









相关系数
前言
我们将学习两种给最为常用的相关系数:pearson相关系数和spearman等级相关系数。它们可用来衡量两个变量之间的相关性的大小,根据数据满足的不同条件,我们要选择不同的相关系数进行计算和分析(建模论文中最容易用错的方法)。
理论知识
总体和样本
总体:所要考察对象的全部个体。
我们总是希望得到总体数据的一些特征(例如均值方差等)
样本:从总体中所抽取的一部分个体叫做总体的一个样本。
计算这些抽取的样本的统计量来估计总体的统计量。
例如使用样本均值、样本标准差来估计总体的均值(平均水平)和总体的标准差(偏离程度)。
例子:人口普查–总体数据
问卷–样本数据
总体Pearson相关系数
总体协方差:
Cov
(
X
,
Y
)
=
∑
i
=
1
n
(
X
i
−
E
(
X
)
)
(
Y
i
−
E
(
Y
)
)
n
\operatorname{Cov}(X, Y)=\frac{\sum_{i=1}^{n}\left(X_{i}-E(X)\right)\left(Y_{i}-E(Y)\right)}{n}
Cov(X,Y)=n∑i=1n(Xi−E(X))(Yi−E(Y))
直观理解协方差:如果x、y变化方向相同,即当x>(<)其均值是,y也>(<)其均值,在这种情况下,乘积为正。如果x、y的变化方向一直保持相同,则协方差为正;同理,如果x、y的变化方向一直保持相反,则协方差为负;如果x、y的变化方向之间相互无规律,即分子中有的项为正、有的项为负,那么累加后正负抵消。
注意:协方差的大小和两个变量的量纲有关,因此不能直接比较。
为了消除量纲的影响,我们就将x和y进行标准化,然后再求它们的协方差,这也就是Pearson相关系数
ρ
X
Y
=
Cov
(
X
,
Y
)
σ
X
σ
Y
=
∑
i
=
1
n
(
X
i
−
E
(
X
)
)
σ
X
(
Y
i
−
E
(
Y
)
)
σ
Y
n
\rho_{X Y}=\frac{\operatorname{Cov}(X, Y)}{\sigma_{X} \sigma_{Y}}=\frac{\sum_{i=1}^{n} \frac{\left(X_{i}-E(X)\right)}{\sigma_{X}} \frac{\left(Y_{i}-E(Y)\right)}{\sigma_{Y}}}{n}
ρXY=σXσYCov(X,Y)=n∑i=1nσX(Xi−E(X))σY(Yi−E(Y))
可以证明,
ρ
X
Y
\rho_{XY}
ρXY不大于1,想看证明的可以私信我。
样本Pearson相关系数
样本均值:
X
ˉ
=
∑
i
=
1
n
X
i
n
,
Y
ˉ
=
∑
i
=
1
n
Y
i
n
\bar{X}=\frac{\sum_{i=1}^{n} X_{i}}{n}, \bar{Y}=\frac{\sum_{i=1}^{n} Y_{i}}{n}
Xˉ=n∑i=1nXi,Yˉ=n∑i=1nYi
样本协方差:
Cov
(
X
,
Y
)
=
∑
i
=
1
n
(
X
i
−
X
ˉ
)
(
Y
i
−
Y
ˉ
)
n
−
1
\operatorname{Cov}(X, Y)=\frac{\sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)\left(Y_{i}-\bar{Y}\right)}{n-1}
Cov(X,Y)=n−1∑i=1n(Xi−Xˉ)(Yi−Yˉ)
样本Pearson 相关系数:
r
X
Y
=
Cov
(
X
,
Y
)
S
X
S
Y
r_{X Y}=\frac{\operatorname{Cov}(X, Y)}{S_{X} S_{Y}}
rXY=SXSYCov(X,Y)
其中:
S
X
(
S_{X}(
SX( sigma
X
)
X)
X)是
X
X
X 的样本标准差,
S
X
=
∑
i
=
1
n
(
X
i
−
X
ˉ
)
2
n
−
1
S_{X}=\sqrt{\frac{\sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)^{2}}{n-1}}
SX=n−1∑i=1n(Xi−Xˉ)2, 同理
S
Y
=
∑
i
=
1
n
(
Y
i
−
Y
ˉ
)
2
n
−
1
S_{Y}=\sqrt{\frac{\sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}}{n-1}}
SY=n−1∑i=1n(Yi−Yˉ)2
为什么样本差分母是n-1也可以私信我。
相关性可视化
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aCOKvcjF-1642944307260)(D:/typora%E5%9B%BE%E7%89%87/image-20220122193713468.png)]](https://img-blog.csdnimg.cn/fc7c538b953840bc98f368a05fdc2584.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_10,color_FFFFFF,t_70,g_se,x_16)
图片来源:[美]作者Pang-Ning Tan 《数据挖掘导论》
关于Pearson相关系数的一些理解误区
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zC6ysHli-1642944307262)(D:/typora%E5%9B%BE%E7%89%87/image-20220122194008500.png)]](https://img-blog.csdnimg.cn/74028832eac4458ab83afdf20ef12a48.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_14,color_FFFFFF,t_70,g_se,x_16)
