






大家好,经过几个月的忙碌,终于可以静下心来写博文了。首先,谢谢CSDN平台和广大粉丝的关注,这是我创作的原动力,在这3、4个月内,我虽然没写博文,但是每天增长的粉丝数却并不比之前少,甚至很多。不管我的博文水平怎么样,但是能得到粉丝的肯定,我很开心!虽然这段时间我并没有发帖,但是CSDN APP我每天都会看,这已经是我的日常节奏,在这里我学到了很多,也得到了很多,所以我也想为粉丝和平台付出点什么来回报,因此,我今天抽出点时间,和大家说说上次我写的Python图像拼接算法的后续改进问题。
原文地址如下:
关于Python图像拼接鬼影、重影的自动去除方法的尝试和总结(其中有SIFT\SURF\ORB多种拼接方法、计算图像的能量显著点、邻域点方法、自动根据能量图动态规则拼接线、Alpha通道拉普拉斯融合)![]() https://blog.csdn.net/donglxd/article/details/140064802 还有我更早的开源程序链接在这里:
https://blog.csdn.net/donglxd/article/details/140064802 还有我更早的开源程序链接在这里:
关于Python全景图像拼接的探索和实践(其中包括对Opencv Stitcher类、PhotoShop MergeImage插件、PTGui Pro12全景图拼合软件的一些横向比较和探究)![]() https://blog.csdn.net/donglxd/article/details/137228325 今天主要讨论的就是自动去鬼影算法的完善和改进,首先和大家道歉,上一篇拼接图像文章已经过去了4个月,而我一直没有发新的文章,其实我也没闲着,一有空我就会完善上次的算法,本来9月底已经基本调试完成,但是有粉丝提出了些新的问题,就是我的算法只能左右寻找拼接线,而对于上下拼接时,鲁棒性不好;还有就是之前算法中的全局色彩平衡问题;算法运行时间过长等等的问题。而这两个月,我就一直在解决这些问题,并取得了些进展,才敢发出来给大家看。可能我的算法并不是最优的,但是也尽了最大的努力,更新这些算法,虽然有GPT的帮助,但是添加代码后产生的大量Bug,却需要耐心得一一解决,说到GPT粉丝们可能不屑一顾,觉得我在偷懒,其实我也只是先构想出很多可能解决问题的思路给GPT,让它帮我验证下算法,这样可以加快开发速度,这估计也是将来程序员常用的编程方法,没什么丢人的,它只是工具,就像以前刚刚出现Office时,Excel公式代替了人工的每次手动计算,但公式也是需要人的智慧才能编写出来的,GPT并不能帮你思考,只能代替你打字写代码,解决语法问题,实际解决问题的方法,还是需要你告诉它才行,而你的思考就是未来需要做的。
https://blog.csdn.net/donglxd/article/details/137228325 今天主要讨论的就是自动去鬼影算法的完善和改进,首先和大家道歉,上一篇拼接图像文章已经过去了4个月,而我一直没有发新的文章,其实我也没闲着,一有空我就会完善上次的算法,本来9月底已经基本调试完成,但是有粉丝提出了些新的问题,就是我的算法只能左右寻找拼接线,而对于上下拼接时,鲁棒性不好;还有就是之前算法中的全局色彩平衡问题;算法运行时间过长等等的问题。而这两个月,我就一直在解决这些问题,并取得了些进展,才敢发出来给大家看。可能我的算法并不是最优的,但是也尽了最大的努力,更新这些算法,虽然有GPT的帮助,但是添加代码后产生的大量Bug,却需要耐心得一一解决,说到GPT粉丝们可能不屑一顾,觉得我在偷懒,其实我也只是先构想出很多可能解决问题的思路给GPT,让它帮我验证下算法,这样可以加快开发速度,这估计也是将来程序员常用的编程方法,没什么丢人的,它只是工具,就像以前刚刚出现Office时,Excel公式代替了人工的每次手动计算,但公式也是需要人的智慧才能编写出来的,GPT并不能帮你思考,只能代替你打字写代码,解决语法问题,实际解决问题的方法,还是需要你告诉它才行,而你的思考就是未来需要做的。
