只是想说明一点,我是在用心编写代码,本来我是想免费分享给大家的,但是我的妻子提醒了我,我研究了这么长时间的代码,需要转换成经济价值,因为现在所有的平台、所有人都是这么做的,这样才能产生出我的劳动价值,我也可以有动力继续把CSDN的博客做下去,因为编写的这个代码占用了一整个月的业余时间,我需要白天工作、晚上照顾孩子和家庭的同时,还要编写代码。所以我的妻子劝我能转换下思路,不要做没有价值的程序,可能这篇文章的阅读量只有1000不到,也可能没人下载我的程序,我都不会有怨言,因为这就是商业社会,劳动产生价值,是金子总有会发光的一天。虽然我只是想做一个普普通通的开源编程爱好者,但是社会和家庭不喜欢这样,所以这也是我作为一个近40岁的IT的无奈,综上所述,之后我的博文还是只要关注,就能免费阅读,这点暂时我是不会改变的,我也不会设置专栏订阅这样的门槛给大家,甚至会定期写一些小的脚本免费提供给大家学习,但是今后如果碰到比较大、耗时比较长、实用意义比较大的程序,我会象征性的收取一些费用,因为我也是第一次这样尝试,所以定价我会斟酌一下,因为大家都不容易,当然了,如有实际困难的,又对我的代码感兴趣的朋友,也可以联系,我会视情况而定提供代码。大家如果有什么问题,可以私信我,我看到一定会回答,谢谢大家的观看,下回见!
文末是项目的所有文件的打包链接:



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











