







之前被要求做一个和图像拼接的项目,学习了图像拼接的原理和实践,在这里记录一下,包括基本的原理和用python写出的代码。
图像拼接,顾名思义,就是将两张或多张图像拼接一起,其关键就是找到两张图像的重叠部分,通过重叠部分实现拼接。
所以,关键可以概括为两部分,一是如何找到重叠部分,在图像处理中称为特征点的提取和匹配;二是根据重叠部分来叠加图像,将右图根据重叠部分覆盖到左图上。
拼接的步骤
1.对每幅图做特征提取,再对两幅图做特征匹配。
2.图像配准及误匹配点的去除,即根据匹配的特征点找出重叠部分的对应坐标,并求出对应坐标转换的矩阵homography。
3.根据转换矩阵将右图拷贝到左图的指定位置上。
4.对重叠的边界做特殊处理,如平滑处理、去裂缝处理、过渡等。
特征点提取算法:
(1)SIFT算法:尺度不变特征转换
(2)SURF算法:加速稳健特征
(3)ORB算法
它们都具有尺度不变的特征,即两幅图像中不同尺度的同一物体点,两个尺度因子之间的比率应等同与图像尺度的比率。
特征点即为关键点,一般为角点、边缘点、暗区域的亮点、亮区域的暗点、局部极值点。
SIFT为最基础的算法,SURF和ORB都是在SIFT的基础进行修改,提升了运算的速度。
特征点匹配算法:
(1)BF算法
(2)FLANN算法
使用python和opencv库函数实现
ORB算法:
# ORB
def orb_extract(img1, img2):
orb = cv2.ORB_create(10)
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# BF
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
key_number1 = len(kp1)
key_number2 = len(kp2)
match_number = len(matches)
max_number = np.maximum(key_number1, key_number2)
score = float(float(match_number) / float(max_number))
img_orb = cv2.drawMatches(img1, kp1, img2, kp2, matches[:50], img2, flags=2)
return img_orb, score
SURF算法:
# SURF
def surf_extract(img1, img2):
surf = cv2.xfeatures2d.SURF_create(100)
# surf.setHessianThreshold(10000)
# SIFT:cv2.xfeatures2d.SIFT_create()
# SURF:cv2.xfeatures2d.SURF_create(hessianThreshold, nOctaves, nOctaveLayers, extended, upright)
key1, describe1 = surf.detectAndCompute(img1, None)
img11 = cv2.drawKeypoints(img1, key1, img1, color=(255, 0, 0))
key2, describe2 = surf.detectAndCompute(img2, None)
img12 = cv2.drawKeypoints(img2, key2, img2, color=(255, 0, 0))
# FLANN
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
match = flann.knnMatch(describe1, describe2, k=2)
key_number1 = len(key1)
key_number2 = len(key2)
match_number = len(match)
max_number = np.maximum(key_number1, key_number2)
good = []
for m, n in match:
if m.distance < 0.75 * n.distance:
good.append([m])
# print("m:", m)
good_number = len(good)
# print("good:", good_number)
score = float(float(good_number)/float(max_number))
img_surf = cv2.drawMatchesKnn(img1, key1, img2, key2, good, None, flags=2)
return img_surf, score
SIFT算法:
def sift_extract(img1, img2):
# SIFT
sift = cv2.xfeatures2d.SURF_create(100)
key1, describe1 = sift.detectAndCompute(img1, None)
img11 = cv2.drawKeypoints(img1, key1, img1, color=(255, 0, 0))
key2, describe2 = sift.detectAndCompute(img2, None)
img12 = cv2.drawKeypoints(img2, key2, img2, color=(255, 0, 0))
# FLANN
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
match = flann.knnMatch(describe1, describe2, k=2)
key_number1 = len(key1)
key_number2 = len(key2)
match_number = len(match)
max_number = np.maximum(key_number1, key_number2)
score = float(float(match_number) / float(max_number))
img_sift = cv2.drawMatchesKnn(img1, key1, img2, key2, match, None, flags=2)
return img_sift, score
特征提取和匹配的主函数:
def main():
img1 = cv2.imread("a.PNG")
img2 = cv2.imread("b.PNG")
img3, score_orb = orb_extract(img1, img2)
plt.subplot(311), plt.imshow(img3),
plt.title('ORB'), plt.axis('off')
img4, score_surf = surf_extract(img1, img2)
plt.subplot(312), plt.imshow(img4),
plt.title('SURF'), plt.axis('off')
img5, score_sift = sift_extract(img1, img2)
plt.subplot(313), plt.imshow(img5),
plt.title('SIFT'), plt.axis('off')