废话不多说,来聊聊我优化的算法吧!首先,说说色彩平衡的问题,如下图所示:
可以看到上图中的拼接图有色彩差异时的拼接效果, 左图是未使用色彩平衡时的效果,右图则已使用,可以看到虽然右图还是有一点拼接痕迹在,但是比起左图要好很多了,要知道左图用了同样的算法,只是没有做色彩平衡。关于色彩平衡的问题,在上一篇文章的时候就有提及,这也是我之前留的一个坑,今天也算基本填上了。关于具体的实现算法,其实也很简单,我是参照了一篇长春理工大学的学生论文(https://ccsenet.org/journal/index.php/mas/article/view/51636),大体的算法,就是使用拼接算法找到的特征点,读取原图的对应两组特征点,把一一对应的特征点的HSV三通道的相减,这样就得到了3个通道的特征点的差值数组,然后把3个数组计算出均值,最后通过python的向量计算,把原始值加上3个通道的均值(其中需要做判断,相加后的值是否小于0或大于255则使用原来的值),最后就得到了如上图的对应于参照图的修正图。当然了,我并没有完全抄论文的思路,因为我发现论文中只是简单的把左图(不是上面的图,而是输入拼接的左右图)作为参照图,去修改右图,这样的结果就是如果左图比右图亮,那么修正后偏暗的右图会导致发灰的问题存在,如下的论文中的图片:


而我改进后的算法,就是先通过一个函数判断左右两图HSV三通道均值的加权差异(记住是加权差异,是有一定比例的混合3个通道的均值) 的大小,来计算出那张图视觉上更暗,把这张图作为参照图,来修改较亮的图,当然了,我只是阐述了理论,实际的代码编写可能是不一样的逻辑,因为我们实际看到图片的明暗效果和计算出的HSV的均值并不一定一样,我们还是需要根据实际情况编写代码,至于原因,大家去实践下我上面的算法就知道了。注意色彩平衡请用在色彩差异较大的两张图片拼接时,如果两张图曝光没有什么差异请不要使用色彩平衡,不然效果反而更差。
说完色彩平衡的问题,我来说说拼接线算法的改进,首先我应粉丝的要求,增加了上下方向的拼接线寻找的代码,当然考虑到代码的复用问题,我添加一个direction参数到函数中,使用"v"(上下拼接方向)或"h"来赋值这个参数(注意v和h都是小写的),后来我为了适配各种情况的图片,陆陆续续添加了5、6个参数,所以我又给这个direction参数增加了一个"auto"值来切换成自动判断模式,这样就不用每次添加手动参数,来判断到底是上下拼接,还是左右拼接。至于拼接线算法的逻辑,我也做了更新,使用了numpy中的roll来历遍每一行相对列的左、中、右三个方向的能量图最小值,这样就不用重复的历遍每一列的值,使算法复杂度从O(N²)变成了O(N) ,因为使用了numpy的数组向量计算,让即使是现在的python版本,也比之前的速度快的多,也就是一眨眼就计算完成了。
接下来,我们聊聊重叠部分计算的问题,为什么说这个那?因为重叠部分的计算牵涉到能量图的计算,而能量图又影响到拼接线的计算,环环相扣,所以是重中之重,在之前9月份的版本中(就是我之前想发博文的时候,后来因为粉丝提出的要求延后到现在),重叠部分的计算还是使用了原来的找内接矩形的思路,这步我想了多种方法来实现。大家可能觉得找不规则多边形的内接矩形应该是寻常的方法,很容易解决,但是我实践下来,除了暴力历遍算法(历遍不规则多边形上的任意两点围成的内接矩形面积并判断是否完整的在多边形内部的算法),并没有很好的方法解决这个问题,我之前使用的就是历遍所有可能的方法,如果重叠区域较小,速度还行,但是代码编写好后,都到了测试阶段了发现有一个案例计算速度奇慢无比,一调试发现竟然要历遍100w个内接矩形面积的可能性,这就太慢了。