






缺失数据处理
其实在很多时候,人们往往不愿意过多透露自己的信息。假如您正在对用户的产品体验做调查,在这个过程中您会发现,一些用户很乐意分享自己使用产品的体验,但他是不愿意透露自己的姓名和联系方式;
还有一些用户愿意分享他们使用产品的全部经过,包括自己的姓名和联系方式。
因此,总有一些数据会因为某些不可抗力的因素丢失,这种情况在现实生活中会经常遇到。
稀疏数据,指的是在数据库或者数据集中存在大量缺失数据或者空值,我们把这样的数据集称为稀疏数据集。稀疏数据不是无效数据,只不过是信息不全而已,只要通过适当的方法就可以“变废为宝”。
稀疏数据的来源与产生原因有很多种,大致归为以下几种:
由于调查不当产生的稀疏数据;
由于天然限制产生的稀疏数据;
文本挖掘中产生的稀疏数据。
在pandas中,缺失数据显示为NaN。缺失值有3种表示方法,np.nan,None,pd.NA
1、np.nan
缺失值有个特点,它不等于任何值,连自己都不相等。如果用nan和任何其它值比较都会返回nan
np.nan == np.nan#返回False
也正由于这个特点,在数据集读入以后,不论列是什么类型的数据,默认的缺失值全为np.nan。
因为nan在Numpy中的类型是浮点,因此整型列会转为浮点;而字符型由于无法转化为浮点型,只能归并为object类型(‘O’),原来是浮点型的则类型不变。
遇到明明是字符型,导入后就变了,其实是因为缺失值导致的。
除此之外,还要介绍一种针对时间序列的缺失值,它是单独存在的,用NaT表示,是pandas的内置类型,可以视为时间序列版的np.nan,也是与自己不相等
None
还有一种就是None,它要比nan好那么一点,因为它至少自己与自己相等
在传入数值类型后,会自动变为np.nan
pandas1.0以后的版本中引入了一个专门表示缺失值的标量pd.NA,它代表空整数、空布尔值、空字符
对于不同数据类型采取不同的缺失值表示会很乱。pd.NA就是为了统一而存在的。 pd.NA的目标是提供一个缺失值指示器,可以在各种数据类型中一致使用(而不是np.nan、None或者NaT分情况使用)。
s_new[1] = pd.NA
s_new#会被替换为<NA>
对于缺失值一般有2种处理方式,要么删除,要么填充(用某个值代替缺失值)。 缺失值一般分2种,
一种是某一列的数据缺失。
另一种是整行数据都缺失,即一个空行
读取数据时,时间日期类型的数据缺失值用NaT表示,其他类型的都用NaN来表示。
查看缺失值
df.info()#通过查看日志
判断缺失值
isnull():判断具体的某个值是否是缺失值,如果是则返回True,反之则为False,会输出一张表格,标注每个值是否为空
删除缺失值
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis:{0或’index’,1或’columns’},默认为0 确定是否删除了包含缺少值的行或列
*0或“索引”:删除包含缺少值的行。
*1或“列”:删除包含缺少值的列。
how:{‘any’,‘all’},默认为’any’ 确定是否从DataFrame中删除行或列,至少一个NA或所有NA。
*“any”:如果存在任何NA值,请删除该行或列。
*“all”:如果所有值都是NA,则删除该行或列。
thresh: int 需要至少非NA值数据个数。
subset: 定义在哪些列中查找缺少的值
inplace:是否更改源数据
缺失值填充
一般有用0填充,
用平均值填充,
用众数填充(大多数时候用这个),众数是指一组数据中出现次数最多的那个数据,一组数据可以有多个众数,也可以没有众数
向前填充(用缺失值的上一行对应字段的值填充,比如D3单元格缺失,那么就用D2单元格的值填充)、
向后填充(与向前填充对应)等方式。
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, )
value: 用于填充的值(例如0),或者是一个dict/Series/DataFrame值,指定每个索引(对于一个系列)或列(对于一个数据帧)使用哪个值。不在dict/Series/DataFrame中的值将不会被填充。此值不能是列表。
method:ffill–>将上一个有效观察值向前传播 bfill–>将下一个有效观察值向后传播
axis:用于填充缺失值的轴。
inplace:是否操作源数据
limit:要向前/向后填充的最大连续NaN值数
# 将列“A”、“B”、“C”和“D”中的所有NaN元素分别替换为0、1、2和3。
values = {"A": 0, "B": 1, "C": 2, "D": 3}
df.fillna(value=values)
# 只替换第一个NaN元素
df.fillna(0, limit=1)
文件的分块读入:再最后加上iterator
在划分出来的组(group)上应用一些统计函数,从而达到数据分析的目的,比如对分组数据进行聚合、转换,或者过滤。这个过程主要包含以下三步:
拆分(Spliting):表示对数据进行分组;
应用(Applying):对分组数据应用聚合函数,进行相应计算;
合并(Combining):最后汇总计算结果。
group = data.groupby("company")
group
将上述代码输入ipython后,会得到一个DataFrameGroupBy对象
转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,
第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C),
第二个元素的是对应组别下的DataFrame
总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。
理解了这点,也就基本摸清了Pandas中groupby操作的主要原理。
agg聚合操作
求不同公司员工的平均年龄和平均薪水
data.groupby("company").agg('mean')
想对针对不同的列求不同的值,可以利用字典进行聚合操作的指定
data.groupby('company').agg({'salary':'median','age':'mean'})
transform
和agg有什么区别呢?
如果现在需要在原数据集中新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?