上面四个图对应的数据的Pearson相关系数都是0.816
冰淇淋销量和温度之间的关系:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zIi9Rx0f-1642944307263)(D:/typora%E5%9B%BE%E7%89%87/image-20220122194110589.png)]](https://img-blog.csdnimg.cn/202e42a337c7495385fe50fd2933dae1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_10,color_FFFFFF,t_70,g_se,x_16)
这个的相关系数计算结果为0
小解释
这里的相关系数知识用来衡量两个变量线性相关的指标;也就是说,咱必须先确认这两个变量是线性相关的,然后这个相关系数才能告诉咱他俩的相关程度如何。
容易忽视和犯错的点
- 非线性相关也会导致线性相关系数很大
- 离群点对相关系数的影响很大
- 如果两个变量的相关系数很大也不能说明两者相关,可能是收到了异常值的影响
- 相关系数的计算结果为0,只能说不是线性相关,但说不定会有更复杂的相关关系(非线性相关)
两点总结
- 如果两个变量本身就是线性的关系,那么Pearson correlation coefficient 绝对值大的就是相关性强,小的就是相关性弱;
- 在不确定两个变量是什么关系的情况下,即使算出Pearson correlation coefficient ,发现很大,也不能说明两个变量线性相关,甚至不能说明它们相关,我们一定要画出散点图来看才行。
对相关系数大小的解释
| 相关性 | 负 | 正 |
|---|---|---|
| 无相关性 | -0.09~0.0 | 0.0~0.09 |
| 弱相关性 | -0.3~-0.1 | 0.1~0.3 |
| 中相关性 | -0.5~-0.3 | 0.3~0.5 |
| 强相关性 | -1.0~-0.5 | 0.5~1.0 |
其实上表所定的标准从某种意义上说是武断的和不严格的。对 correlation coefficient 的解释依赖于具体的应用背景和目的的。
事实上,比起相关系数的大小,我们往往更关注的是显著性(假设检验)。
例题实操
问题
现有某中学八年级所有男同学的体测样本数据,请见下表,试计算各变量之间的皮尔逊相关系数。
| 身高 | 体重 | 肺活量 | 50米跑 | 立定跳远 | 坐位体前屈 |
|---|---|---|---|---|---|
| 163 | 63 | 2073 | 9.2 | 208 | 10.5 |
| 158 | 59 | 2949 | 7.5 | 210 | 9.8 |
| 157 | 70 | 2173 | 8.1 | 210 | 10.7 |
| 158 | 59 | 2949 | 7.5 | 210 | 9.8 |
| 157 | 70 | 2173 | 8.1 | 210 | 10.7 |
| 170 | 64 | 2163 | 9.9 | 198 | 7.8 |
| 167 | 62 | 4058 | 9.5 | 180 | 7.5 |
| 160 | 55 | 2565 | 9.3 | 187 | 8.1 |
| 167 | 62 | 4058 | 9.5 | 180 | 7.5 |
| …… | …… | …… | …… | …… | …… |
描述性统计
Matlab数据分析
Matlab中基本统计量的函数:
| 函数名 | 功能 |
|---|---|
| min | 数组的最小元素 |
| max | 数组的最大元素 |
| mean | 数组的均值 |
| median | 数组的中位数值 |
| skewness | 数组的偏度 |
| kurtosis | 数组的峰度 |
| std | 标准差 |
首先把.xlsx数据变成.mat形式的数据文件。
这一步就是复制粘贴就OK了,保存为man就行。
clear;clc
load man %文件名如果有空格隔开,那么需要加引号
MIN = min(man); % 每一列的最小值
MAX = max(man); % 每一列的最大值
MEAN = mean(man); % 每一列的均值
MEDIAN = median(man); %每一列的中位数
SKEWNESS = skewness(man); %每一列的偏度
KURTOSIS = kurtosis(man); %每一列的峰度
STD = std(man); % 每一列的标准差
RESULT = [MIN;MAX;MEAN;MEDIAN;SKEWNESS;KURTOSIS;STD] %将这些统计量放到一个矩阵中表示
然后将得到的结果复制到excel表格中
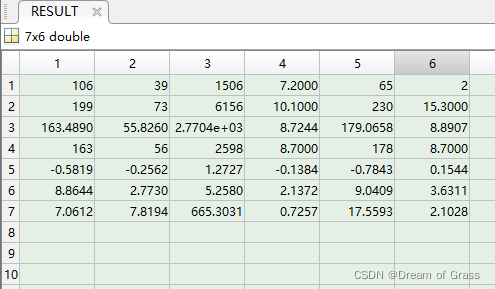
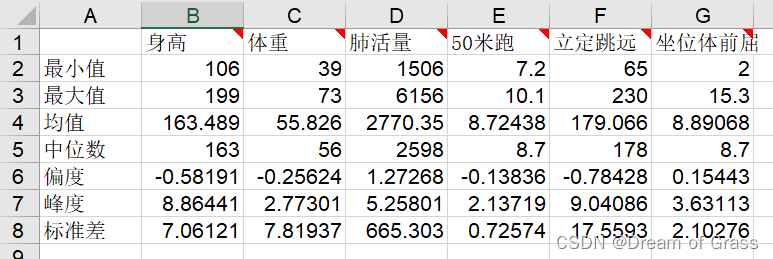
SPSS数据分析
