










前言
在训练网络的时候,常常会出现loss出现非常明显的剧烈抖动情况,虽然大多数情况可以继续训练下去,但是实际上还是预示着问题存在。而且,有不同维度的问题,这也需要不同的解决方法,但是具体究竟是哪一种,还得具体情况具体分析。
我发现学习率对模型的训练影响挺大的 可以说是最大的影响因素了 太大会把Loss搞大一直卡在一个局部最优,反而是从小一点开始比较好。最理想的情况是从一个学习率开始 当它进入到一定的EPCHO没有提高精度的时候让学习率下降。
还有预处理数据也很重要:数据的好坏严重影响了训练的精度:用随机森林和PCA降维选重要特征后再把数据放进去,消除一些噪声。提高精度。
在数据量不多,比如只有2000行数据,只用XGBOOST等机器学习的方法做一个集成学习效果会比深度学习好。
无过拟合
是否找到合适的loss函数:在深度学习里面,不同的loss针对的任务是有不同的,有些loss函数比较通用例如L1/L2等,而如perceptual loss则比较适合在图像恢复/生成领域的任务上。当loss出现问题的适合,想一想,是不是loss设置的有问题,别人在此领域的任务的方法是否也使用和你一样的loss。
batch size是否合适:batch size的问题一般是较大会有比较好的效果,一是更快收敛,二是可以躲过一些局部最优点。但是也不是一味地增加batch size就好,太大的batch size 容易陷入sharp minima,泛化性不好。较小的batch size,类别较多时,可能会使得网络有明显的震荡。batch size增大,处理相同的数据量速度加快;随着batch size增大,达到相同精度的epoch数量变多;因此基于上述两种情况,batch size要调试到合适的数值;过大的batchsize会让网络收敛到不好的局部最优点;过小的batchsize训练速度慢,训练不收敛;具体的batch size需要根据训练集数据内容和数量进行调试。
是否使用合适的函数:一般来说,都几乎使用RELU作为全局函数,尽可能少的使用sigmoid**函数(**范围太小),容易造成梯度弥散、消失
学习率:学习率太大,一步前进的路程太长,会出现来回震荡的情况,但是学习率太小,收敛速度会比较慢。在自己训练新网络时,可以从0.1开始尝试,如果loss不下降的意思,那就降低,除以10,用0.01尝试,一般来说0.01会收敛,不行的话就用0.001. 学习率设置过大,很容易震荡。不过刚刚开始不建议把学习率设置过小,尤其是在训练的开始阶段。在开始阶段我们不能把学习率设置的太低否则loss不会收敛。我的做法是逐渐尝试,从0.1,0.08,0.06,0.05 …逐渐减小直到正常为止,有的时候学习率太低走不出低估,把冲量提高也是一种方法,适当提高mini-batch值,使其波动不大。
是否选择合适的优化算法:一般来说,我都使用Adam作为优化器(默认参数)。如果经过仔细调整的SGD算法性能可能更好,但是时间上不太允许这样做。
检查输入数据格式等信息是否正确:数据输入不对包括数据的格式不是网络模型指定的格式,导致训练的时候网络学习的数据不是想要的; 此时会出现loss曲线震荡;解决办法:检查数据输入格式,数据输入的路径;
数据和标签:数据分类标注是否准确?数据是否干净?数据库太小一般不会带来不收敛的问题,只要你一直在train总会收敛(跑飞了不算)。反而不收敛一般是由于样本的信息量太大导致网络不足以fit住整个样本空间。样本少只可能带来过拟合的问题。
网络设定不合理:如果做很复杂的分类任务,却只用了很浅的网络,可能会导致训练难以收敛,换网络换网络换网络,重要的事情说三遍,或者也可以尝试加深当前网络。
过拟合
**通过提前终止确定最优模型:**在训练的过程中,可能会出现训练到最后的精度竟然还不如前面的epoch高,那么可以直接终止训练,然后将之前的model作为best model,之后使用这个model即可
Regularization(正则化):通过正则化进行约束,一般的方法可以通过优化器的权重衰减方法,即训练到后期,通过衰减因子使权重的梯度下降越来越缓慢。或者BN、Dropout以及L1/L2
调整网络结构:一句话,你的网络结构出了问题,是错误的,没有科学性的
增加训练数据量:数据集太小太少,且没有进行数据增强,就可能导致过拟合
loss变nan
现象:loss进行一次反传后,loss变nan;
排查顺序:
训练数据(包括label)中有无异常值(nan, inf等);
网络中有无除法,确保分母不会出现0, 分母可以加一个eps=1e-8;
网络中有无开根号(torch.sqrt), 保证根号下>=0, 我的程序即是由此引起的(未保证不出现0或者极小正值的情况),解决也是加一个eps=1e-8.
1.如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习率直至不出现NaN为止,一般来说低于现有学习率1-10倍即可。
2.如果当前的网络是类似于RNN的循环神经网络的话,出现NaN可能是因为梯度爆炸的原因,一个有效的方式是增加“gradient clipping”(梯度截断来解决)
3.可能用0作为了除数;
4.可能0或者负数作为自然对数
5.需要计算loss的数组越界(尤其是自己,自定义了一个新的网络,可能出现这种情况)
6.在某些涉及指数计算,可能最后算得值为INF(无穷)(比如不做其他处理的softmax中分子分母需要计算exp(x),值过大,最后可能为INF/INF,得到NaN,此时你要确认你使用的softmax中在计算exp(x)做了相关处理(比如减去最大值等等))
7、对于层数较多的情况,各层都做batch_nomorlization;
8、对设置Weights权重使用tf.truncated_normal(0, 0.01, [3,3,1,64])生成,同时值的均值为0,方差要小一些;
9、激活函数可以使用tanh;
10、减小学习率lr。很不幸,我就碰到了这种情况,而且这种情况很玄学。直接上图吧:

