







上次读到这本书的第二章,第三章的内容较多,也做了一些扩展,所以单独出来。

#
“In fact, with the change in cost function it’s not possible to say precisely what it means to use the “same” learning rate.”
Cross -entropy function is a way to solve the neuron saturation problem,is there other way?
Sigmoid+cross_entropy VS softmax+log-likehood
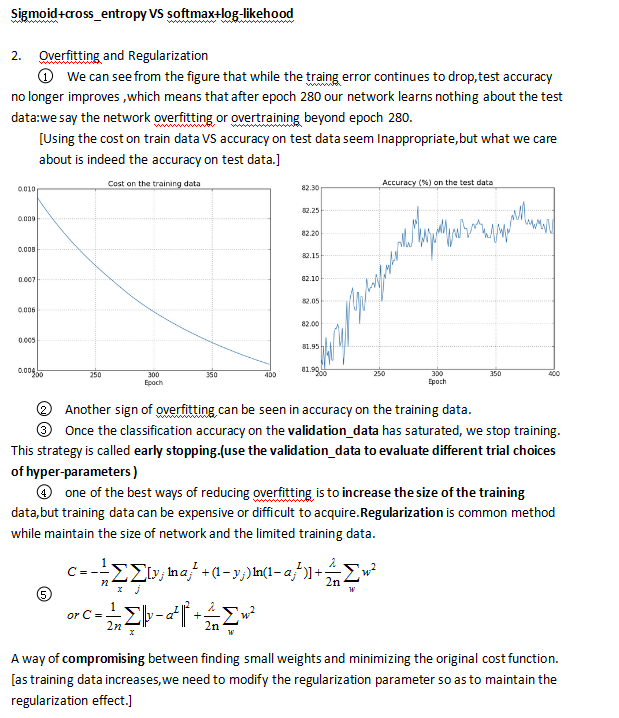
#
Indeed, researchers continue to write papers where they try different approaches to regularization, compare them to see which works better, and attempt to understand why different approaches work better or worse. And so you can view regularization as something of a kludge. While it often helps, we don’t have an entirely satisfactory systematic understanding of what’s going on, merely incomplete heuristics and rules of thumb.
#
It’s like trying to fit an 80,000th degree polynomial to 50,000 data points. By all rights, our network should overfit terribly. And yet, as we saw earlier, such a network actually does a pretty good job generalizing. Why is that the case? It’s not well understood. It has been conjectured that “the dynamics of gradient descent learning in multilayer nets has a `self-regularization’ effect“. This is exceptionally fortunate, but it’s also somewhat disquieting that we don’t understand why it’s the case.

#
there’s a pressing need to develop powerful regularization techniques to reduce overfitting, and this is an extremely active area of current work.

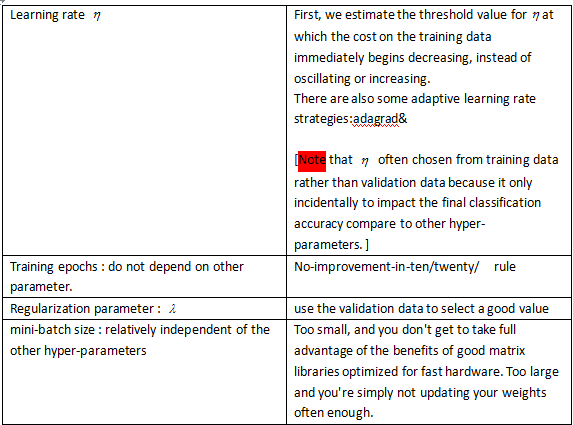
5.How to choose a neural network’s hyper-parameters?
① strip the problem down:such as simplify the problem so it can gives you rapid insight into how to build the network.
② stripping your network down to the simplest network likely to do meaningful learning.
increasing the frequency of monitoring of the network so that you can get quick feedback.
#
carefully monitoring your network’s behaviour
#
Your goal should be to develop a workflow that enables you to quickly do a pretty good job on the optimization, while leaving you the flexibility to try more detailed optimizations, if that’s important.
#
While it would be nice if machine learning were always easy, there is no a priori reason it should be trivially simple.
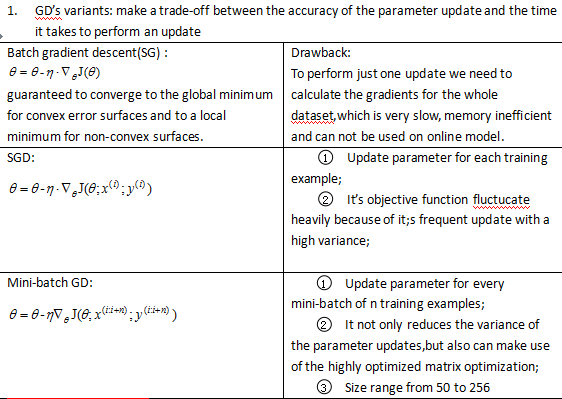
Some remain challenges:
1)A proper learning rate is difficult to choose, and the learning rate schedules are pre-defined which unable to adaptation to the dataset’s characteristics.
2)In practical , our data is sparse and the features may have very different frequencies ,but we apply the same learning rate to all parameter updates.perhaps update parameter in different extent is a more suitable way.
3)minimizing highly non-convex error functions ‘s difficulty in fact not from local minima but from saddle poitns ,i.e.points where one dimension slopes up and another slopes down,because these saddle points are usually surrounded by a plateau of the same error.,which makes it notoriously hard for SGD to escape.

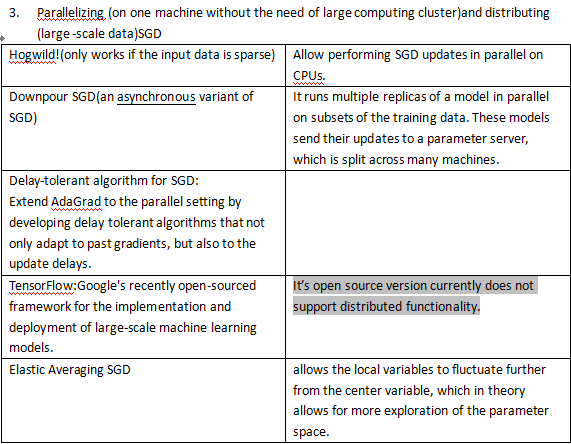
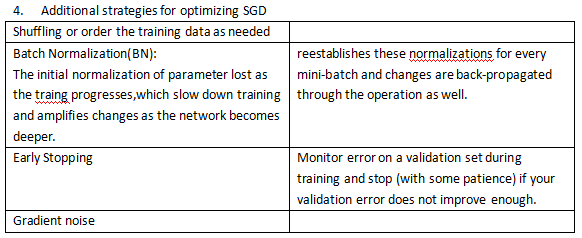
Trick:
Since some of the weights may need to increase while others need to decrease. That can only happen if some of the input activations have different signs. So there are some empirical evidence to suggest that the tanh sometimes performs better than sigmoid.
REFERENCE:
[1]Practical Recommendations for Gradient-Based Training of Deep Architectures.Yoshua Bengio
[2]http://sebastianruder.com/optimizing-gradient-descent/

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









