







论文下载地址:https://arxiv.org/pdf/1903.11752.pdf
代码地址:等待开源,开源会第一时间发出来。
论文摘要:
目标检测算法在移动平台仍然是一个挑战。基于CNN的检测算法由于计算量很大很难在移动平台达到实时检测的要求。本论文中作者提出了实时检测的轻量级的two-stage算法。在基础网络部分,作者提出了一个轻量级的基础网络。在检测部分,作者提升了RPN的效率和检测头设计。为了提高网络特征表达能力,作者提出了两个网络结构块 上下文增强模块和空间注意力模块。 最后作者还权衡了输入分辨率,基础网络和检测头部三者对检测准确率的影响。跟踪精度在coco数据集上取得了很好的成绩,并且在ARM上面可以跑到24.1fps。是第一个可以在ARM上面达到实时检测的算法。
引言:
当前基于CNN的目标检测算法可以分为两部分:基础网络部分:用来提取图片的特征。检测部分:用来检测图片中的目标实例。
在基础网络部分,当前主流的检测算法大多使用很深的网络结构和较大的图片输入来达到很高的精度,但是他们的计算量很大。虽然在物体分类领域轻量级网络的出现可以使这些检测算法在GPU上面达到实时检测,但是它们的计算量仍然十分巨大。
在检测部分,目标检测算法主要分为two-stage和one-stage两部分。two-stage通常是由RPN和检测头(检测头主要包括:ROI和RCNN子网组成)组成。RPN先产生大量的ROIs,然后检测头再对ROIs进一步处理。
One-stage算法直接对图片进行预测和分类,计算量要比two-stage算法少很多。但是作者发现一个问题,很多改进的轻量级的one-stage算法在准确率和速度之间很难达到理想的结果。所以作者思考two-stage算法是不是要优于one-stage算法(因为理论上来说one-stage算法要比two-stage算法速度和计算量少,所以很少有改进two-stage目标检测算法)。
作者提出了ThunderNet网络结构。在基础网络部分提出了SNet网络结构。在检测部分,作者进一步压缩了RPN网络和RCNN子网络。为了消除由于小的架构和小特征图造成的退化问题,作者引入了上下文增强模块(CEM)和空间注意力模块(SAM)。上下文增强模块通过结合多尺度的特征映射来增强局部和全局信息。空间注意力模块使用RPN中学习到的信息来细化ROI warping中的特征分布。
相关工作:
前面两段主要是介绍了目标检测算法分为one-stage和two-stage两部分和当前可以达到实时检测的算法。最后一段介绍的是目标检测算法里面的基础网络结构,大多数的检测算法的基础网络结构都是从物体分类里面直接拿来使用,但是分类和检测存在着很多的区别,分类注重的是语义信息,检测更多的关注感受野的大小。轻量级检测算法还受益于当前一些小网络如mobilenet和shufflenet。通过分析前面轻量级基础网络的不足之处,作者提出了一种新的轻量级的基础网络结构。
ThunderNet:
基础网络结构:
输入分辨率:
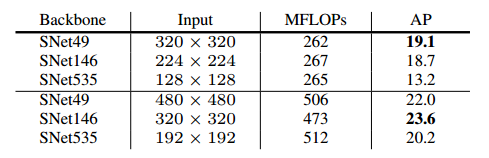
输入图像大小是320×320.作者通过实验找到最佳的图像分辨率,如下图所示。
基础网络结构:
如下图所示,基础网络结构使用的书shufflenet v2的结构块。将所有的3×3的卷积改成5×5的卷积。

感受野:感受野的大小对于CNN来说至关重要。在目标检测领域,大的感受野对于检测大目标物体效果要好,小感受野对于检测小目标物体效果要好。
前期特征和后期特征:前期特征图比较大可以更好地描述空间细节。后期特征图比较小,语义信息丰富,更具判别能力。通常认为,前期特征对于目标检测十分重要,后期特征对于分类来说特别重要。但是作者通过实验发现前期特征和后期特征对于目标检测来说都十分重要。
为了能够更好地收集前期和后期特征作者在ShufflNetV2的基础上提出了SNet。SNet49速度更快,SNet535精度更高,SNet146权衡精度和速度。SNet首先将所有的3×3深度可分卷积替换成5×5的深度可分卷积。在实践过程中,5×5的卷积和3×3的卷积运行时间是一样的,并且5×5的卷积可以增大感受野(121增加到193).在SNet146和SNet535中,作者删除了conv5卷积层,增加了前面卷积层的通道数,这样做的目的是可以增加更多的前期特征。在SNet49中作者将conv5的通道数压缩到512,同时增加前面卷积层的通道数,目的和前面是一样的为了平衡前期和后期特征。
检测部分:
压缩RPN:使用5×5的深度卷积来代替之前的3×3的普通卷积。
压缩检测头:Light-Head R-CNN输出通道数是10*7*7.作者将10缩小到5。
上下文增强模块:Light-Head R-CNN使用Global Convolutional Network (GCN)增加感受野,但是会增加大量的计算量。为了增加感受野作者采用特征金字塔的网络结构。传统的特征金字塔包含太多的卷积层和检测分支,这样会增加计算量。作者就在特征金字塔的基础上进行了改进。作者提出的上下文增强模块通过结合多尺度的局部上下文信息和全局信息来生成更具判别的特征。

上图是上下文增强模块的一个网络结构。C4,C5,Cglb是三种不同尺度的特征图,通过卷积层江通道数都恢复到245个,然后再通过上采样将特征图变为20×20。最后再将特征图相加传到fc层里面输出结果。上下文增强模块可以有效地提升特征图感受野的大小,并且计算量很少只使用了少量的卷积层和fc层。
空间注意力模块:在ROI warping中,我们希望背景信息和前景信息之间的差别很大,但是我们的网络结构由于太浅很难学到有效的特征分布。为了解决这个问题,作者在ROI warping之前对特征图就行重新加权操作。空间注意力模块的核心就是使用RPN的信息对特征图重新定义特征分布。
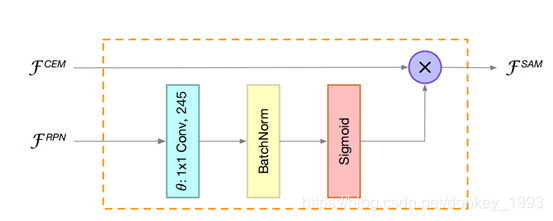
上图是注意力模块的网络结构图。输入是RPN和上下文增强模块的结果,最后输出特征图更好的特征分布。卷积层采用的是1×1的卷积,这样可以减少计算量。注意力模块的作用1.是抑制背景信息,增强前景信息。2. 稳定RPN的训练,因为RPN要接受RCNN子网的监督,可以帮助训练RPN网络。
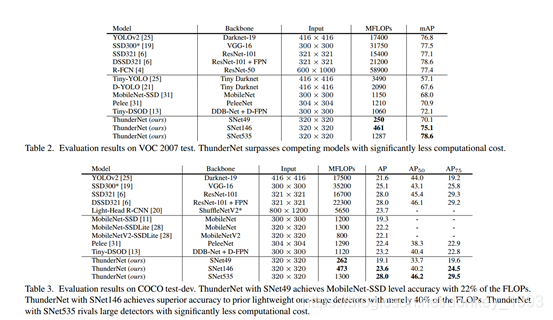
实验结果:















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