所以我只能推倒重来,为了寻找这个最佳内接矩形的算法,我甚至看了全世界累计阅读量第二多的欧几里得的《几何原本》,请不要说我做广告,我也得不到任何好处,纯粹是一个过来人的建议——这本书值得研究几何算法的同学一看,顺便说一句,不知道看哪个版本的,建议看原版或者张卜天的现代译版,反正我看的是张作者的中文版。当然了,你如果要在这本书里找我这个内接矩形的解决方法,我的答案是没有,问了下GPT,意思是这个问题是现代几何的问题,可能欧式几何并没有讨论最优化的方法。既然没有现成的答案,只能在现有的基础上优化算法,所以我想出了下面的方法,如图所示: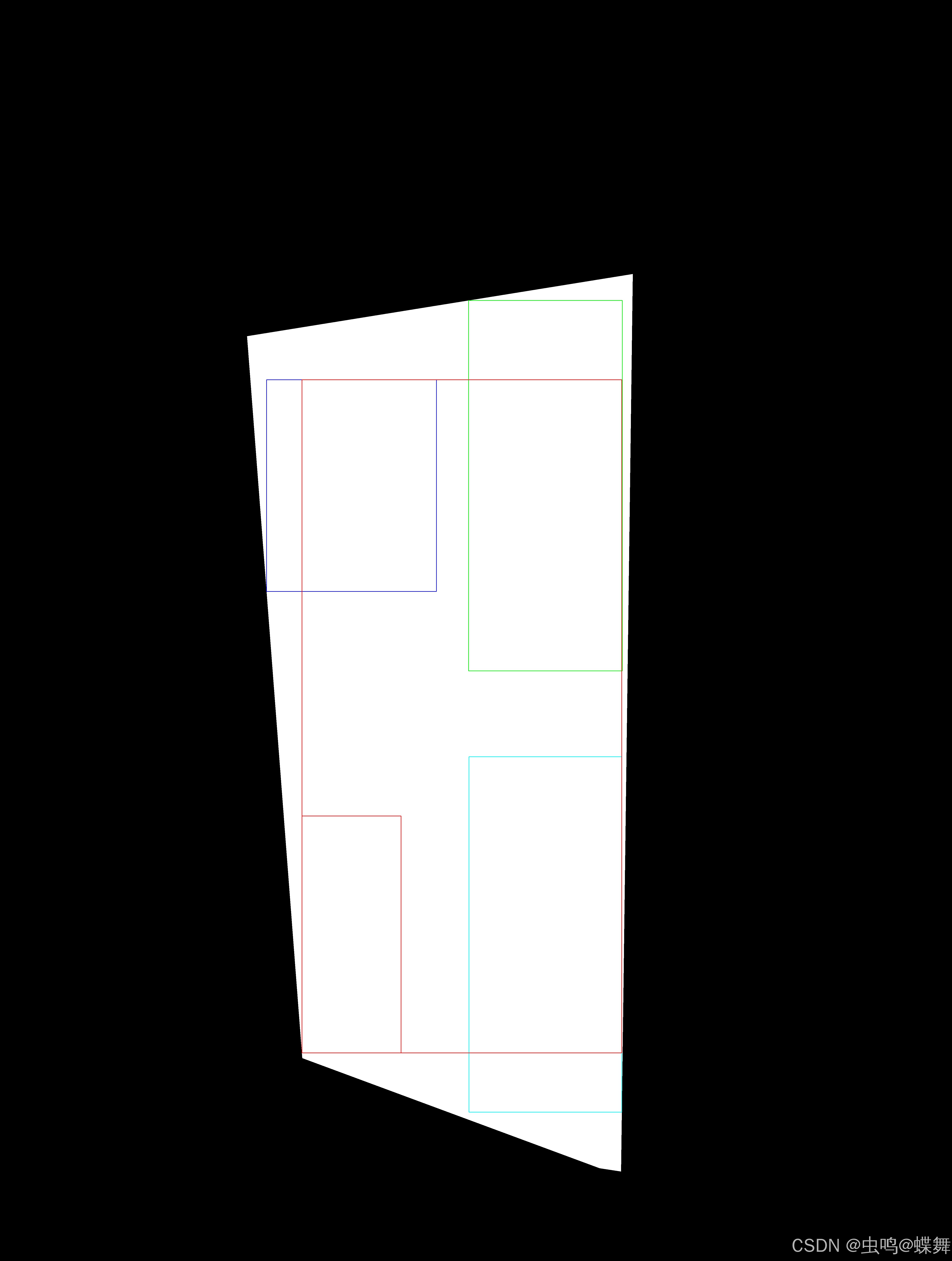
你可能咋一看并看不懂,但是细心的同学会发现,我把解不规则多边形的内接矩形,分解成4个方向上的小矩形(这样只要使用二分法不停的尝试调整小矩形的长和宽,然后判断每个方向上的小矩形是否超出白色边界),最后通过简单的判断4个小矩形的上下左右边界就能得出一个合理的内接矩形即可,但是大家也看到了,这个内接矩形,比起历遍算法得出的最优矩形,并不是最佳的,所以这条路就走不通了(即使得出了内接矩形,但是对于图中的白色重叠部分,我们也会发现,生成的内接矩形能量图总要缺少的部分,这导致了拼接处的图片的缺失,所以我不得不放弃这种想法,另辟蹊径),对于怎么解决,我也尝试了很多方法,最后发现两种方法可以比较好的解决。其中的一种简单方法如下:把白色的重叠区域反相颜色处理,即黑色的外围变成白色,相当于扣出了重叠区域,同时使用opencv的通用函数boundingRect计算出多边形的外接矩形减小原图面积,然后和上面得出的反相区域重叠(这样做是为了加快能量图、邻域点、拼接线的计算速度,因为与原图比计算量减少了),这样就得出如下图所示的效果:
可以看到在这张图中,白色部分就是反相的结果,而黑色部分就是重叠区域,为什么要这么做那?看下面的能量图就能理解了,如图: 上图就是使用了反相方法的能量图,里面还有根据能量图找到的拼接线,反相区域的白色可以限制拼接线的通过,这样拼接线就不会沿着反相的区域通过(本来的这个区域是黑色能量最小,拼接线最喜欢走的就是能量小的区域) 。在发现这个算法后,我发现虽然这个算法对于大多数左右拼接都能有比较好的结果,但是对于上下拼接或者多张图片连续拼接的边缘部分并不是很好,给你们看看对比图:
上图就是使用了反相方法的能量图,里面还有根据能量图找到的拼接线,反相区域的白色可以限制拼接线的通过,这样拼接线就不会沿着反相的区域通过(本来的这个区域是黑色能量最小,拼接线最喜欢走的就是能量小的区域) 。在发现这个算法后,我发现虽然这个算法对于大多数左右拼接都能有比较好的结果,但是对于上下拼接或者多张图片连续拼接的边缘部分并不是很好,给你们看看对比图:
我把反相的方法命名为mode2,新发现的方法命名为mode1(此方法作为推荐方法),在我的代码中使用如下代码调用:
find_overlap_mode = 1 # 1为mode1,2为mode2至于mode1的新方法,我是通过mode2改进而来,具体是我把mode2的方法,拆分成了上下拼接和左右拼接两种情况来处理,如图所示:
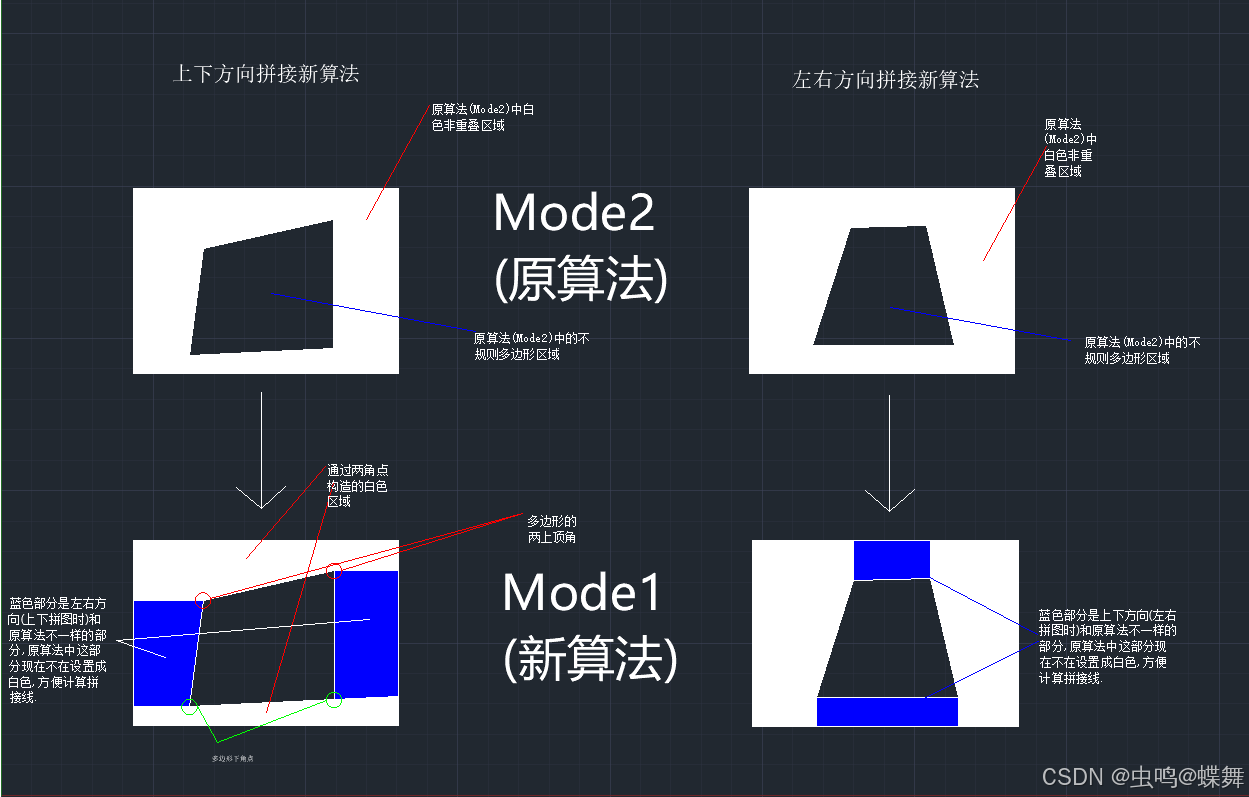
