








ICCV-2019
文章目录
1 Background and Motivation
CNN-based detectors 一般构成如下,
- backbone part
- detection part
- one stage(directly predict bounding boxes and class probabilities.)
- or two stage(RPN+head)
现在的 CNN-based detectors 都是 resource-hungry 的,需要大量的 computation 才能达到 ideal detection accuracy,显然难以落地到移动端上。
更细致的分析:
1)backbone part
backbone part 主要是根据 classification 任务来设计的, classification 任务不需要定位,object detection 任务需要定位(精确的定位需要 large receptive field 和 low-level feature) ,作者说 object detection 和 classification 的这种 gaps obstructs further compression without harming detection accuracy.
2)detection part
two stage detectors 中,头部计算量虽然经过几次精简(eg:R-FCN,light head RCNN),但把 backbone 压缩下来以后还是显得头重脚轻,This imbalance not only induces great redundancy but makes the network prone to overfitting
one stage detectors 只在 backbone 后面接几个卷积层,计算量比 two stage 小,所以被广泛的用于 real-time detection 中。However,one stage 没有 RoI-wise feature extraction and recognition,结果会比 two stage coarser 一些,压缩以后,效果会进一步 aggravated!
one stage 快,two stage 好,能否中西结合? Can two-stage detectors surpass one-stage detectors in real-time detection?
作者提出了在移动设备上 generic 的 object detection 模型,区别于以往的 one-stage 的 lightweight 模型,作者在 two-stage 上开始了他的精雕细琢!
2 Advantages / Contributions
提出 ThunderNet,first real-time detector reported on ARM platforms(24.1 fps on an ARM-based device with 19.2 AP on COCO)
这个频率好像刚刚能摆脱幻灯片,开始看动画片了
3 Method
-
设计 SNet backbone
-
压缩 Light Head R-CNN 的头
-
设计 Context Enhancement Module (CEM) and Spatial Attention Module (SAM) 来 eliminate 压缩后的影响
3.1 Backbone part
1)Input Resolution
input resolution should match the capability of the backbone
2)Backbone Networks
simply transferring classification networks to object detection is not optimal
大感受野的好处,有 more context information,能编码 long range relationship between pixels more effectively,定位大的物体需要大的感受野
backbone 中 early stage features 是 describe spatial details,有利于定位,late-stage features 更具有 discriminative 有利于分类,两者都很重要!
总结,好的 backbone 需要大感受野,强的 early stage features 和 late-stage features
作者在 ShuffleNet 的基础上设计了 SNet,

3
∗
3
3*3
3∗3 depth-wise conv to
5
∗
5
5*5
5∗5 来增加感受野,
SNet146 SNet535 中 remove 了 conv5,增加前面 features 的 channels,来增强 early stage features,
SNet 49 中移除 conv5,编码信息不够,保留,early stage feature 相对弱,作者把 conv5 channel 砍半了,1024 to 512,让 early stage 和 late stage 的 feature 取得较好的平衡
3.2. Detection Part
backbone 和 detection part 计算量不平衡,not only leads to redundant computation but increases the risk of over-fitting

1)RPN
作者对 RPN 的改进:256 channels 的 3 ∗ 3 3*3 3∗3,变成 256 channels 的 5 ∗ 5 5*5 5∗5 depth-wise 和 1 ∗ 1 1*1 1∗1,5 scales 和 5 ratio,来增大感受野
2)Context Enhancement Module
对 FPN 的改进,来 aggregate multi-scale local context information and global context information to generate more discriminative features.

1
∗
1
1*1
1∗1 conv to 245,
245
=
α
∗
p
∗
p
=
5
∗
7
∗
7
245 = \alpha * p *p = 5*7*7
245=α∗p∗p=5∗7∗7,最后合成一个
3)Spatial Attention Module

SAM 的输入 是
F
C
E
M
F^{CEM}
FCEM 和
F
R
P
N
F^{RPN}
FRPN,输出是
F
S
A
M
F^{SAM}
FSAM,用 RPN 来作注意力的激活权重,666!
对应图1中

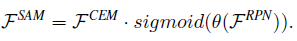
SAM 有两个作用,
- refine the feature distribution by strengthening foreground features and suppressing background features(这就是为什么用 rpn 特征图来算激活权重的原因了)
- 从上图看出,多了 SAM,RPN 的梯度反向传播多了一条路径(RPN receives additional supervision from RCNN subnet),文中说,这有利于 RPN 的训练!

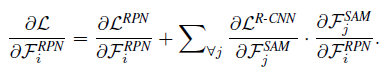
也就是多了后面一项,从 R-CNN subnet 模块过来的经过 SAM 流回 RPN
4 Experiments
detail
- Multi-scale training
- OHEM
- soft-NMS
- Cross-GPU Batch Normalization
4.1 Datasets
- PASCAL VOC
- COCO
4.2. Results on PASCAL VOC
07+12 trainval 来 train 07 test 来 test,

又快又好
4.3 Results on MS COCO
trainval35k for training
minival for validation
single-model results on test-dev

A P 75 AP_{75} AP75 的强势,可以看出有更好的定位能力,感受一下

4.4. Ablation Experiments
1)Input Resolution

什么样的脚穿什么样的鞋,小脚大鞋,大脚小鞋都不合脚
2)Backbone Networks

3)Comparison with Lightweight Backbones

4)Detection Part

5)Balance between Backbone and Detection Head

the capability of the backbone and the detection head should match
4.5 Inference Speed

5 Conclusion(own)
- 用 RPN 来做空间注意力的激活权重,脑洞大,达到增强前景,抑制背景的作用
- 提高目标检测的性能,需要大感受野, early stage features 和 last stage features 并重















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