如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,不用transform的话
# to_dict将表格中的数据转换成字典格式
avg_salary_dict= data.groupby('company')['salary'].mean().to_dict()
avg_salary_dict
# map()函数可以用于Series对象或DataFrame对象的一列,接收函数作为或字典对象作为参数,返回经过函数或字典映射处理后的值。
data['avg_salary'] = data['company'].map(avg_salary_dict)
data
用transfer只需要如下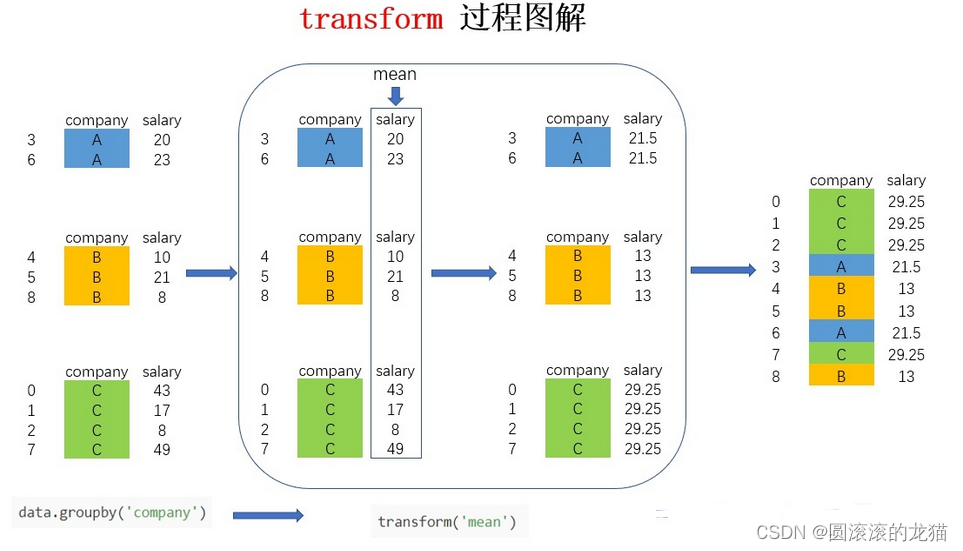
data['avg_salary1'] = data.groupby('company')['salary'].transform('mean')
data
apply
它相比agg和transform而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作
对于groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame
def get_oldest_staff(x):
# 输入的数据按照age字段进行排序
df = x.sort_values(by = 'age',ascending=True)
# 返回最后一条数据
return df.iloc[-1,:]
oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff)
oldest_staff
虽然说apply拥有更大的灵活性,但apply的运行效率会比agg和transform更慢。所以,groupby之后能用agg和transform解决的问题还是优先使用这两个方法,实在解决不了了才考虑使用apply进行操作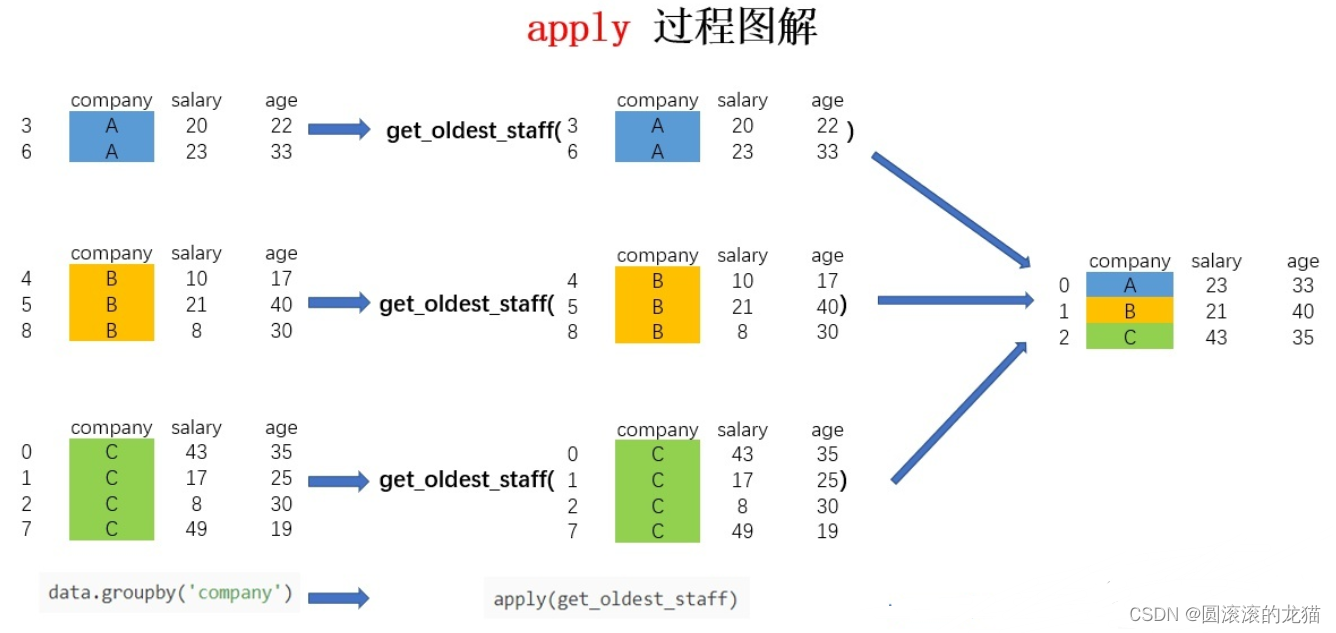















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









