









简介
torch.optim.lr_scheduler :提供了一些方法可以基于epochs的值来调整学习率。
torch.optim.lr_scheduler.ReduceLROnPlateau :则提供了基于训练中某些测量值使学习率动态下降的方法。
注意:学习率调整应该在优化器的更新之后,例如:
scheduler = ...
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
警告:在PyTorch 1.1.0之前,学习率调整程序应在优化程序更新之前调用。也就是如果你在optimizer.step()这句代码之前使用scheduler.step(),会跳过学习率的第一个值。
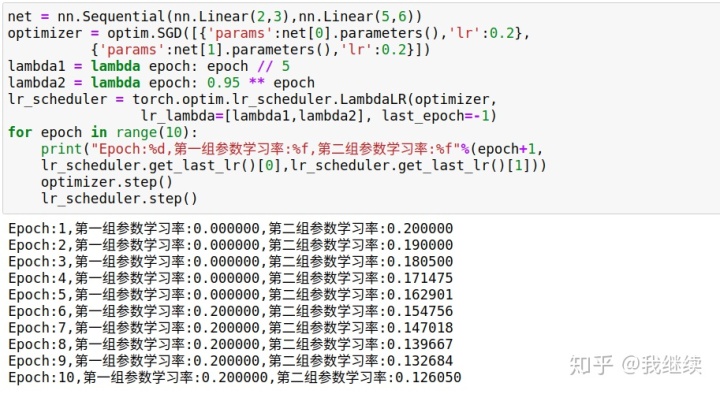
一、用lamda函数作为学习率的乘积因子更新学习率
torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda,last_epoch=-1,verbose=False)
将每个参数组的学习率设置为:初始化学习率
lambda函数。当last_epoch = -1时,将初始学习率设置为lr。
optimizer:优化器
lr_lambda:函数或者函数列表,用来计算乘积因子,通常epoch为函数参数。当为函数列表的时候可以为optimizer.param_groups中的每个参数组设置学习率。
last_epoch:默认为-1,一般不用管
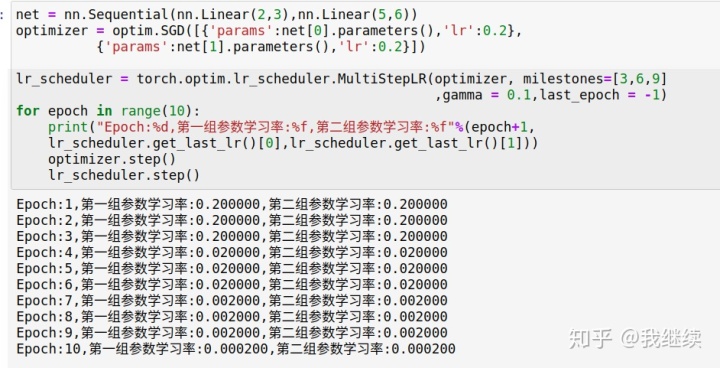
二、用列表的元素控制衰退时机
torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones,gamma=0.1,last_epoch=-1,verbose=False)
一旦训练过程中epoch的数目达到milestones中的数值后,每一组参数的学习率会乘以gamma进行一次衰减。
milestones:列表的每个元素表示训练到这个epoch的时候学习率会衰减一次。
gamma:衰减因子
注意:一定要用get_last_lr(),而不是以前的get_lr(),不然打印的输出信息会有点小问题,这里有个坑小心。
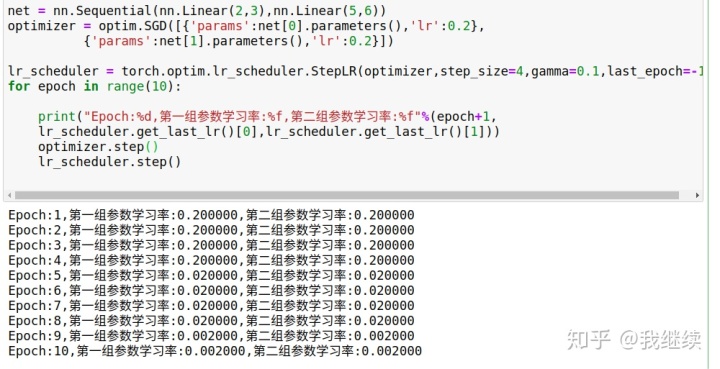
三、固定步长的学习率衰减
torch.optim.lr_scheduler.StepLR(optimizer,step_size,gamma=0.1,last_epoch=-1,verbose=False)
每训练step_size个epochs,每组参数就会衰减一次学习率。
step_size:决定学习率衰减的时期
gamma:衰减因子
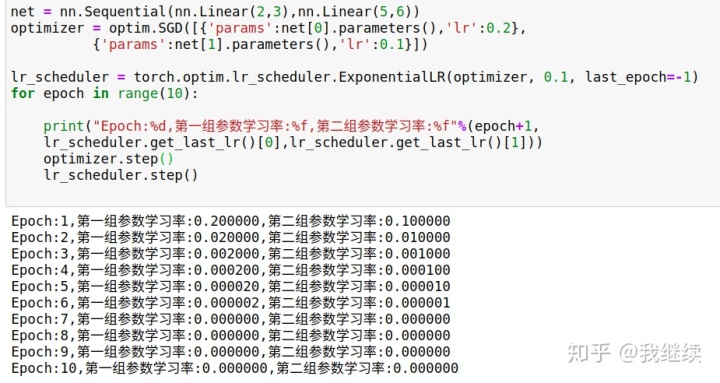