直接导入excel数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0obL9bP6-1642944307264)(D:/typora%E5%9B%BE%E7%89%87/image-20220123120921249.png)]](https://img-blog.csdnimg.cn/d3dc60e6529a4db5b0b2449f35e6576b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_12,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBskYEfv-1642944307265)(D:/typora%E5%9B%BE%E7%89%87/image-20220123120853544.png)]](https://img-blog.csdnimg.cn/cdc11078fdb0496896e10de571e535a3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_12,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PDNYsX0R-1642944307267)(D:/typora%E5%9B%BE%E7%89%87/image-20220123121159641.png)]](https://img-blog.csdnimg.cn/3c9bd22b90404b7aafe21c8f51158e12.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_8,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hX8RNaB6-1642944307268)(D:/typora%E5%9B%BE%E7%89%87/image-20220123121357064.png)]](https://img-blog.csdnimg.cn/997817935021431dbd507b194e928777.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_17,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qoycL2au-1642944307270)(D:/typora%E5%9B%BE%E7%89%87/image-20220123121430905.png)]](https://img-blog.csdnimg.cn/53b88dab0d9f4828844c5e282ee04f95.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BPEmwHzX-1642944307270)(D:/typora%E5%9B%BE%E7%89%87/image-20220123121948497.png)]](https://img-blog.csdnimg.cn/5998cbca2dc4440aa108761f0fbc62b2.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_12,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NJsPd13b-1642944307271)(D:/typora%E5%9B%BE%E7%89%87/image-20220123121906966.png)]](https://img-blog.csdnimg.cn/4c14b4bd75cd4d31a41dda972987110a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_14,color_FFFFFF,t_70,g_se,x_16)
Python数据分析
利用py的seaborn和pandas来绘制热图
import pandas as pd
import seaborn as sns
import numpy as np
data=pd.read_csv("D:\清风数模\SELF\相关分析\第5讲.相关系数\代码和例题数据\八年级男生体测数据.CSV",encoding="utf-8")
data_corr=data.corr('pearson')
data_corr
| height | weight | lung_capacity | 50m_run | standing_jump | sit_and_reach | |
|---|---|---|---|---|---|---|
| height | 1.000000 | 0.057989 | 0.099877 | 0.008939 | -0.022818 | -0.087274 |
| weight | 0.057989 | 1.000000 | 0.033474 | 0.015300 | 0.134597 | 0.083638 |
| lung_capacity | 0.099877 | 0.033474 | 1.000000 | 0.007832 | -0.087716 | -0.005454 |
| 50m_run | 0.008939 | 0.015300 | 0.007832 | 1.000000 | 0.005558 | -0.060121 |
| standing_jump | -0.022818 | 0.134597 | -0.087716 | 0.005558 | 1.000000 | 0.011953 |
| sit_and_reach | -0.087274 | 0.083638 | -0.005454 | -0.060121 | 0.011953 | 1.000000 |
sns.heatmap(data_corr,vmax=0.2,
cmap="RdBu_r",
annot=True,
fmt=".2f",
annot_kws={'size':8,'weight':'normal', 'color':'#253D24'},
mask=np.triu(np.ones_like(data_corr,dtype=np.bool)),#显示对脚线下面部分图
linecolor="grey",
square=True, linewidths=.5,#每个方格外框显示,外框宽度设置
