






Logistic Regression
是一种分类方法
当估计的值属于一个连续空间时,这种任务称为回归任务
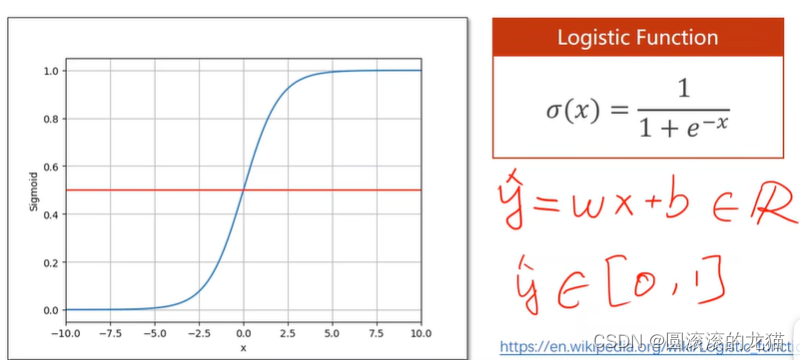
sigmoid神经元中最典型的一种
由于我们y^的输出是一个概率,要保证其输出的值属于[0,1]
这些都是sigmoid函数,要保证其函数有极限
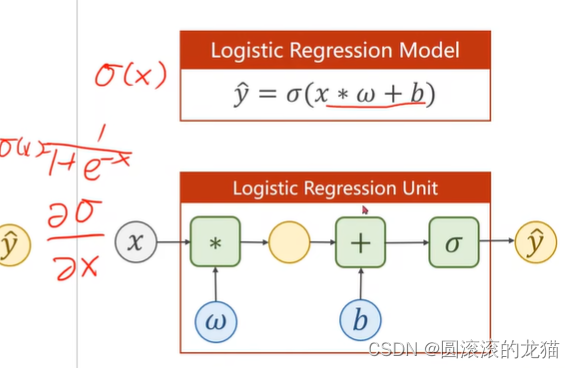
逻辑斯蒂的计算图

而我们输出的不再是数值,而是分布,比较的是两个分布之间的差异
此时,y^=P(class=1)
1-y^=P(class=0)
当y=0时y->1时log(y^)越小,反之y=1时类似
这个是交叉熵,主要用于衡量两个概率分布之间的差异。在机器学习中,特别是在分类问题中,交叉熵作为损失函数,用于评估模型的预测与真实标签之间的差异。交叉熵损失函数的目的是最小化模型预测分布与真实分布之间的差异,从而提高模型的预测准确性。
KL散度(Kullback-Leibler Divergence,也称为相对熵)是用来衡量两个概率分布之间差异的一种方法。它在信息论、统计学和机器学习中有广泛的应用。具体来说,KL散度用于衡量一个概率分布

import torch
from torch.utils.tensorboard import SummaryWriter
x_data=torch.tensor([[1.0],[2.0],[3.0]])#x
y_data=torch.tensor([[0],[0],[1]],dtype=torch.float32)#y
class LogisticRegression(torch.nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=torch.sigmoid(self.linear(x))
return y_pred
model=LogisticRegression()
criterion=torch.nn.BCELoss(reduction='sum')
optimistic=torch.optim.SGD(model.parameters(),lr=0.01)
writer=SummaryWriter('logic')
for epoch in range(100):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
optimistic.zero_grad()#清除梯度
loss.backward()#计算梯度
optimistic.step()#更新参数
writer.add_scalar('loss',loss.item(),epoch)
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test=torch.Tensor([[4.0]])
y_test=model(x_test)
print('y_pred=',y_test.data)
writer.close()















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









