










非线性回归 Logistics-Regression 模块实现与源码解读 深度学习 Pytorch笔记 B站刘二大人(5/10)
数学推导
什么是logistics函数
在定义上Logistic函数或Logistic曲线是一种常见的S形函数,它是皮埃尔·弗朗索瓦·韦吕勒在1844或1845年在研究它与人口增长的关系时命名的。广义Logistic曲线可以模仿一些情况人口增长(P)的S形曲线。起初阶段大致是指数增长;然后随着开始变得饱和,增加变慢;最后,达到成熟时增加停止。
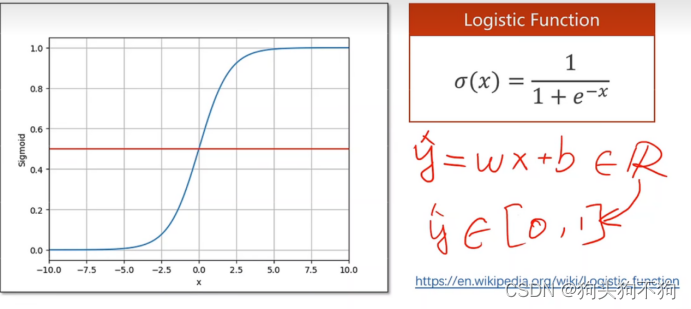
在数学上logistics函数同样具有着重要的意义:将数据转换到(0,1)区间内,可能看起来并没有什么不同,但是当一旦实际问题与概率相关时,或者涉及二元的是非问题时,logistics函数就表现出非常重要的作用。
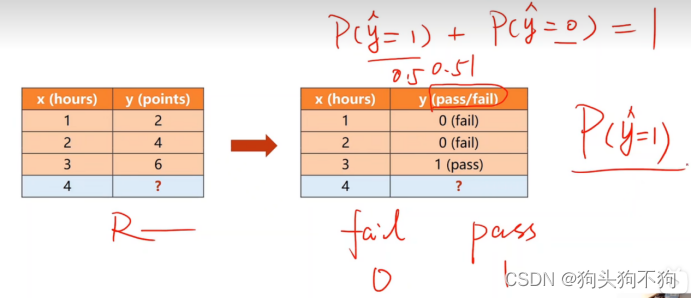
如图,当预测数据是否通过标准时,传统的线性回归模型将回归一个定量值,而定量数值是无法阐述定性问题的,因为两者的量纲有着本质区别。此时只需要将定量模型的输出经过logistics环节,就可以将定量输出映射到(0,1)概率区间内,进一步获得定性结果,完成判断
对于需要完成判断任务的深度学习模型由于基础线性层输出的实际值实际上在整个实数范围内,不一定在0-1之间,因此需要对输出值进行转化,及将输出值进行logistics激活,logistic函数也是饱和函数,一般来说在数学表达中以σ表示sigmoid函数,重要性质:可以保证输出在0-1之间。
损失函数变化

显然,当引入了激活函数sigmoid函数,之前线性模型的损失函数也不再适用。
在此对损失函数进行解读,损失函数主要由两部分组成(下面以 y_ out代替表示模型输出值 )
- 第一部分

上式中y为实际标签值(实际标签值只为0或1),当实际值预测为真,即实际值为1时,第二部分为零,该项(第一部分)作为损失函数loss的输出值: ln (y_out)
需要注意的是,上式中的 log 其实表达的是 In 运算。当输出值越靠近1,即输出值为True的概率越大时,损失值loss越小(注意此时y_out的取值范围为(0,1),In(y_out)的取值范围为(-∞,0),-In(y_out)的取值范围为(0,∞)),反之损失值越大。
- 第二部分
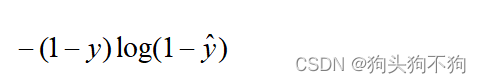
上式中y为实际标签值(实际标签值只为0或1),当实际值预测为假,即实际值为0时,第一部分为零,该项(第二部分)该项作为损失函数loss的输出值: ln (1 - y_out)
同样,上式中的 log 实际表达是 In 运算,当输出值越靠近0,即输出值为False的概率越大时,损失值loss越小(注意此时y_out的取值为(0,1),In(1-y_out)的取值为(0,-∞),-In(1-y_out)的取值范围为(∞,0)),反之损失值越大。
至此完成了对损失函数的数学分析,在理解层面应当将损失函数理解为由实数值差(有意义,在数轴上计算两值距离,希望数值最小化),logistic函数的损失函数表示分布(分类为1时的概率分布,比较两个分布之间的差异)/交叉熵函数
交叉熵函数
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。

在理解上,可以理解为交叉熵函数结果表示两分布的差异,越大越好,将期望由最大转化为最小

代码解读
画图代码`
import matplotlib.pyplot as plt
# plot
x = np.linspace(0, 10, 200) # 生成数值在0-10之间,长度200个的向量x
x_t = torch.Tensor(x).view(200, 1) # 转换为tensor数据
y_t = model(x_t) # 计算模型预测值
y = y_t.data.numpy() # 转换为numpy数据类型
plt.plot(x, y) # 绘制
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
结果:

整体代码
''' coding:utf-8 '''
"""
作者:shiyi
日期:年 09月 01日
通过pytorch复现logistics回归
"""
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# 准备数据
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
# 定义logistics模型
class LogisticRegressionModuel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModuel, self).__init__() # 魔法方法重写类
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = F.sigmoid(self.linear(x)) # 用sigmoid函数激活线性层
return y_pred
model = LogisticRegressionModuel() # 实例化
criterion = torch.nn.BCELoss(size_average=False) # 计算损失函数,损失函数累积,不取平均值
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # SGD方法进行梯度下降,获取模型数据,优化步长为0.01
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data) # 计算损失
print(epoch, loss.item())
optimizer.zero_grad() # 之前的积累梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred =', y_test.item())
# plot
x = np.linspace(0, 10, 200) # 生成数值在0-10之间,长度200个的向量x
x_t = torch.Tensor(x).view(200, 1) # 转换为tensor数据
y_t = model(x_t) # 计算模型预测值
y = y_t.data.numpy() # 转换为numpy数据类型
plt.plot(x, y) # 绘制
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
结果
990 1.1588373184204102
991 1.1582283973693848
992 1.1576207876205444
993 1.1570135354995728
994 1.156407117843628
995 1.155801773071289
996 1.1551969051361084
997 1.154592752456665
998 1.1539894342422485
999 1.1533868312835693
y_pred = 0.8327455520629883















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