cbar_kws={"shrink": .5},)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Jdefv8S-1642944307273)(D:/typora%E5%9B%BE%E7%89%87/output_5_1.png)]](https://img-blog.csdnimg.cn/529b4fdbc0ba4ccab5b9400cbe831e38.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_8,color_FFFFFF,t_70,g_se,x_16)
R数据分析
先读取数据,简要查看一下
data <- read.csv("D:\\清风数模\\SELF\\相关分析\\第5讲.相关系数\\代码和例题数据\\八年级男生体测数据.CSV")
head(data)
通过summary()函数计算描述性统计量
summary()函数提供了最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计。
summary_data <- summary(data)
summary_data
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GHwQzelx-1642944307274)(D:/typora%E5%9B%BE%E7%89%87/image-20220123090634206.png)]](https://img-blog.csdnimg.cn/096a6ad6b6b1458eb3b4b599a2adee51.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
通过Hmisc包中的describe()函数计算描述性统计量
library(Hmisc)
hmisc_des <- describe(data)
hmisc_des
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KdNE9PCW-1642944307275)(D:/typora%E5%9B%BE%E7%89%87/image-20220123091348241.png)]](https://img-blog.csdnimg.cn/8f47f46ae5bb40d39c63a8085306b83f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
pastecs包中的stat.desc()函数计算描述性统计量
library(pastecs)
stat.desc(data)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C0zCsLpy-1642944307275)(D:/typora%E5%9B%BE%E7%89%87/image-20220123092002472.png)]](https://img-blog.csdnimg.cn/81aeca75e43f4c98a9280ba24935ce93.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_19,color_FFFFFF,t_70,g_se,x_16)
进行相关分析
Pearson积差相关系数衡量了两个定量变量之间的线性相关程度。Spearman等级相关系数则衡量分级定序变量之间的相关程度。Kendall’s Tau相关系数也是一种非参数的等级相关度量。
# 方差
var(data)
# 协方差
cov(data)
# Pearson
cor(data)
# Spearman
cor(data,method="spearman")
# Kendall's Tau
cor(data,method="kendall")
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8DCGCSmP-1642944307276)(D:/typora%E5%9B%BE%E7%89%87/image-20220123094012902.png)]](https://img-blog.csdnimg.cn/3edd45ecb2094e06a1c769efcb793865.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nngIPKqJ-1642944307276)(D:/typora%E5%9B%BE%E7%89%87/image-20220123094036049.png)]](https://img-blog.csdnimg.cn/dc31b1b574be4c78b4976992f269d944.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
绘制带有回归线的散点图矩阵
mypanefun = function(x,y){
points(x,y)#绘制出散点
#绘制一个回归线,y对x回归线
# y = kx
# 线性回归算法
abline(lm(y~x),col='purple')#绘制直线
}
pairs(data,panel = mypanefun)#panel接收一个函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qnV64vTZ-1642944307277)(D:/typora%E5%9B%BE%E7%89%87/%E5%B8%A6%E5%9B%9E%E5%BD%92%E7%BA%BF%E7%9A%84%E7%9F%A9%E9%98%B5%E6%95%A3%E7%82%B9%E5%9B%BE.jpeg)]](https://img-blog.csdnimg.cn/99af8f08d8a748b5a2420779f067aed8.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_16,color_FFFFFF,t_70,g_se,x_16)