print("surf:", score_surf)
print("sift:", score_sift)
plt.show()
if __name__ == "__main__":
main()
效果:
 SIFT算法的特征点一般都是最多的。
SIFT算法的特征点一般都是最多的。
图像拼接的最大难度应是特征点的提取与匹配了,这里就详细介绍这个部分,其余步骤可大概了解。
这里附上图像拼接的全部代码:
# 图像拼接
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
import time
MIN = 10
start_time = time.time()
m1 = cv.imread('a.PNG')
img2 = cv.imread('b.PNG')
height2 = int(img2.shape[0])
width2 = int(img2.shape[1])
dim = (width2, height2)
img1 = cv.resize(m1, dim, interpolation=cv.INTER_AREA)
gray1 = cv.cvtColor(img1, cv.COLOR_RGB2GRAY)
gray2 = cv.cvtColor(img2, cv.COLOR_RGB2GRAY)
print('img1 Dimensions : ', img1.shape)
print('img2 Dimensions : ', img2.shape)
plt.imshow(img1, ), plt.show()
plt.imshow(img2, ), plt.show()
# SURF
surf = cv.xfeatures2d.SURF_create(10000, nOctaves=4, extended=False, upright=True)
gray1 = cv.cvtColor(img1, cv.COLOR_RGB2GRAY)
gray2 = cv.cvtColor(img2, cv.COLOR_RGB2GRAY)
kp1, describe1 = surf.detectAndCompute(gray1, None)
kp2, describe2 = surf.detectAndCompute(gray2, None)
# FLANN
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
searchParams = dict(checks=50)
flann = cv.FlannBasedMatcher(indexParams, searchParams)
match = flann.knnMatch(describe1, describe2, k=2)
good = []
for i, (m, n) in enumerate(match):
if m.distance < 0.75 * n.distance:
good.append(m)
##################################
# RANSAC:findhomography
if len(good) > MIN:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
ano_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
M, mask = cv.findHomography(src_pts, ano_pts, cv.RANSAC, 5.0)
warpImg = cv.warpPerspective(img2, np.linalg.inv(M), (img1.shape[1] + img2.shape[1], img2.shape[0]))
direct = warpImg.copy()
direct[0:img1.shape[0], 0:img1.shape[1]] = img1
simple = time.time()
###################################
# cv.namedWindow("Result", cv.WINDOW_NORMAL)
# cv.imshow("Result",warpImg)
rows, cols = img1.shape[:2]
left = 0
right = cols
for col in range(0, cols):
if img1[:, col].any() and warpImg[:, col].any(): # 开始重叠的最左端
left = col
break
for col in range(cols - 1, 0, -1):
if img1[:, col].any() and warpImg[:, col].any(): # 重叠的最右一列
right = col
break
res = np.zeros([rows, cols, 3], np.uint8)
for row in range(0, rows):
for col in range(0, cols):
if not img1[row, col].any():
res[row, col] = warpImg[row, col]
elif not warpImg[row, col].any():
res[row, col] = img1[row, col]
else:
srcImgLen = float(abs(col - left))
testImgLen = float(abs(col - right))
alpha = srcImgLen / (srcImgLen + testImgLen)
res[row, col] = np.clip(img1[row, col] * (1 - alpha) + warpImg[row, col] * alpha, 0, 255)
warpImg[0:img1.shape[0], 0:img1.shape[1]] = res
final = time.time()
img3 = cv.cvtColor(direct, cv.COLOR_BGR2RGB)
plt.imshow(img3, ), plt.show()
img4 = cv.cvtColor(warpImg, cv.COLOR_BGR2RGB)
plt.imshow(img4, ), plt.show()
print("simple stitch cost %f" % (simple - start_time))
print("\n total cost %f" % (final - start_time))
# cv.imwrite("simpletons.png", direct)
# cv.imwrite("bestowal.png", warpImg)
cv.imshow("pictures", img4)
cv.waitKey()
cv.destroyAllWindows()
else:
print("not enough matches!")
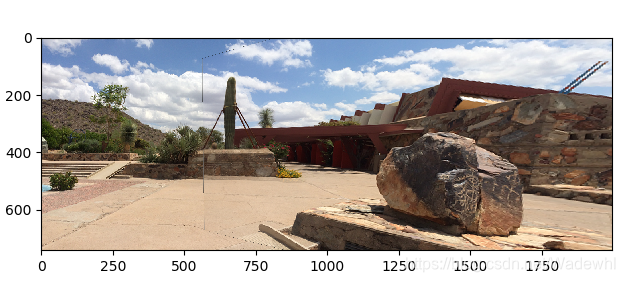
效果:














 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