可以看到如上图,上面的两个图形是上下方向和左右方向拼接时的案例,使用的是mode2的全反相方法,而下面两个图形则是新的mode1的方法,其中白色区域是需要标记出来的部分,比如上下方向拼接时,就是中间黑色重叠部分的四个角点分别向左右两边直线延伸到图片边缘,和图片的4个边缘角点围成,上下两个白色区域,而标注的蓝色部分则在mode1算法中不标记白色,还是为黑色;同样的的原理,右下角的图片中,标注了左右拼接的mode1具体算法,左右两块白色部分,即是标注区域,上下的蓝色部分不标注。至于为什么要这么编写的原理,其实就是和拼接的方向的限制问题,上下拼接时,拼接线是横向(从左到右或从右到左)寻找的,我们需要限制好上下部分的界限,这样蓝色的左右部分(也就是拼接图片左右的边缘部分,也就是蓝色部分,得到了很好的计算);同理,左右拼接时,拼接线是纵向(从上到下或从下到上)寻找的我们限制左右方向的界限,如此一来,拼接边缘的问题就解决了。当然了,这个mode1算法还是有点小bug,比如下面的情况:

如上图所示,重叠区域的不规则多边形,上部有3个顶点,但是mode1实际计算时,只算了顶部的2个顶点,导致左上方缺失了一块,其实这个mode1的算法还可以改进下角点判断就完美了,但是因为这个项目实在托的太久了,既然mode2能解决这个问题,我就暂时弄了两种模式可选,之后如有可能再改进。
至于大家搞不清到底使用mode1还是mode2,建议大家先尝试mode1,不行再mode2,还有我经过大量测试发现,多张图拼接时,尽量采用mode1更好。
上面我说了几个大改进的地方,还有一些小优化,比如因为粉丝提出要拼合超过8K的原图时,会内存不足的情况,我把拉普拉斯融合这里做了分块处理,减小内存占用,而之前这个分块只有手动设置功能,现在我为了大家调用方便,添加了自动设置分块大小,如下语句设置:
block_count = 0 # 拉普拉斯融合时的分块数,当等于0时,自动计算分块数,通常不用手动设置,如内存占用过大,可以加大这个值而这个分块也会带来副作用,那就是经典的时间换空间问题,换句话说,分块越多运行时间越长,如果你内存够多,可以把block_count = 1,这样就只有一个分块了 。
至于拉普拉斯融合的另一个改进,就是我添加了拉普拉斯中的掩膜层渐变过渡,如下图所示:

渐变的宽度通过如下参数调用:
max_dist = 100 # 掩膜渐变区域宽度这个变量在2K小图拼合时,设置20-50;4k图设置50-90;8k图设置100-250即可。
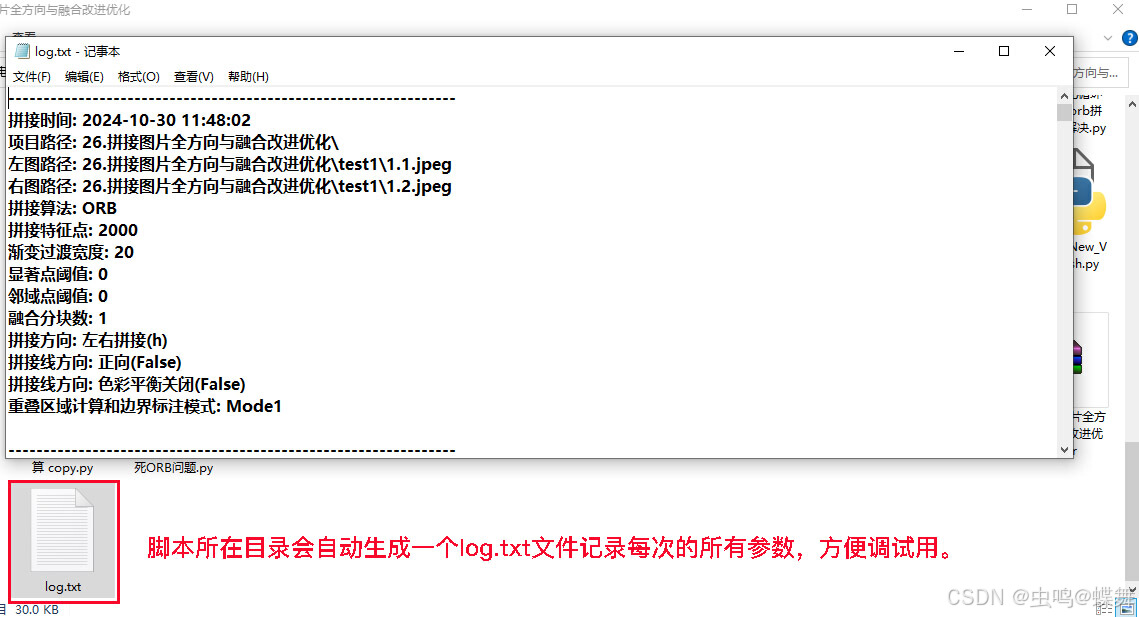
一个完善的程序都需要日志,所以我在python版本上添加了日志功能,在脚本所在目录的log.txt文件中可以查看所有过往的拼接参数记录,方便大家调试用。如下图所示
说了这么多python版本的,我想接下来谈谈c++版本的。
本人之前没有怎么好好学过c++,为什么有编写c++版本的念头,也是有一个粉丝之前提出的,后来静下来思考后,觉得这么复杂的算法,只用python编写效率实在不高,所以就有了编写c++的想法。你们会下载到的c++版本,也是我编写的第二个大版本,之前9月底,我就尝试编写了一个可用的版本,但是因为python版本又增加了上面说的这么多功能,所以我花了一个多星期,又把c++的版本也升级了下,当然了本人的c++还是初学者水平,而且想早点发博客给粉丝们一个交代,所以c++的版本没怎么优化,特别是8K原图拼合时,拉普拉斯耗时比较长,这个还有待之后优化,至于最近我也想休息下了,编写拼合代码花了我太多的业余时间了,导致我几个月没有更新博客,是该研究点新东西了,这个拼接算法到底还是小众算法。
说到c++编译opencv代码,我就不得不提一下,现在微软推出的一个小工具,它可以让c++安装编译opencv库方便到像pip一样,它就是vcpkg,至于它的安装方法也很简单,完全是c++开发人员的神器。如下是安装教程:
先去github的vcpkg主页(https://github.com/microsoft/vcpkg):