画相关图
cor_data <- cor(data)
library(corrgram)
corrgram(cor_data,order=TRUE,lower.panel = panel.shade,upper.panel = panel.pie
,text.panel = panel.txt,main="Corrgram of boys' exercise test")
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p0HkHLOB-1642944307278)(D:/typora%E5%9B%BE%E7%89%87/Corrgram%20of%20boys%27%20exercise%20test.jpeg)]](https://img-blog.csdnimg.cn/cec985fd5eae4605b174d1b12eae2aff.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_16,color_FFFFFF,t_70,g_se,x_16)
library(pheatmap)
pheatmap(cor_data,cluster_row = FALSE, cluster_col = FALSE,display_numbers = TRUE)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8lr4mLuc-1642944307279)(D:/typora%E5%9B%BE%E7%89%87/pheatmap.jpeg)]](https://img-blog.csdnimg.cn/61cdc5aad66c4065b9308dc9835c1278.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_16,color_FFFFFF,t_70,g_se,x_16)
假设检验
第一步
提出原假设 H 0 H_0 H0和备择假设 H 1 H_1 H1,假设我们计算出来一个pearson相关系数r,我们项检验它是否显著的异于0,那么我们可以这样设定原假设和备择假设: H 0 : r = 0 , H 1 : ≠ 0 H_0:r=0,H_1:\not=0 H0:r=0,H1:=0
第二步
在原假设成立的条件下,利用我们要检验的量构造出一个符合某一分布的统计量。
warning:
- 统计量相当于我们要检验的量的一个函数,里面不能有其他的随机变量
- 这里的分布一般有四种:标准正态、t、 χ 2 \chi^2 χ2和F
对于pearson相关系数r而言,在满足一定条件下,我们可以构造统计量: t = r n − 2 1 − r 2 t=r\sqrt{\frac{n-2}{1-r^2}} t=r1−r2n−2,可以证明t是服从自由度为n-2的 t-distribution
第三步
将我们要检验的这个值带入这个统计量中,可以得到一个特定的值(检验值)。
假设我们现在计算出来的祥光系数为0.5,样本为30,那么我们可以得到 t ∗ = 0.5 30 − 2 1 − 0. 5 2 = 3.05505 t^*=0.5\sqrt{\frac{30-2}{1-0.5^2}}=3.05505 t∗=0.51−0.5230−2=3.05505
第四步
由于我们知道统计量的分布情况,因此我们可以画出该分布的概率密度函数pdf,并给定一个置信水平,根据这个置信水平找到临界值,并画出检验统计量的接受域和拒绝域。常见的置信水平有三个:90%,95%,99%,其中95%是三者中最为常用。
第五步
看我们计算出来的检验值是落在了拒绝域还是接受域,并下结论。
更好用的方法:p值检验法
前面用的SPSS方法就是p-value检验法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d8ZvkuJU-1642944307280)(D:/typora%E5%9B%BE%E7%89%87/image-20220123121906966.png)]](https://img-blog.csdnimg.cn/a56dd5b1a3074869a62d42ad3e04eac7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_14,color_FFFFFF,t_70,g_se,x_16)
Pearson correlation coefficient 假设检验的条件
- **实验数据通常假设是成对的来自于正态分布的总体。**因为我们在求Pearson correlation coefficient以后,通常还会用t检验之类的方法来进行Pearson correlation coefficitent 检验,而t检验是基于数据呈正态分布的假设的。
- **实验数据之间的差距不能太大。**Pearson correlation coefficient 受异常值的影响比较大。
- **每组样本之间是独立抽样的。**构造t统计量时需要用到。
检验数据是否是正态分布
JB检验(大样本 n>30)
雅克‐贝拉检验(Jarque‐Bera test)
对于一个随机变量
{
X
i
}
\left\{X_{i}\right\}
{Xi}, 假设其偏度为
S
S
S, 峰度为
K
K
K, 那么我们可以构造
J
B
J B
JB 统计量:
J
B
=
n
6
[
S
2
+
(
K
−
3
)
2
