







 本文详细介绍了并查集这一树形数据结构的基本概念、核心算法及其应用实例。并查集支持查询两个元素是否在同一集合及合并两个不相交集合的操作。文章通过力扣题目和POJ题目的解析,展示了并查集在解决实际问题中的应用。
本文详细介绍了并查集这一树形数据结构的基本概念、核心算法及其应用实例。并查集支持查询两个元素是否在同一集合及合并两个不相交集合的操作。文章通过力扣题目和POJ题目的解析,展示了并查集在解决实际问题中的应用。
文章目录
介绍
并查集是一个树形的数据结构,有两种操作:
- 查询:判断两个元素是否在同一集合
- 合并:把两个不相交集合合并成一个集合
算法
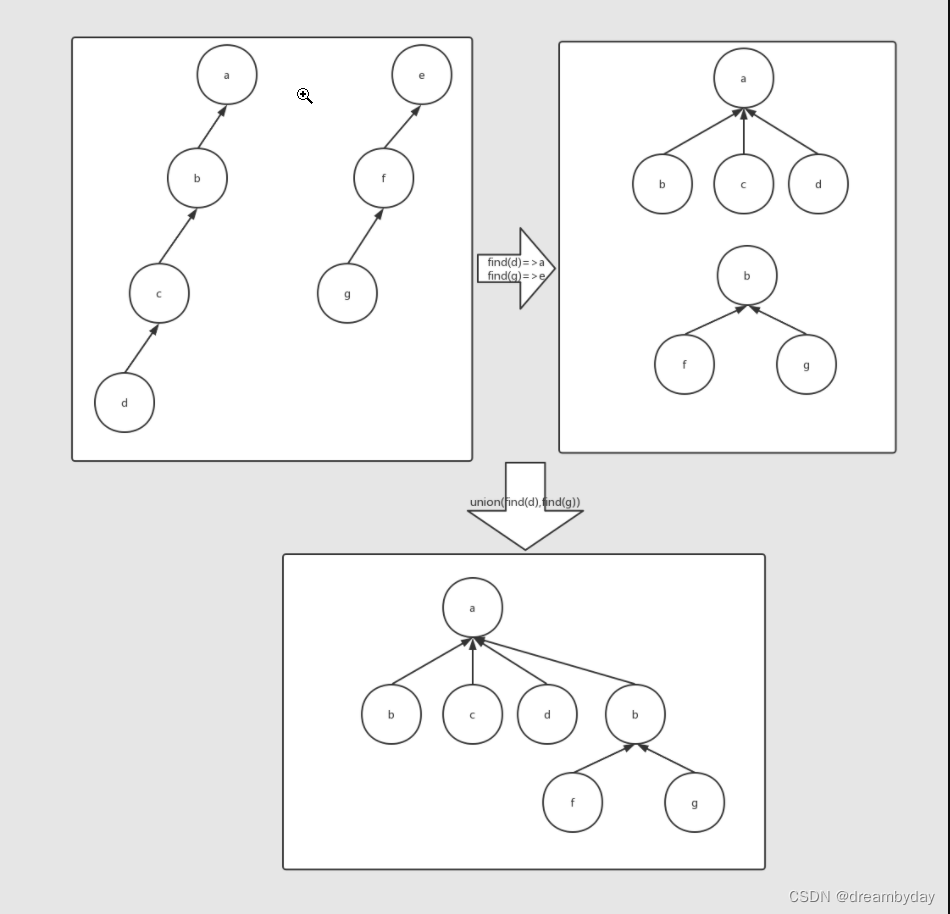
如图,发现结点d和g属于同一集合,要进行合并。则
- 查询+路径压缩(find方法):从d和g开始向上寻找根节点,并将路径上所有结点直接指向根节点。生成了右上图的树。
- 按秩合并(union方法):将两个集合合并为一个集合,因此要将结点数小的集合的根节点的父节点设置为另一个集合的根节点,并更新集合大小,完成集合合并。
两种操作的时间复杂度都为O(h),h为树高。空间复杂度为O(n),n为节点数。
模板
public class UnionSet684 {
class Node {
int size; // 集合结点数量
int par; // 集合根节点
public Node(int par){
this.par =par;
this.size = 1;
}
}
Node[] nodes;
/**
* 路径压缩
* @param index 查找下标
* @return 集合根节点
*/
private int find(int index) {
// 当前节点为根则返回根
if (nodes[index].par == index) {
return index;
}
// 递归,将当结点到根节点路径上所有的结点直接连到根节点
nodes[index].par = find(nodes[index].par);
// 返回集合根节点
return nodes[index].par;
}
/**
* 按秩合并xy下标结点
* @return 合并是否成功(如果已经在一棵树里则合并失败)
*/
private boolean union(int x,int y) {
int px = find(x);
int py = find(y);
if (px == py) {
return false;
}
// 集合小的合并到集合大的跟下
if (nodes[px].size < nodes[py].size) {
nodes[px].par = nodes[py].par;
nodes[py].size +=nodes[px].size;
} else {
nodes[py].par = nodes[px].par;
nodes[px].size +=nodes[py].size;
}
return true;
}
private void init(int[][] edges) {
nodes = new Node[edges.length];
for (int i = 0; i < edges.length; i++) {
nodes[i] = new Node(i);
}
}
public int[] findRedundantConnection(int[][] edges) {
init(edges);
for(int i = 0; i < edges.length; i++) {
if (!union(edges[i][0]-1,edges[i][1]-1)) {
return edges[i];
}
}
return null;
}
}
例题
力扣684 冗余连接 判断环
力扣1254 统计封闭岛屿数量
POJ2492 a bug’s life并查集扩展
17年做的题,这里作为例题
题的解答方法跟食物链差不多,可以看看食物链的解析再看这个。
食物链 http://blog.csdn.net/dreambyday/article/details/65447189
rela[x]=0表示同性
rela[x]=1表示异性
#include<iostream>
#include<stdio.h>
#include<iomanip>
#include<string.h>
#include<algorithm>
#include<time.h>
#include<cmath>
using namespace std;
#define mem(arr,a) memset(arr,a,sizeof(arr))
#define power(a) (a*a)
#define N 50010
int par[N];
int rela[N];
void init(int n){
for (int i = 1; i <= n; i++){
par[i] = i;
rela[i] = 0;
}
}
int find(int x){
if (x == par[x])return x;
int t = par[x];
par[x] = find(par[x]);
rela[x] = (rela[x] + rela[t]) % 2;
return par[x];
}
void unite(int r1, int r2, int b, int c){
par[r1] = r2;
rela[r1] = (rela[b] +1+rela[c] + 2) % 2;
}
int t, n, m;
int main(){
cin >> t;
int cnt = 1;
while (t--){
cin >> n >> m;
init(n);
bool flag = false;
while (m--){
int a, b;
scanf("%d%d", &a, &b);
int r1 = find(a);
int r2 = find(b);
if (r1 != r2){
unite(r1, r2, a, b);
}
else{
if (rela[a] == rela[b]){
flag = true;
}
}
}
if (flag){
printf("Scenario #%d:\nSuspicious bugs found!\n", cnt++);
}
else
printf("Scenario #%d:\nNo suspicious bugs found!\n", cnt++);
printf("\n");
}
}

















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









