






LLaMA
1,llama
参数范围7B 13B 33B 65B
在万亿token上训练的模型,
2,研究重点
研究表明,最好的模型性能不是由最大的模型体积实现,而是在更多的数据上训练较小的模型实现
工作重点是通过使用比通常更多的token,训练一系列语言模型,
3,架构:
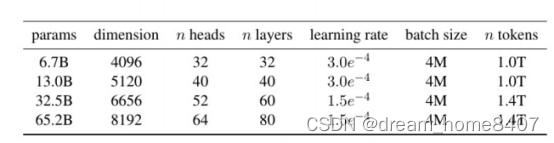
基于transforme架构,7B模型堆叠32个decoder模块,输入维度是4096,每个mutil head attention中头的个数32个,预训练模型是使用1T的token,
和transformer不同的是,为了提高训练的稳定性,作者对transformer子层的输入进行归一化,而不是输出部分,残差链结构在进行归一化,使用RMSNorm归一化函数,swiGLU激活函数,代替RELU
4,训练数据
练数据,全部来自公开数据集,不同领域混合数据,
英语commoncraw,fastText线性分隔器进行语言识别,并用ngram语言模型过滤低质量的内容,
c4,探索性实验中,实验者观察到使用不同的预处理数据集可以提高性能,去重和语言识别步骤,
ccnet的主要方法是质量过滤,去掉标点符号和网页中的单词和数字数量,去掉,
分 词 器,Sentence-Piece的 实 现

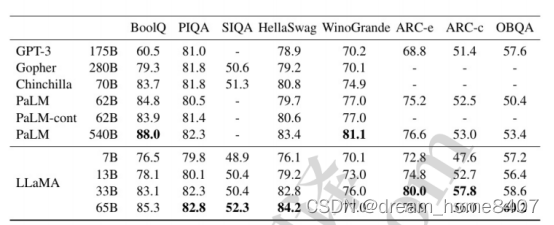
4,训练结果
当训练一个65b参数的模型时,我们的代码
在2048A100GPU上使用80GBRAM处理大约
380个令牌/秒/GPU。这意味着在我们包含1.4T
令牌的数据集上训练大约需要21天















 1666
1666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