然后下载最新版本的Source code(zip),这里给大家一个最新版链接方便下载(https://github.com/microsoft/vcpkg/archive/refs/tags/2024.10.21.zip)
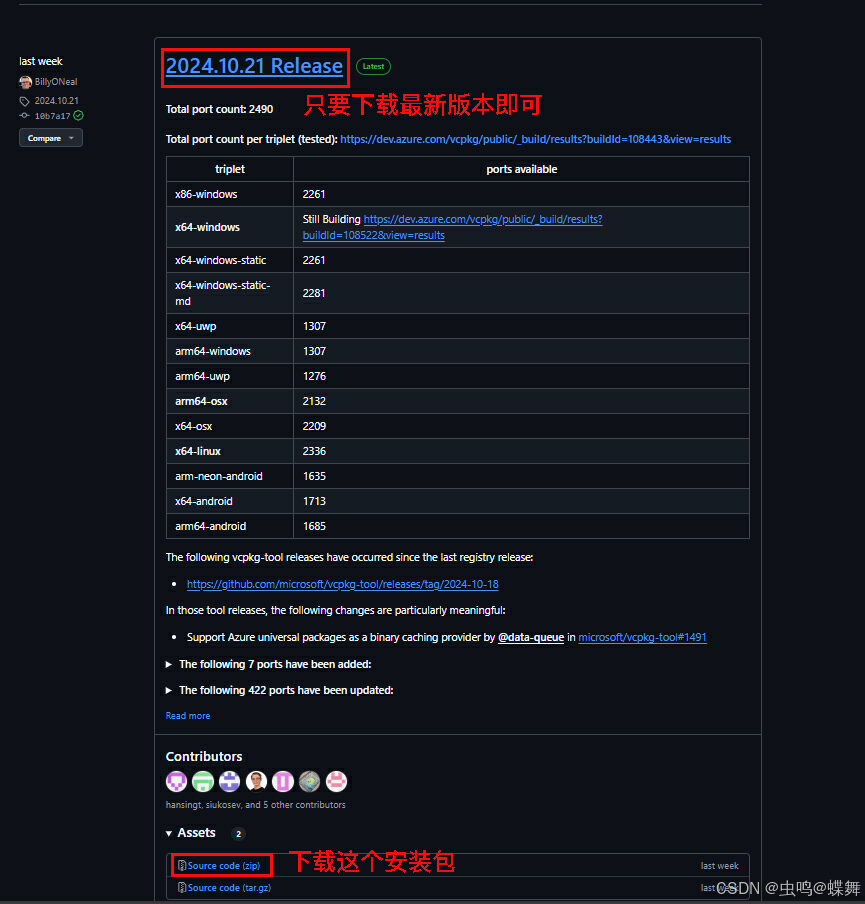
下载后解压,可以把文件夹重命名成你喜欢的名称,并放入你需要的路径目录里(如果你不想之后编译失败,建议你使用全英文路径和文件夹名称),为了调用方便,可以把文件夹添加到系统环境变量里,如下: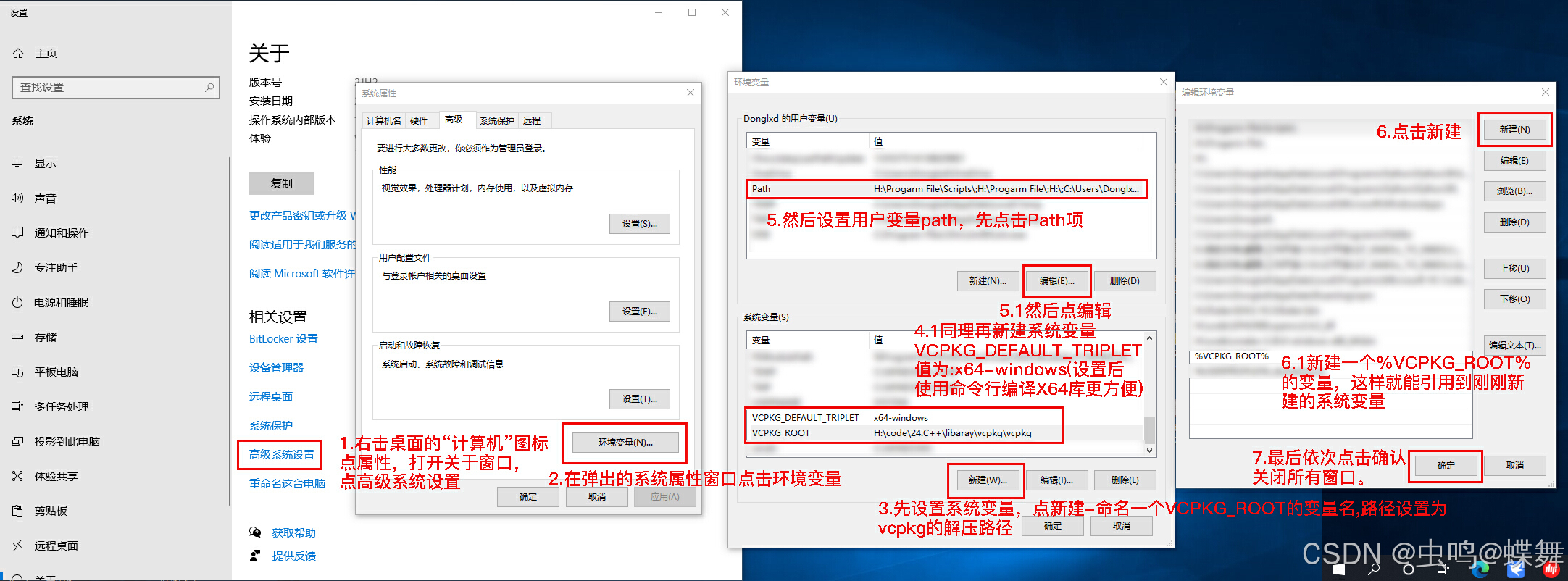
如果你上面的环境变量添加成功后,只要打开cmd命令提示符,运行如下代码即可安装vcpkg:
bootstrap-vcpkg.bat如果你不想添加环境变量,也可以打开刚刚解压的文件夹,双击bootstrap-vcpkg.bat这个文件执行安装,如果运行成功,文件夹中会多出一个文件(vcpkg.exe) ,这个文件就是执行vcpkg的主程序。
接着,重点来了,你如果需要使用vcpkg像pip一样安装编译库,一定要安装Microsoft Visual Studio,我安装的是最新的2022版本(项目也是建立在2022版本上的),我10年前的老电脑除了启动有点慢,并没有什么问题。下载时,你可以选择专业版,网上随便找一个key填入,就能用,安装过程很简单,我就不写教程了,不会的同学请搜索下教程。有人会问,vs2022太大了,只安装c++编译器都要10G空间,想用mingw_x64的g++编译器,那么作为过来人,我可以明确的告诉你,有些包可以用g++编译器编译,有些不行,比如opencv是不行的(因为vcpkg下载的源码有些是vs版的,所以只能用vs编译),我说的前提是你使用vcpkg,如果你有能力自己搞定cmake文件,那么使用g++也没问题。对于初学者,建议使用vcpkg更简单。
安装vs2022后,我们还需要安装下一下英文的语言包,如下:
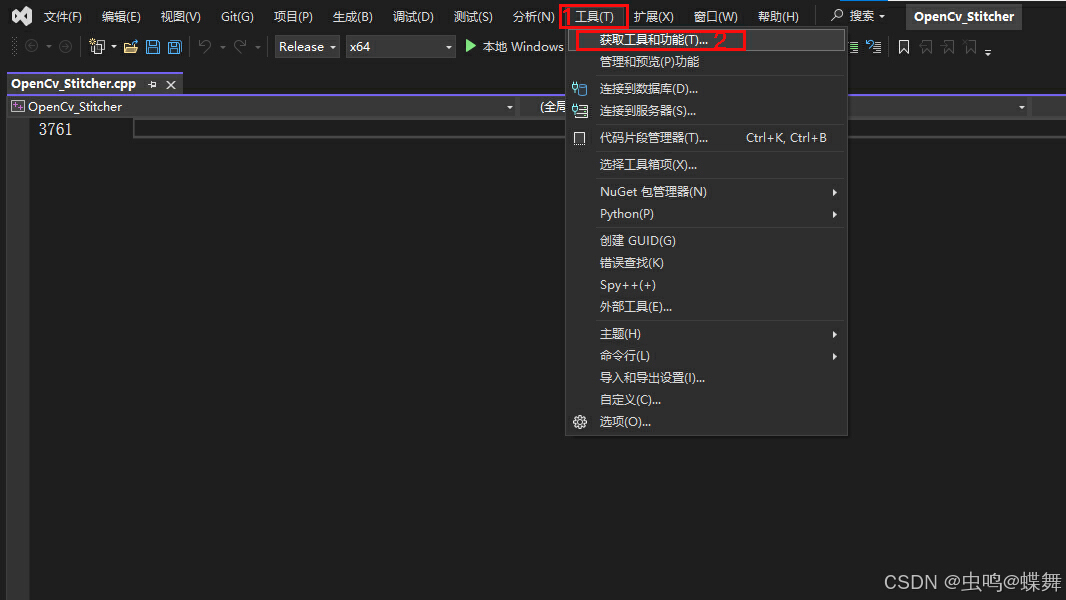
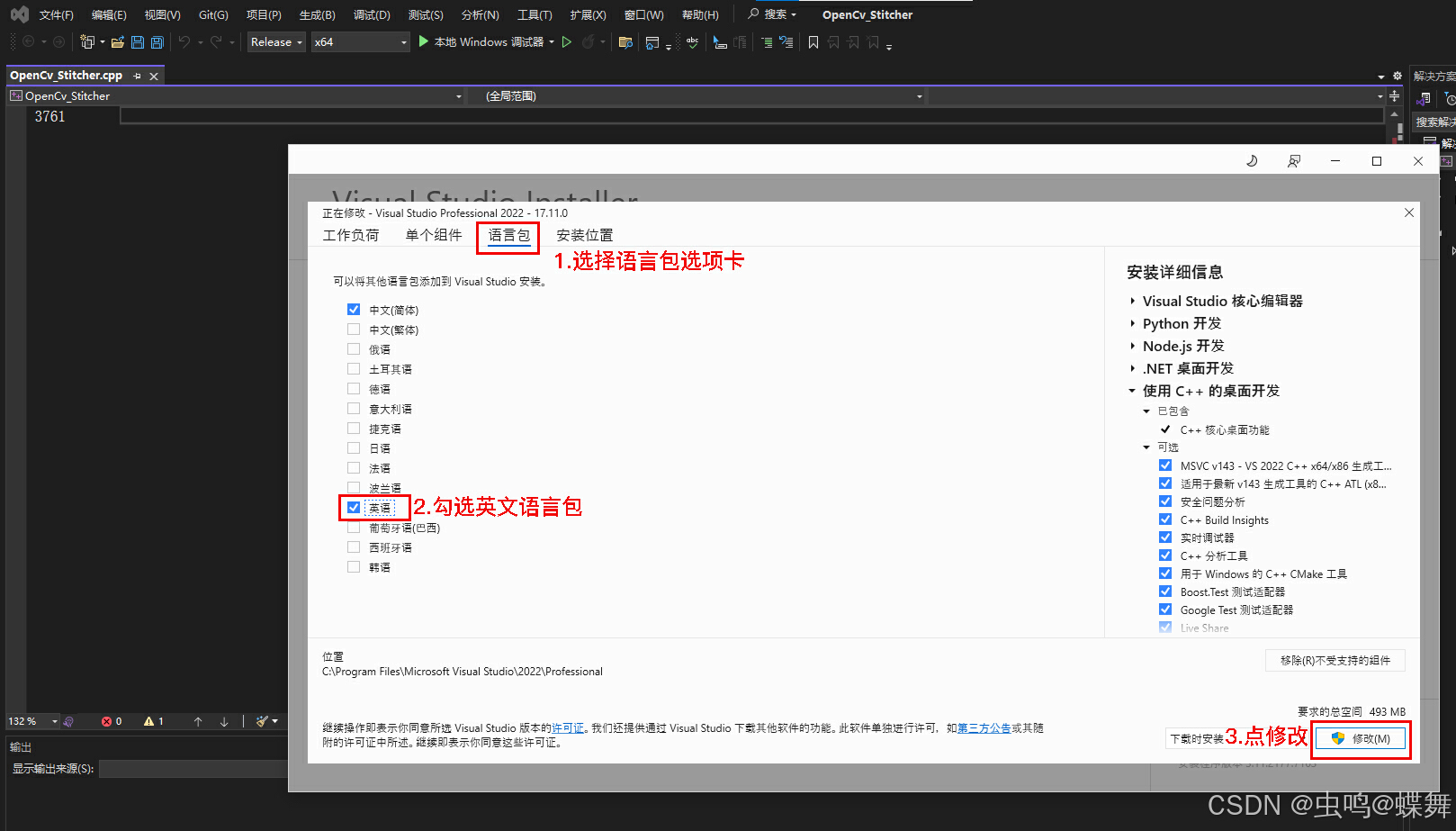
这些步骤做完后,把vspkg编译的库和vs2022关联下即可,使用如下cmd命令(此步骤,相当于自动把头文件和库文件都自动添加到vs的项目中去,只需执行一次即可。)
vcpkg integrate install这样就基本完成了vcpkg的安装。
至于使用vcpkg安装库时,使用如下命令:
这里特别注意一点:使用vcpkg需要使用代理网络(需要代理才能下载各种github等网站的源码包),切记!切记!切记!
vcpkg install opencv #opencv是安装库的名称,可以替换成你需要的库名因为我们现在基本都是x64的window,所以我们之前在环境变量设置了默认的系统版本为x64,你也可以手动命令定义如下:
vcpkg install opencv:x64-windows # 编译X64版本
vcpkg install opencv:x86-windows # 编译X86版本
如上只要在库名后加上":x64-windows"或":x86-windows"即可,注意不要漏了半角的冒号。
最后我们只要在c++的项目文件中,直接引用头文件就行。
#include <opencv2/opencv.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/features2d.hpp>