可以看到LOSS抖动得很明显,再看MAP(测试集VALIDATION DATASETS平均准确率)
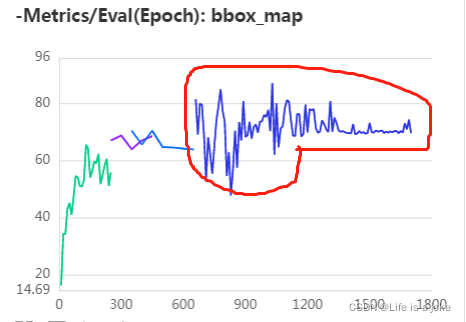
同样处于抖动的状态,但是后面一段的抖动明显减小了,原因是因为我设置了学习率在此处按比例递减,能够达到收敛。但是这又说明一个问题:想要得到更好的MAP是需要更大的学习率的,但是模型就无法收敛,二者相互矛盾。

典型实例
①梯度爆炸
原因:梯度变得非常大,使得学习过程难以继续
现象:观察log,注意每一轮迭代后的loss。loss随着每轮迭代越来越大,最终超过了浮点型表示的范围,就变成了NaN。
措施:
1、数据归一化(减均值,除方差,或者加入normalization,例如BN、L2 norm等);
2、更换参数初始化方法(对于CNN,一般用xavier或者msra的初始化方法);
3、减小学习率、减小batch size;
4、加入gradient clipping;
5、减小solver.prototxt中的base_lr,
至少减小一个数量级。如果有多个loss layer,需要找出哪个损失层导致了梯度爆炸,并在train_val.prototxt中减小该层的loss_weight,而非是减小通用的base_lr。
6、设置clip gradient,
用于限制过大的diff
7、弱化场景,将你的样本简化,各个学习率等参数采用典型配置,比如10万样本都是同一张复制的,让这个网络去拟合,如果有问题,则是网络的问题。否则则是各个参数的问题。
8、如果是网络的问题,则通过不断加大样本的复杂度和调整网络(调整拟合能力)来改变。
9、参数的微调,我个人感觉是在网络的拟合能力和样本的复杂度匹配的情况下,就是可以train到一定水平,然后想进行进一步优化的时候采用。
10、参数的微调,楼上说得几个也算是一种思路吧,其他的靠自己去积累,另外将weights可视化也是一个细调起来可以用的方法,现在digits tf里面都有相关的工具.
②不当的损失函数
原因:有时候损失层中loss的计算可能导致NaN的出现。比如,给InfogainLoss层(信息熵损失)输入没有归一化的值,使用带有bug的自定义损失层等等。
现象:观测训练产生的log时一开始并不能看到异常,loss也在逐步的降低,但突然之间NaN就出现了。
措施:看看你是否能重现这个错误,在loss layer中加入一些输出以进行调试。
③不当的输入
原因:
training sample中出现了脏数据!
脏数据的出现导致我的logits计算出了0,0传给
即nan。
所以我通过设置batch_size = 1,shuffle = False,一步一步地将sample定位到了所有可能的脏数据,删掉。期间,删了好几个还依然会loss断崖为nan,不甘心,一直定位一直删。终于tm work out!
之所以会这样,是因为我的实验是实际业务上的真实数据,有实际经验的就知道的,现实的数据非常之脏,基本上数据预处理占据我80%的精力。
现象:每当学习的过程中碰到这个错误的输入,就会变成NaN。观察log的时候也许不能察觉任何异常,loss逐步的降低,但突然间就变成NaN了。
措施:重整你的数据集,确保训练集和验证集里面没有损坏的图片。调试中你可以使用一个简单的网络来读取输入层,有一个缺省的loss,并过一遍所有输入,如果其中有错误的输入,这个缺省的层也会产生NaN。
归纳的涨点方法:
1、warm up策略
2、上文提到的decay_lr学习率下降策略,尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。但是会有爆内存的风险。学习率最好的情况是尽量大幅度震荡,当震荡一定周期后进行decay让其收敛。
3、使用early_stop:经历N轮训练MAP没有得到增长,LOSS对于BEST_MODEL没有下降则停止训练
4、使用数据集增强处理:水平倒置、饱和度、对比度、明亮度、图片放大、打乱数据集的随机切换
MixupImage(
alpha=1.5,
beta=1.5,
mixup_epoch=int(170 * 25. / 27)),
T.RandomDistort(
brightness_range=0.5,
brightness_prob=0.5,
contrast_range=0.5,
contrast_prob=0.5,
saturation_range=0.5,
saturation_prob=0.5,
hue_range=18.0,
hue_prob=0.5),
T.RandomExpand(
prob=0.5,
im_padding_value=[float(int(x * 255)) for x in [0.485, 0.456, 0.406]]),
shuffle=True
5、寻找一个合适的batchsize:越大训练的越快,但是收敛可能需要越多的周期。但是越小则容易把周期拖得更长,进而陷入局部最优。
6、momentum动量因子=0.9,克服局部最优
祝大家都能涨点!














 1744
1744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









