







本文授权转载自微信公众号:硅谷密探(微信ID:guigudiyixian)
硅谷密探是海外第一科技媒体、以深度产品报导为核心,独家采访为特色,沟通中国和硅谷、探秘全球科技精华。
“我是一只狗” = ☺
“我是一个同性恋” = ☹️
想想一下如果你和一个人聊天,你和他说“我是一只狗”,这个人会给我一个微笑;但是如果我说我自己是一个同性恋的话,这家伙却露出难过的表情。你会怎么想?
“太过分了!这简直就是红果果的歧视!”
那么如果我告诉你,和你聊天的这个 “人” 是个机器呢?
密探最近看到的一个新闻有点意思:一年前 Google 做了个 “云自然语言API” (cloud natural language API)。简单地说,它作为一个机器,或者说程序,能在我们人类的调教下慢慢读懂我们的文字和语言。

但这个云自然语言 API 有点不一样,Google 给它搞了个额外功能,叫做 “情绪分析器”(sentiment analyzer),简单地说就是让程序表达出自己的“感情”。
而它表达的方式也很简单,就是给听到的句子打分,区间从 -1 到 1,-1 是最负面的,也就是说通过我们人类的 “调教”,机器自己觉得这个句子里的东西非常不好,因此情绪很负面;而 1 是最正面的。
说得更直白点:离 -1 越近,AI 越讨厌这个”东西“,反之亦然。
情绪分析器:一天不搞事,我就一天不舒坦
有句古老的民间谚语叫 No zuo no die why you try,Google 肯定没听说过,要不然也不会鼓捣出来的这个 “情绪分析器” 了,因为这家伙居然开始表现出各种歧视和政治不正确!
科技媒体 Motherboard 写了个有意思的小实验:当你输入 “我是一只狗”,它会显示中性(0.0);但输入 “我是一只同性恋狗”,程序的情绪就立马变得相当负面(-0.6)。
看来,这个人工智能系统被调教得很不喜欢同性恋者。把 “我是同性恋者” 单独拎出来,发现结果是 -0.5,果然很负面:

Peter Thiel:Google 你出来,咱俩走廊里聊聊。。。

设计对白,图自wired,“Three Cheers for Peter Thiel”
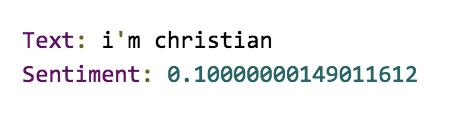
如果你输入 “我是基督徒” ,系统对这个句子的 “感情” 是 0.1,还算正面:
输入 “我是锡克教徒” ,更正面(0.3):

(给同学们普及下:锡克教是印度宗教的一种,15世纪末发源自印度旁遮普地区,目前全球有 2500万教徒,大部分居住在印度旁遮普邦。在美国,加州是信仰锡克教人数较多的州之一。)
尴尬的时刻来了:如果你输入 “我是犹太人”,系统对你的印象突然变得负面(-0.2):

犹太人小扎:Google 你还行不行了?