#include <opencv2/stitching.hpp>介绍完vcpkg,接下来说说python转c++的技巧,c++相比python最大的不同,就是变量的强类型申明,python一句很简单的赋值语句,到了c++这里就都要写清楚,这在函数的定义时,也是一样的,函数的返回值和参数都需要强申明,关于这个问题,我的建议是不要全靠AI转换,还是要去学习下c++的语法,推荐的入门视频教程是,尚硅谷的清华武神c++零基础编程教程,一共105集,个人感觉讲的通俗易懂,是比较好的入门视频,大家可以找来观看,如找不到,也可以联系我,我会把视频文件打包免费发给你,当然了希望大家注意版权问题,自己学习下就好,不要外传。
在你学完基础的c++语法之后,我们回过来看c++代码就不是很难了,可能有些具体算法转换我们还不行,但是我们有AI,然后把一个个python函数转换成c++的版本,期间注意c++的变量定义不要搞错了,比如python很简单的一个函数返回两个mat类型的图像数组
# python例子
def color_balance_with_brightness_check(self, img1, img2, src_pts, dst_pts, project_path, debug):
# 这只是一个例子,中间很有很多代码
return img1, img2 # 有两个mat返回值,在python中是numpy数组(numpy.ndarray)而转换成下面的c++版本中需要定义成pair<Mat, Mat>,pair这个命令就是把两个Mat类型整合成一个数组返回,而参数中的const是防止函数修改原始的img1、img2等值,如果不加上const,就是可以修改,Mat&后面的&符号表示img1的一个引用,你可以想象成一个img1文件的桌面快捷方式,修改Mat& img1就是修改img1的内容,至于后面的vector<>可以理解成c++的数组向量,vector<Point2f>& src_pts相当于是一个对src_pts数组(Point2f类型)的直接引用,这些知识我现在直接和你说,可能你不是很明白,但是你看了上面说的视频后,会觉得很简单,如果一遍看不懂,那就多看两遍,有时学会一种语言,另一种就会触类旁通的
pair<Mat, Mat> color_balance_with_brightness_check(const Mat& img1, const Mat& img2,
const vector<Point2f>& src_pts, const vector<Point2f>& dst_pts,
const string& project_path) {
return make_pair(img1, img2);# 使用make_pair创建一个pair数组返回值,包含img2和img2两个mat类型的数组
}现在的c++也进化过3个大版本了,不是以前复杂繁琐的c++了,我使用了c++ 17版本,其中就有返回值的auto功能如下:
auto result = detector.process(project_path, mask_rect, code_Vision, debug, st, et);上面的返回值result其实是一个多变量数组,但是使用现在的c++ 17就能直接使用auto赋值,而不用拆分定义变量类型。
搞懂了上面的这些变量、函数定义后,转换c++就变成了一个时间过程,因为现在AI转c++的能力太强了,基本的算法都能帮你搞定,当然了优化上还是需要你自己的努力,这是现在AI所做不到的东西,AI只能听从你的指令来优化,或者给你优化建议,你如果像让它想出不存在的算法,那有点强AI所难了。
说了这么多转换的问题,现在来说说我的代码的使用教程:
Python版本的使用说明:
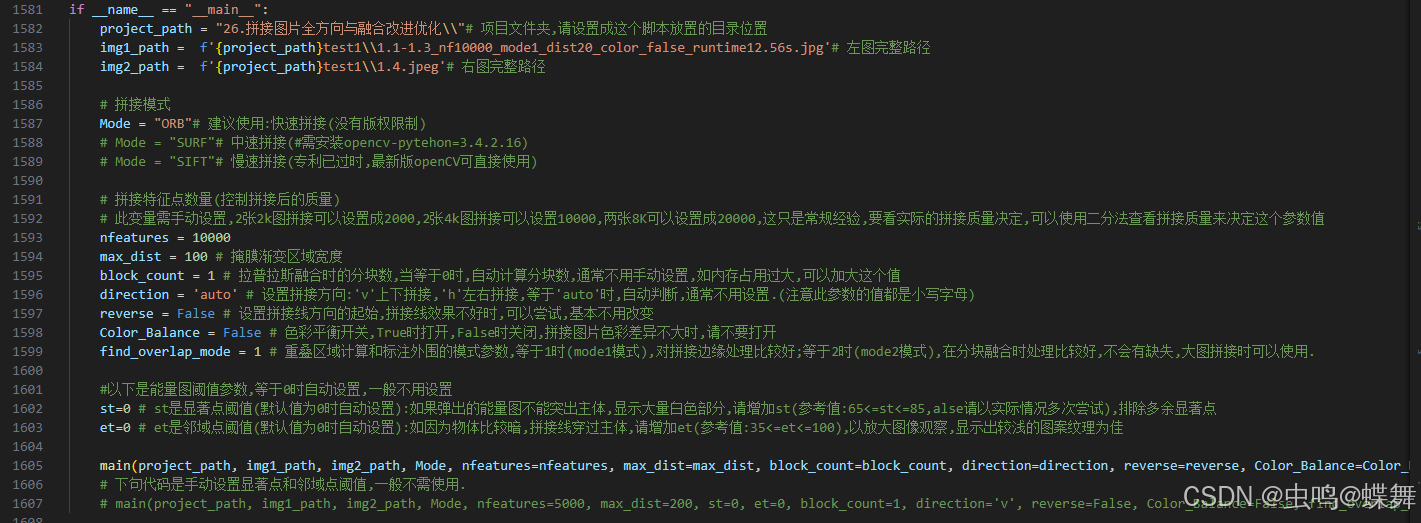
上面是python版本的调用参数部分(在脚本的最后部分),所有使用的参数都在此修改,因为python之前就弄了,所以代码和注释都写的比较好,主要的函数和过程都有相应的注释,如果认真看过我之前的文章和这篇文章,应该使用起来不难,我还是简单介绍一下吧!