4
]
J B=\frac{n}{6}\left[S^{2}+\frac{(K-3)^{2}}{4}\right]
JB=6n[S2+4(K−3)2]
可以证明, 如果
{
X
i
}
\left\{X_{i}\right\}
{Xi} 是正态分布, 那么在大样本情况下
J
B
∼
χ
2
(
2
)
J B \sim \chi^{2}(2)
JB∼χ2(2) (自由度为 2 的卡方分布)
注: 正态分布的偏度为 0 , 峰度为 3
那么进行假设检验的步骤如下:
H
0
H_{0}
H0 :该随机变量服从正态分布
H
1
H_{1}
H1 : 该随机变量不服从正态分布
然后计算该变量的偏度和峰度, 得到检验值
J
B
∗
J B^{*}
JB∗, 并计算出其对应的
p
p
p 值
将
p
p
p 值与
0.05
0.05
0.05 比较, 如果小于
0.05
0.05
0.05 则可拒绝原假设, 否则我们不能拒绝原假设。
偏度和峰度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NqLahuVn-1642944307280)(D:/typora%E5%9B%BE%E7%89%87/image-20220123175418040.png)]](https://img-blog.csdnimg.cn/9724b0055e4747b0ad36083ec3b2f336.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_19,color_FFFFFF,t_70,g_se,x_16)
Matlab实现
matlab中进行JB检验的语法:[h,p] = jbtest(x,alpha)
当输出h等于1是,表示拒绝原假设;h等于0则表示接受原假设。alpha就是显著性水平,一般取0.05,此时置信水平为1-0.05=0.95
x就是我们要检验的随机变量,注意这里的x只能是向量。
% jb-test
% 检验第一列数据是否为正态分布
[h,p]=jbtest(man(:,1),0.05)
% 用循环检验所有列的数据
n_c=size(man,2)
% column
H=zeros(1,n_c);
P=zeros(1,n_c);
for i=1:n_c
[h,p]=jbtest(man(:,i),0.05);
H(i)=h;
P(i)=p;
end
disp(H)
disp(P)
H_P=[H;P];
disp(H_P)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MDBDtGv2-1642944307281)(D:/typora%E5%9B%BE%E7%89%87/image-20220123184018641.png)]](https://img-blog.csdnimg.cn/44229adebd8d4e1e8c891894300498ed.png)
由上图可知,这六个指标都是拒绝原假设的,也就是都不服从正态分布。
Shapiro-wilk检验(小样本[3,50])
Shapiro‐wilk夏皮洛‐威尔克检验
H 0 : H_0: H0:该随机变量服从正态分布
H 1 : H_1: H1:该随机变量不服从正态分布
将p值与0.05比较,如果小于0.05则可拒绝原假设,否则我们不能拒绝原假设。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tUpsqXdz-1642944307282)(D:/typora%E5%9B%BE%E7%89%87/image-20220123184705654.png)]](https://img-blog.csdnimg.cn/d7222c0383704a6f8225b190cfcb4a16.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_12,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oRHT3uJy-1642944307282)(D:/typora%E5%9B%BE%E7%89%87/image-20220123202752701.png)]](https://img-blog.csdnimg.cn/9f93fdf2f9ce4bcda4932efbed724f9f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_12,color_FFFFFF,t_70,g_se,x_16)
Q-Q图
(要求数据量非常大,一般不用)
在统计学中,Q‐Q图(Q代表分位数Quantile)是一种通过比较两个概率分布的分位数对这两个概率分布进行比较的概率图方法。
首先选定分位数的对应概率区间集合,在此概率区间上,点(x,y)对应于第一个分布的一个分位数x和第二个分布在和x相同概率区间上相同的分位数。
这里,我们选择正态分布和要检验的随机变量,并对其做出QQ图,可想而知,如果要检验的随机变量是正态分布,那么QQ图就是一条直线。
matlab
qqplot(man(:,1))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ama2CgRb-1642944307283)(D:/typora%E5%9B%BE%E7%89%87/qqplot.png)]](https://img-blog.csdnimg.cn/62233c8b67f24234abff7c4465479308.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_13,color_FFFFFF,t_70,g_se,x_16)
SPSS
在进行Shapiro-wilk检验时就有qqplot