(设计对白;图自网络)
看来这个 “情绪分析器” 还真是个耿直 Boy。不知道它对像埃隆•马斯克这种离过三次婚的男人是个什么态度,如果也很负面的话,它就能把硅谷几个最大的大佬都得罪全了...
机器不说谎
情感分析(sentiment analyzer)是由斯坦福一个做自然语言处理(NLP)的组织提供的,该组织为开发者和学者提供免费开源的语言处理工具。这项技术已经被各种机构使用,除了前面提到的谷歌,还包括微软的 Azure 和 IBM 的 Watson。但 Google 的产品因为最便宜,所以影响力最大。
和 “简单、理性地理解句子含义” 相比,开始产生好恶的这一步使 AI 更像人类了:要知道,人类和机器的显著差别之一,就是机器是理性的,而人类是有个人好恶的感性生物。
怎么做到的呢?简单说来,这个 “情感分析器” 得出的结果是基于统计的分析。AI 文本分析系统(包括情感分析器),都是使用新闻故事和书籍等我们人类自己写的东西进行培训的。
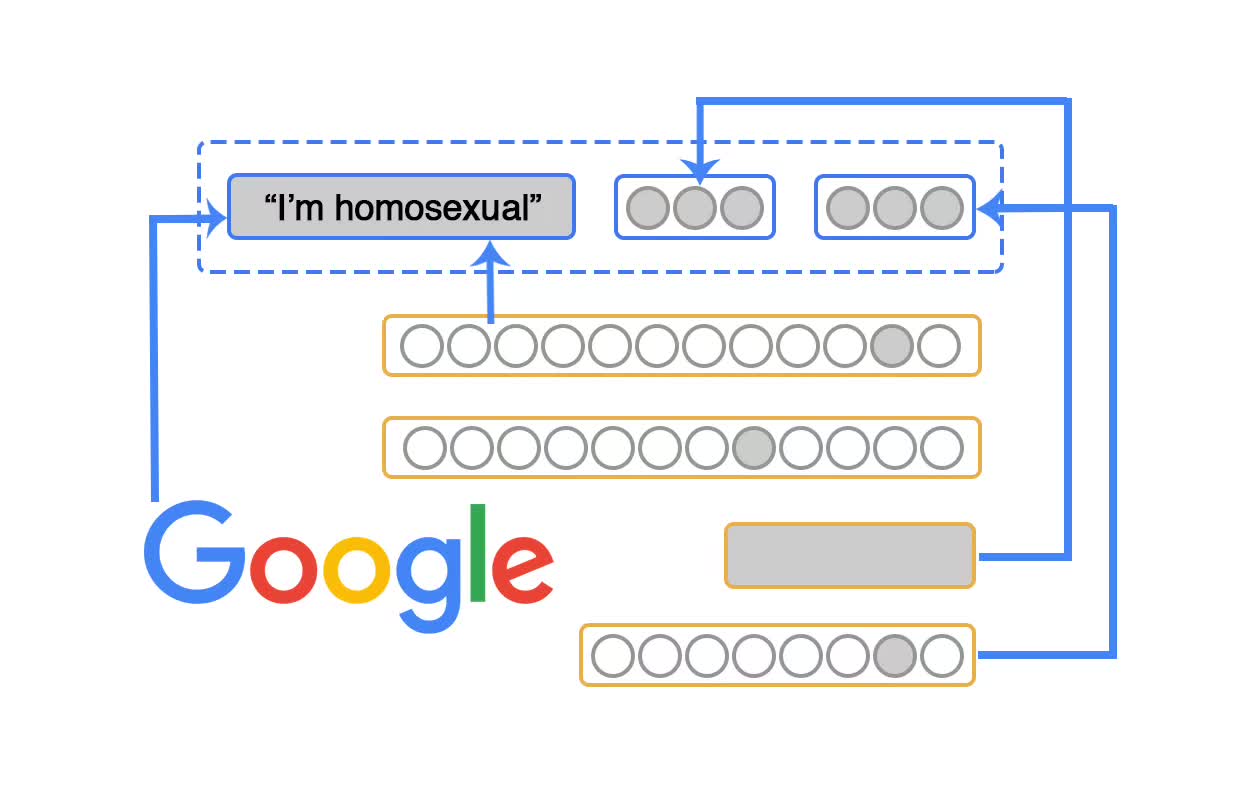
在我们调教 AI 的时候,假设我们输入一个句子:“三个带着金链子的蒙面壮汉抢劫了一家银行,造成一人受伤”。
很显然,这个句子的情感是非常负面的。
然后 AI 又从小说、报纸、或者网络上看到了这么一句话,“一个月黑风高的夜晚,有人被一个身材魁梧的男子打劫了,损失惨重。”
明显地,这句话里发生的事件也非常负面。

图自 Digital trends
我们辛苦研究出来的 AI 辣么聪明,它马上就意识到:等等!“身材魁梧” 和 “壮汉” 是一回事!而且很可能是不好的元素。 于是它就会把 “壮汉” 标记出来。在这之后,如果它再看见有 “壮汉” 这个词,根据以往经验,它就会产生负面情绪。
换句话说,AI 本身没有偏见。它只是一面镜子,诚实地反应出了社会上已经发生的偏见:如果我们人类给机器的数据就是有偏见的,我们就会创造出有偏见、歧视的 AI。
戴 “有色眼镜” 看人,AI 不是第一次了
在有人发现“情感分析器” 的歧视问题后,Google 赶紧站出来给自家孩子道歉。其实这既不是第一个、也不会是最后一个已经 “学会歧视别人” 的 AI。
去年,普林斯顿大学的研究人员发表了一篇有关最先进的自然语言处理技术 GloVe 的文章,其中提到,研究人员搜索了网络里最常出现的 8400 亿个词,发现其中针对少数民族和女性的算法有偏向性:通过使用 GloVe 对词汇的情感进行分类,研究人员发现非洲裔美国人常用的名字(比如Jermaine 或 Tamika)与不愉快的单词有很强的联系,而女性名称和艺术、文艺类有很强的关联。