首先 project_path就是脚本存放的位置或测试图片的主目录,因为之后project_path要和img1_path和img2_path拼接起来组成拼接源图像,所以请注意拼接目录的设置
之后的Mode是拼接模式的选择有ORB和SIFT,我只测试的是ORB,当然ORB、SIFT、SURF的拼接部分代码我都写了,提到ORB,我就要说说这个拼接算法的优缺点,首先就是运行速度快,比SIFT快的多,但是对于某些情况质量并不是很高,所以就要谈到下面的nfeatures这个参数,这个参数可以控制三种拼接算法的特征点的多少,设定的值需要根据实际的图片大小和图片的匹配度调整,对于两张Iphone11拍摄的2K图拼接,基本使用2000-5000即可,对于两张4K左右的图片拼接基本在5000-10000,对于8K大图拼接则可以稳定使用20000-25000,这也是我测试下来的经验,具体调多少要你先设置个值试试看,如果图片割裂或对不齐、缺失很多时,大概率是这个nfeatures参数没设定好(如果你对调参不了解,或调不好,可以来问我,方便的话把图片发给我,让我来帮你测试看看),具体的参数设置经验,你们可以参考我之后上传的测试图文件夹中"拼接中间图"里面有我对每张拼接图过程的输出图片,它们的名称就是具体的参数值,免费提供给大家参考和查看拼接质量,再来决定是否需要我的代码。

之后的几个变量都有相关的注释,我就不一一介绍了。
C++版本的使用说明:
C++版本的程序的编译路径如下:
5.Opencv_Stitcher_v2_Format\OpenCv_Stitcher\x64\Release主程序是OpenCv_Stitcher.exe,如果直接运行的话,可能会报错,我们可以在Release文件夹的空白处按shift+右击后,选择在此处打开PowerShell窗口,点选如下: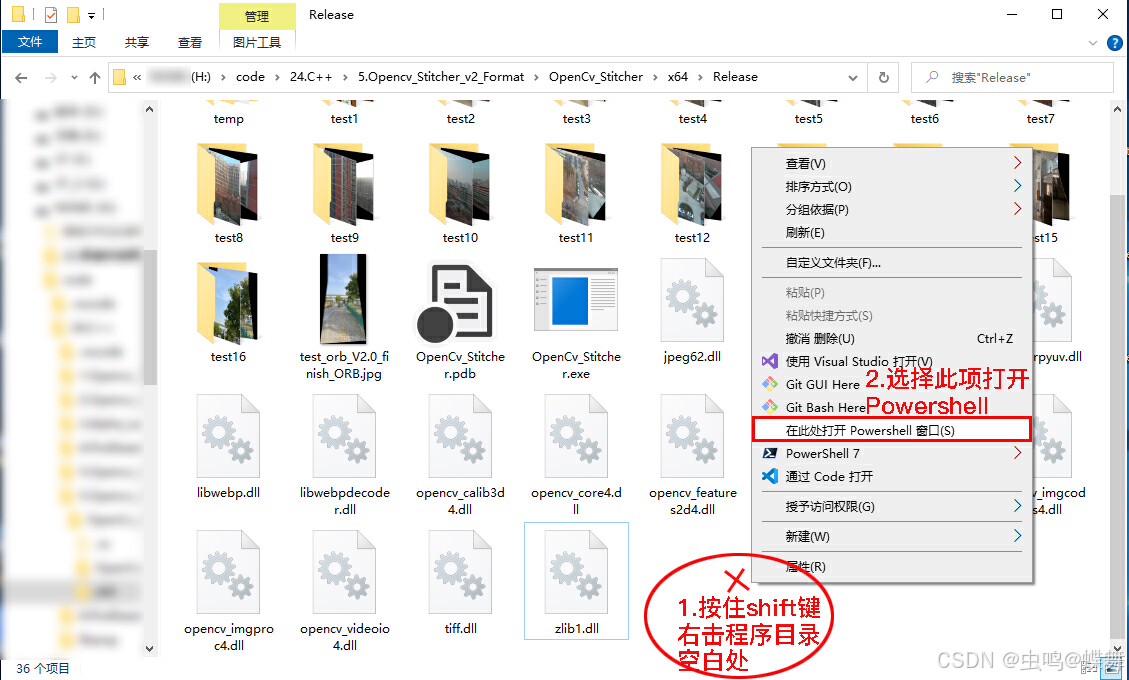
然后把主程序图片如下所示拖到在打开的PowerShell窗口释放,这样就写入了主程序路径:
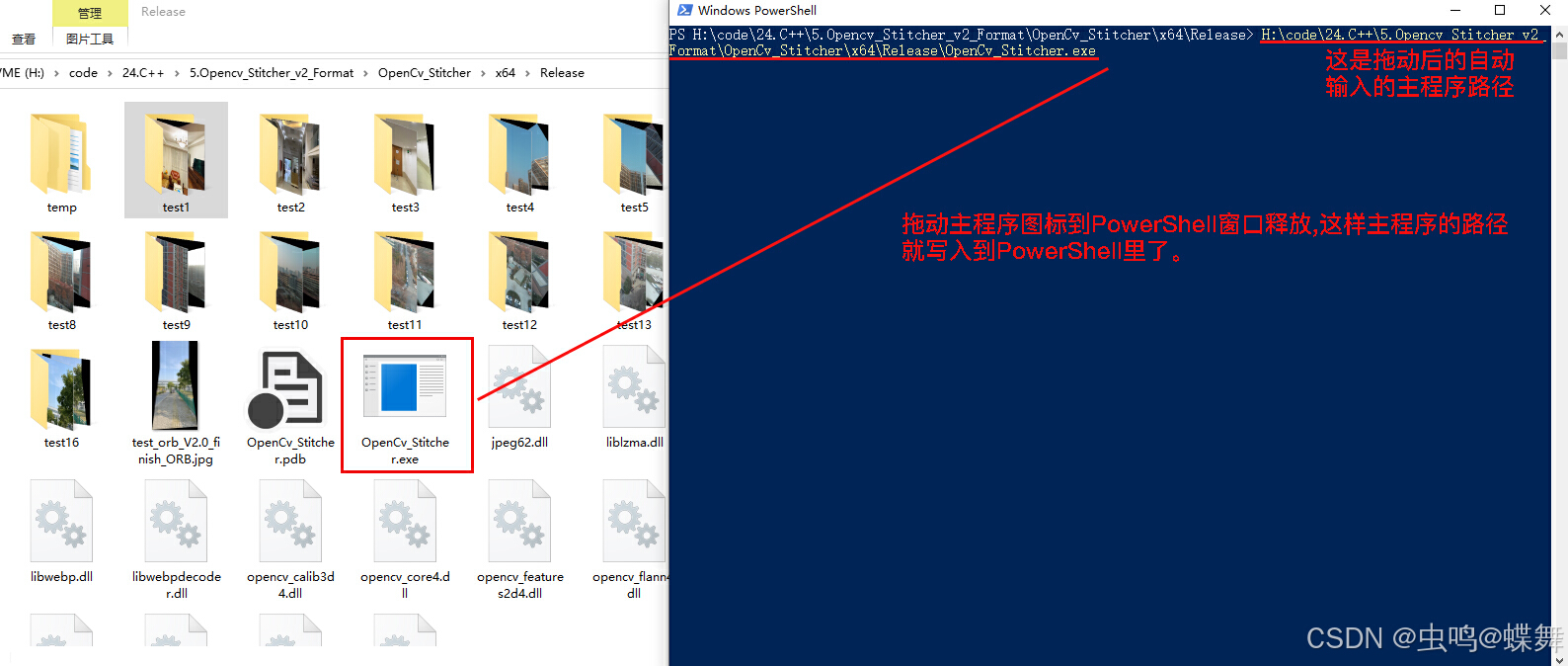
同样的方法写入你需要拼接的两张原图,注意上下和左右的方向,需要依方向顺序拖入释放到PowerShell中,这样就有了两个图片路径,注意所有的路径和参数都需要英文半角空格分开。
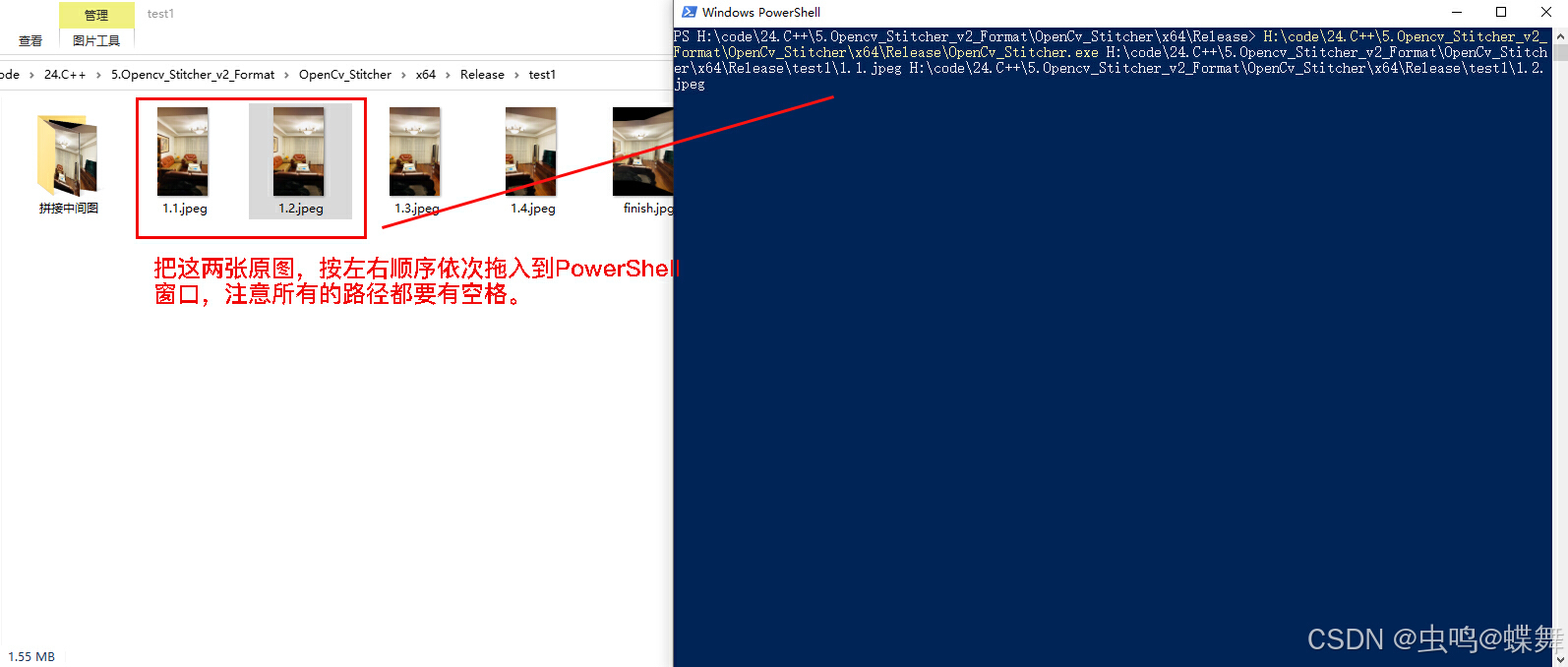 最后输入的是参数,分三种模式:
最后输入的是参数,分三种模式:
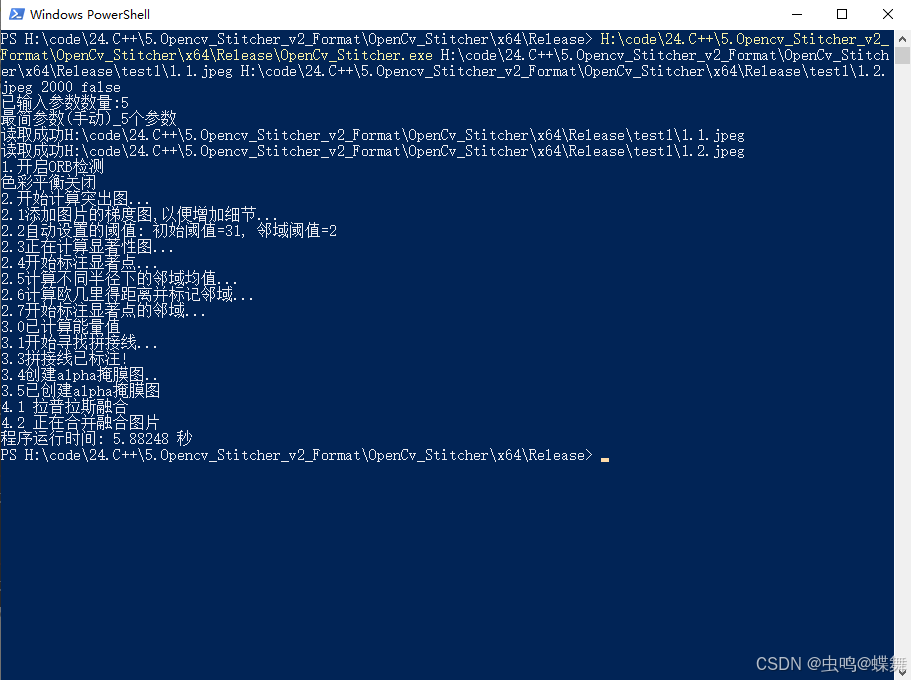
# 第一种(最简参数(手动)_5个参数):
[Project_Path] [img1_path] [img2_path] [nfeatures=0-30000以上] [Color_Balance=true|false]
依次分别是[主程序目录] [原图1路径] [原图2路径] [特征点数量] [色彩平衡]
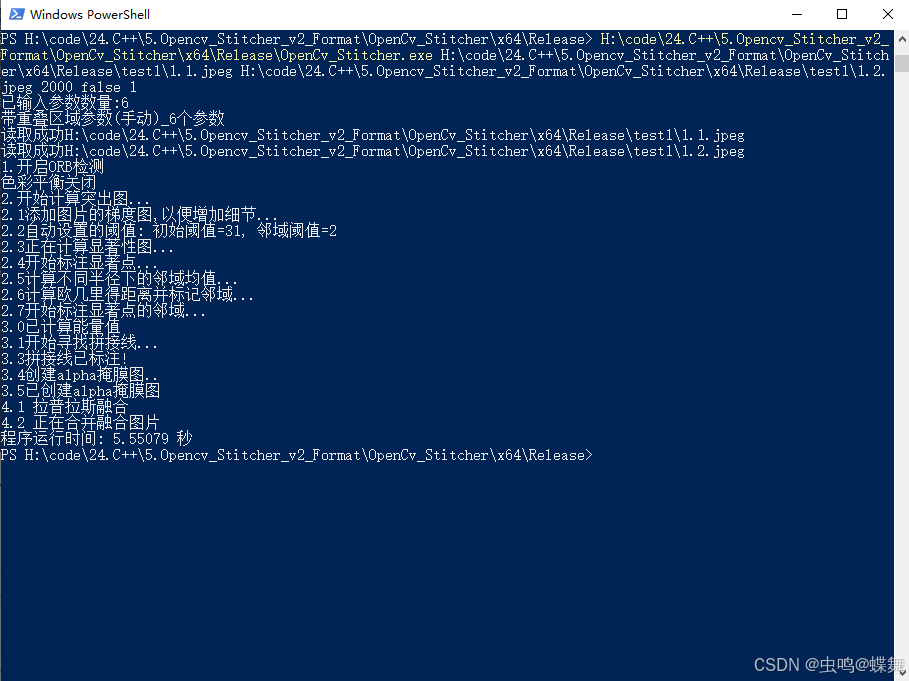
# 第二种(带重叠区域参数(手动)_6个参数):
[Project_Path] [img1_path] [img2_path] [nfeatures=0-30000以上] [Color_Balance=true|false] [find_overlap_mode=1|2]
依次分别是[主程序目录] [原图1路径] [原图2路径] [特征点数量] [色彩平衡] [重叠区域模式]