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eEypizR3-1642944307285)(D:/typora%E5%9B%BE%E7%89%87/image-20220123203308880.png)]](https://img-blog.csdnimg.cn/dcf072e9c2784905b5109b296bc5c276.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
斯皮尔曼spearman相关系数
定义:
X
X
X 和
Y
Y
Y 为两组数据, 其斯皮尔曼 (等级) 相关系数:
r
s
=
1
−
6
∑
i
=
1
n
d
i
2
n
(
n
2
−
1
)
r_{s}=1-\frac{6 \sum_{i=1}^{n} d_{i}^{2}}{n\left(n^{2}-1\right)}
rs=1−n(n2−1)6∑i=1ndi2
其中,
d
i
d_{i}
di 为
X
i
X_{i}
Xi 和
Y
i
Y_{i}
Yi 之间的等级差。
(一个数的等级, 就是将它所在的一列数按照从小到大排序后, 这个数所在的位置)
可以证明:
r
s
r_{s}
rs 位于
−
1
-1
−1 和 1 之间。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mLfSNM3U-1642944307286)(D:/typora%E5%9B%BE%E7%89%87/image-20220123210130881.png)]](https://img-blog.csdnimg.cn/767d01d9775945e9837b640218d9c03f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_15,color_FFFFFF,t_70,g_se,x_16)
注:如果有的数值相同,则将它们所在的位置取算术平均。
根据公式:
r
s
=
1
−
6
∑
i
=
1
n
d
i
2
n
(
n
2
−
1
)
可得:
X
和
Y
的斯皮尔曼相关系数
r
s
=
1
−
6
×
(
1
+
0.25
+
0.25
+
1
)
5
×
24
=
0.875
\begin{aligned} \text { 根据公式: } r_{s} &=1-\frac{6 \sum_{i=1}^{n} d_{i}^{2}}{n\left(n^{2}-1\right)} \text { 可得: } \\ X \text { 和 } Y \text { 的斯皮尔曼相关系数 } r_{s} &=1-\frac{6 \times(1+0.25+0.25+1)}{5 \times 24}=0.875 \end{aligned}
根据公式: rsX 和 Y 的斯皮尔曼相关系数 rs=1−n(n2−1)6∑i=1ndi2 可得: =1−5×246×(1+0.25+0.25+1)=0.875
另一种spearman correlation coefficient 的定义:等级之间的pearson correlation coefficient
matlab
[R,P]=corr(man,'type','Spearman')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7OppkiDD-1642944307286)(D:/typora%E5%9B%BE%E7%89%87/image-20220123211029689.png)]](https://img-blog.csdnimg.cn/95d9932048cc4b7fb1654254c3db0b08.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_18,color_FFFFFF,t_70,g_se,x_16)
SPSS
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UV1P57eT-1642944307287)(D:/typora%E5%9B%BE%E7%89%87/image-20220123211216630.png)]](https://img-blog.csdnimg.cn/d15f83144fda4b4e993451147e703938.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBARHJlYW0gb2YgR3Jhc3M=,size_12,color_FFFFFF,t_70,g_se,x_16)

两种相关系数的比较
- 连续数据、正态分布、线性关系,用pearson相关系数时最恰当的,当然用spearman相关系数也可以,就是效率没有pearson相关系数高。
- 上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
- 两个定序数据之间也用spearman相关系数,不能用pearson相关系数。
- 定序数据是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。
- 例如:优、良、差;
- 我们可以用1表示差、2表示良、3表示优,但请注意,用2除以1得出的2并不代表任何含义。定序数据最重要的意义是代表了一组数据中的某种逻辑顺序。
Spearman相关系数的适用条件比Pearson相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用














 3133
3133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