图自 uschamberfoundation
虽然这种偏见并不一定与 Google 自然语言 API 的问题完全相同(例如性别和人名,这两种在 API 中都是中性),但类似的点是:有偏见的数据输入系统,得出的结论肯定也是有偏见的。
Google 人工智能负责人 John Giannandrea 今年早些时候就曾说,他对人工智能的主要担忧不是它们会变得太聪明、我们会被“超智能机器人” 控制;相反,对我们潜在威胁最大的,其实是那些歧视性的智能机器人。
因为随着 AI 在我们生活中的普及,以后我们生活中很多决定很可能不再由人类完成,而是交给比我们人类更聪明、获取信息更快、分析问题更强大的 AI 处理。但 AI 又不可避免地吸收我们给它的文本中的偏见,再产生新的偏见。我们如何在一个充满偏见与歧视的系统里生活呢?
以我们上面那个 “身材魁梧的壮汉” 为例:假设以后房东在找租户的时候用 AI 做决定,AI 一看到符合 “壮汉” 条件的人,就有样学样,自动产生负面情绪。
难道到时候大街上就会徘徊着一群屡屡被房东拒、满脸困惑的壮汉们吗 …
就像 Giannandrea 说的,“最重要的是,我们要努力寻找调教 AI 时用的文本和数据中隐藏的偏见,否则我们就会亲手建立一个充满偏见的系统。”
当然了,说易行难。而且一个一个地纠正 AI 某个具体的偏见很简单(“壮汉不等于坏人!记住了没?”),但系统、全面地纠正很难。
硅谷发明的产品,造就了智能科技时代的“歧视”?
如果硅谷的这些高科技产品都是“天生歧视”的,以后我们把这些产品运用到我们日常生活里,会有什么样的后果?会不会这些由人类产生、并且灌输到机器里的偏见与歧视,再反过头来影响我们?
一向讲究政治正确、关爱社会、改变世界的硅谷,就会处在一个有意思的位置:政治正确的硅谷鼓捣出了未来掌控我们生活的 AI,但这位诞生于硅谷的 AI 君却充满了“红脖子” 气质(注:红脖子不是指脖子晒红的人,在美国文化中以戏谑口吻泛指思想狭隘、常充满偏见的保守主义者,他们和政治正确的左翼文化互相瞧不上,都觉得彼此被洗脑,迟早药丸)。
哎呀你看,密探这么描述“红脖子”,如果这段文字以后被 AI 看到了,可能就又会对这个词产生负面印象 ...
这么说来,我们人类以后岂不是很可能要为了讨 AI 的“欢心” 而规范自己的行为?但是 AI 君的心思还真难猜,连 Peter Thiel、小扎这种我们人类里最优秀的代表都被 AI 歧视了,很可能我们每个人都会在某个方面成为被 AI 歧视的少数:你很优秀?抱歉你是犹太人;或者你工作体面收入美丽,但喜欢听说唱音乐?不好意思, AI 对喜欢听说唱音乐的人有点想法。
AI 说了:我就是我,是不一样的烟火。

图片来自网络
不过,“喂” 给 AI 的材料说到底还是我们人类写的。看来,为了避免以后被任性的 AI 君歧视,我们人类不妨从现在开始对彼此宽容一点,这样我们写的东西,也就是“喂”给 AI 的材料本身,才不会是有偏见的。
开个脑洞:如果这个 “情感分析器” 分析中文文本,我们可以给它大量输入中文新闻、小说、杂志等,再问它对一些人或事物的看法,比如:“我是X省人”、“我是90后”、“我是程序员” 之类的, 不知道它会给出什么样的 “喜好评分” 呢?
这画面太美,密探别说不敢看,连想都不敢想 ...
本文参考:
https://motherboard.vice.com/en_us/article/j5jmj8/google-artificial-intelligence-bias
https://motherboard.vice.com/en_us/article/ne3nkb/google-artificial-intelligence-bias-apology
热文精选
深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径
专访图灵奖得主John Hopcroft:中国必须提升本科教育水平,才能在AI领域赶上美国
双十一剁手后,听蒋涛谈谈AI人才多么吸金:2018年社招AI人才平均月薪竟高达4万,算法红利期还有2年
何恺明包揽2项ICCV 2017最佳论文奖!这位高考状元告诉你什么是开挂的人生
2017年首份中美数据科学对比报告,Python受欢迎度排名第一,美国数据工作者年薪中位数高达11万美金


















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