四、每训练一个epoch,学习率衰减一次
torch.optim.lr_scheduler.ExponentialLR(optimizer,gamma,last_epoch=-1,verbose=False)
五、余弦退火调整学习率
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max,eta_min=0,last_epoch=-1,verbose=False)
学习率调整公式:
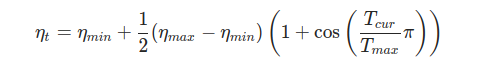
右边的函数周期为
,在
个epoch后降到最低学习率
,然后学习率在接下来
个epoch后上升到
:初始的学习率
:迭代过程中最小的学习率
:当前的epoch的数目
:lr的变化是周期性的,T_max是周期的一半。
举例子:比如
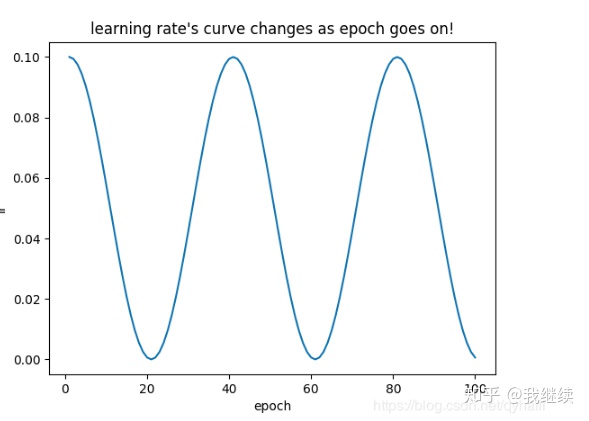
,初始学习率为0.1,最小学习率为0,如下图:
六、根据训练中某些度量值(指标)动态的调节学习率
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.1,patience=10,threshold=0.0001,threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08,verbose=False)
当某一项指标停止往好的趋势变化的时候,通过调整学习率可以使模型受益。例如验证集的loss不再下降或者accuracy不再上升时,进行学习率调整。
mode(str):有min和max两种模式。min模式表示指标不再降低的时候降低学习率,max模式表示指标不再上升的时候降低学习率。
factor(float):学习率调整的倍数,new_lr = lr * factor.
patience(int):所能忍耐的多少个epoch迭代,指标却不改善。比如为2时,表示可以最大程度接受连续两个epoch没有改善指标,当第三个epoch仍然没有改善的时候,马上降低学习率。
threshhold_mode(str):有rel和abs两种模式
threshhold(float):
上面这两个参数我没弄懂,如果有懂得给我留个言,哈哈
min_lr(float or list):学习率的下限,如果有多个参数组的话,需要为每一个参数组设置,可以为一个列表。
eps(float):学习率衰减的最小值,当学习率变化小于eps,则不调整学习率。
注意:使用的时候要选择网络的度量指标,比如要用scheduler.step(train_loss)这种代码,表明监控哪一种指标。















 2062
2062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