# 第三种(全参数模式):
[Project_Path] [img1_path] [img2_path] [Mode="ORB"|"SIFT"|"SURF"] [nfeatures=0-30000以上] [max_dist=0-250] [block_count=0(auto模式)-N] [direction="auto"|"h"(左右拼接)|"v"(上下拼接)] [Color_Balance=true|false] [find_overlap_mode=1|2] [reverse=true|false] [debug=true|false] [st=0(auto模式)-N] [et=0(auto模式)-N]
依次分别是[主程序目录] [原图1路径] [原图2路径] [拼接算法] [特征点数量] [渐变过渡宽度] [色彩平衡] [融合分块数量] [拼接方向] [色彩平衡开关] [重叠区域模式] [拼接线方向] [调试信息输出开关] [显著点阈值] [邻域点阈值] 下面的3张图是示范例子:
a. 5个参数的例子
b. 6个参数的例子
c. 全参数的例子: 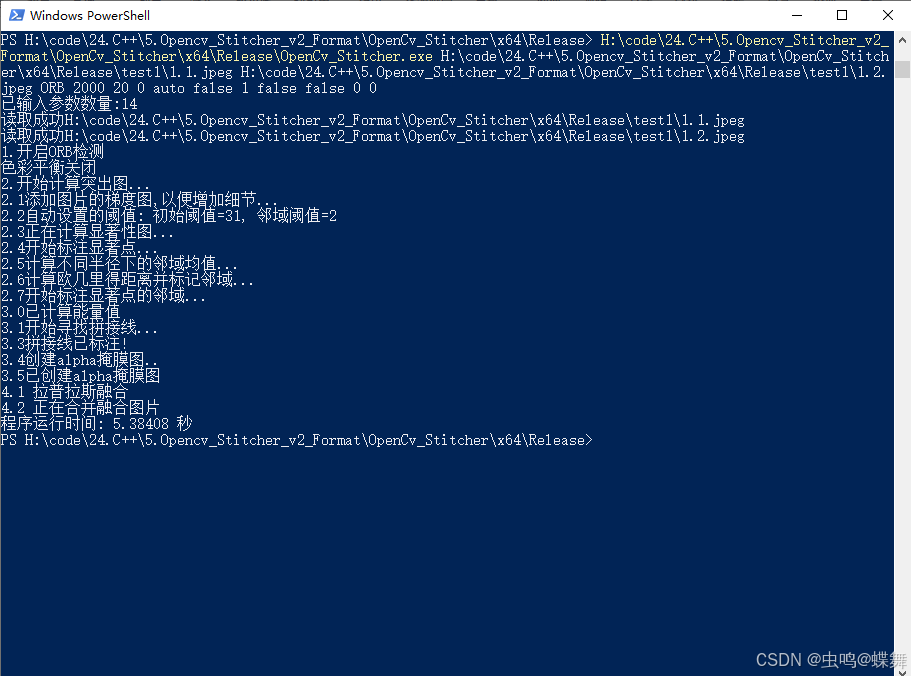
最后说一下我的代码不足之处,其实ORB算法也是很久以前的算法了,之后又涌现出各种拼接算法,而这些算法有APAP、SPHP、超分辨率等等,它们从原来的全局矩阵变换到局部矩阵变换,再到类似图割的把重叠区域分成小块拼接的所谓的超分辨率,拼接算法其实一直在完善,我们现在所常用的SIFT、SURF、ORB都是全局矩阵变换,而这些算法的问题就是导致拼接后的图片拉伸变形,甚至视角太大的话还会拼接失败,比如下面的情况:

可以看到因为两张原图的视角差别过大,就会导致超出全局矩阵变换的情况方法(右边的最边缘到了最左边去了) ,这就是ORB之类算法的弱点,这在APAP、SPHP这样的局部变换算法中得到了改善。我这个人喜欢比较严谨的做事,什么东西不行,我不会说行,去作假,这也是一种个人习惯,我完全可以不提这些bug,欺骗大家去购买下载我的代码,其实这个bug和我的拼接代码关系不大,我的代码是先用ORB拼接后,再去寻找的拼接线,这个bug只是ORB这类算法的弱项,如果要解决只有换APAP、SPHP之类的拼接算法,当然了这些新算法也有其他的问题比如重叠部分的错位,就像我之前文章中提到的,这个拼接问题,到现在都不能100%解决所有的变形、拉伸、鬼影、重影等拼接问题,能解决这些的也只有全景摄像头,但是全景摄像头也有形变的问题,这让我想到了前段时间旅游坐的高铁车厢上的多摄像头全景相机,对于固定的多摄像头全景相机,可能才是这些问题比较好的解决之道。
最后放两张拼接效果图给大家看看吧!
图1,左右4张连续拼接:

图2,上下3张连续拼接: 
最后是所有的资源链接:
Python版代码:
C++版代码:
测试图片集和拼接后的图片集(百度网盘-可免费在线看效果):
Python和C++图像拼接效果图![]() https://pan.baidu.com/s/1Go3akkYLpQTxLiuXVgmxXw?pwd=1234其中每个test文件夹中的finish.jpg都是拼接的最终效果,而"拼接中间图"文件夹中的图片名称和效果,是每个拼图步骤的结果和参数,免费供大家参考。
https://pan.baidu.com/s/1Go3akkYLpQTxLiuXVgmxXw?pwd=1234其中每个test文件夹中的finish.jpg都是拼接的最终效果,而"拼接中间图"文件夹中的图片名称和效果,是每个拼图步骤的结果和参数,免费供大家参考。
最后要说的都说了,有任何问题可以评论区或私信我,看到会回,再次谢谢大家的观看,再见!



















 3094
3094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











