










好的,我来填坑了
首先介绍一下问题背景:由于客户的label是一张图片上的各个要素在对应的一个txt文件上,所以要解析txt文件得到各个要素的csv文件,但是在解析的时候发现,以utf8格式读txt文件会遇到编码错误问题,以gbk也会遇到,错误类似于UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 4040: illegal multibyte sequence,只是不同的txt文件出问题,所以发现了这些txt文件有的是以gbk编码的,有的是以utf8编码的,所以就想都转成gbk的,结果又报错,用notepad++查看报错的txt文件,结果发现编码方式为utf8-bom的,在网上查的资料如下:https://blog.csdn.net/qq_21460525/article/details/66971225,简而言之,就是转成gbk的时候,以utf-8-sig这种方式去读,终于折腾了一下不报错了
import codecs
with open("xx.txt",'r','utf-8-sig') as file:
line = file.readlines();
结果在查看要素的csv文件label的时候,发现并没有按照预期得到相应位置的要素,再看相应的txt文件,发现,在linux下打开,有^M符号,在windows下用notepad++查看的时候有换行,(注博主推断都是在windows下做的标注,这个是经过各种推理及查资料得到的结论)
后来发现是因为做标注的有一个人在标注的时候没有按照给的固定的txt格式去标注,而是自己随意加了换行,并且保存的时候并没有按照默认gbk的方式去保存,而是按照utf8保存的,其他人则是严格按照格式做的txt,并没有自己加换行符,并且是按照默认的gbk去保存的。而linux下面的换行符和windows下是不一样的,linux下默认的编码方式是utf8,UTF-8分为两种,一种是不带BOM的,一种是带BOM的。其中第一种不带BOM的是标准形式,第二种带BOM的主要是微软的习惯,因此linux下的utf8在windows下修改完后保存按照utf8的格式的话是带bom的,而windows下默认的编码方式是gbk。

下面第一张图是有问题的,第二张图是正常的(windows的编码方式默认是gbk和linux默认是utf8,所以由于在windows下是utf8保存的(带bom的utf8,^M是因为在windows下的换行符到了linux下的显示),在linux能正常显示,而在windows下是gbk保存的在linux下就会出现乱码)
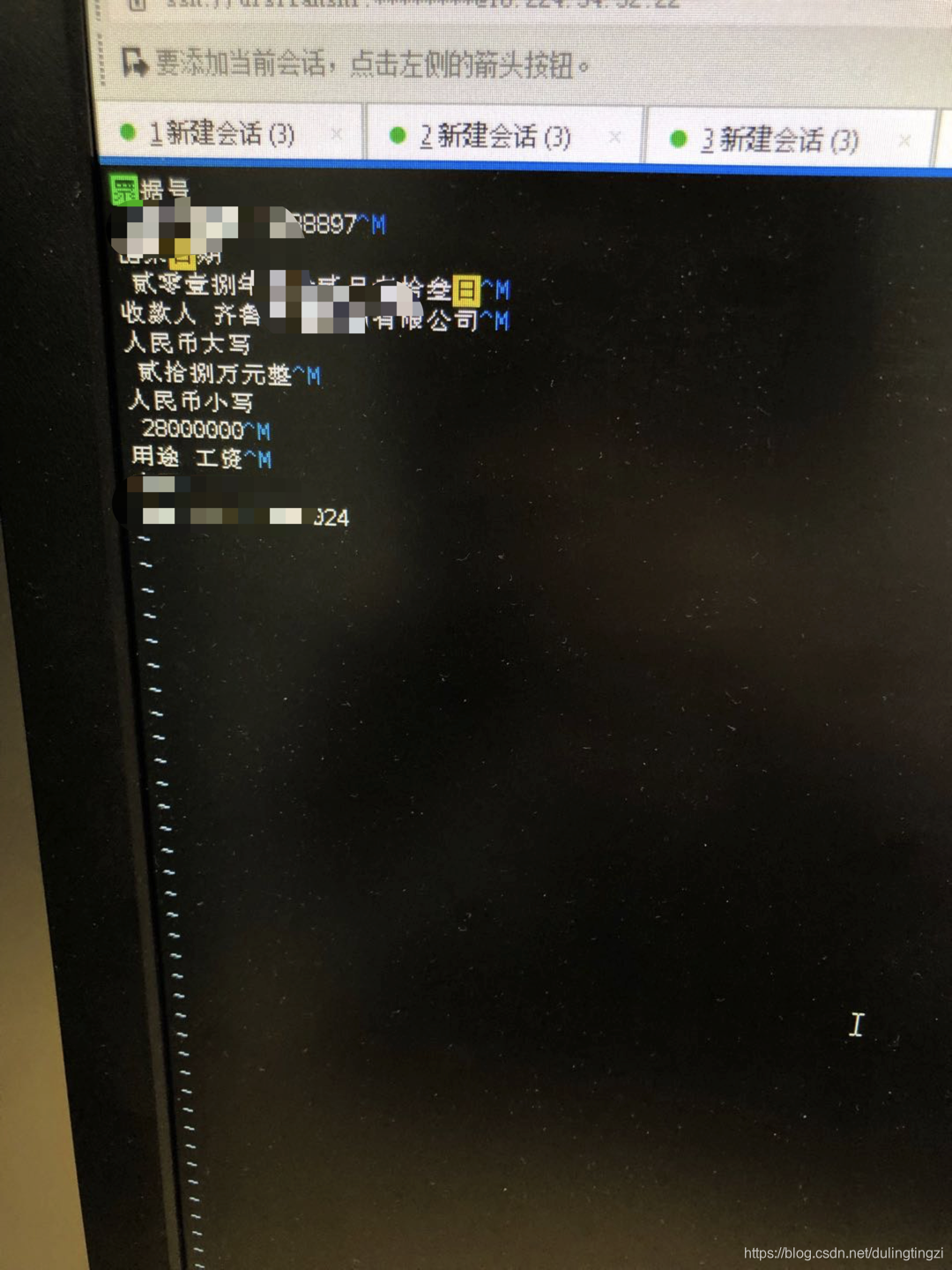
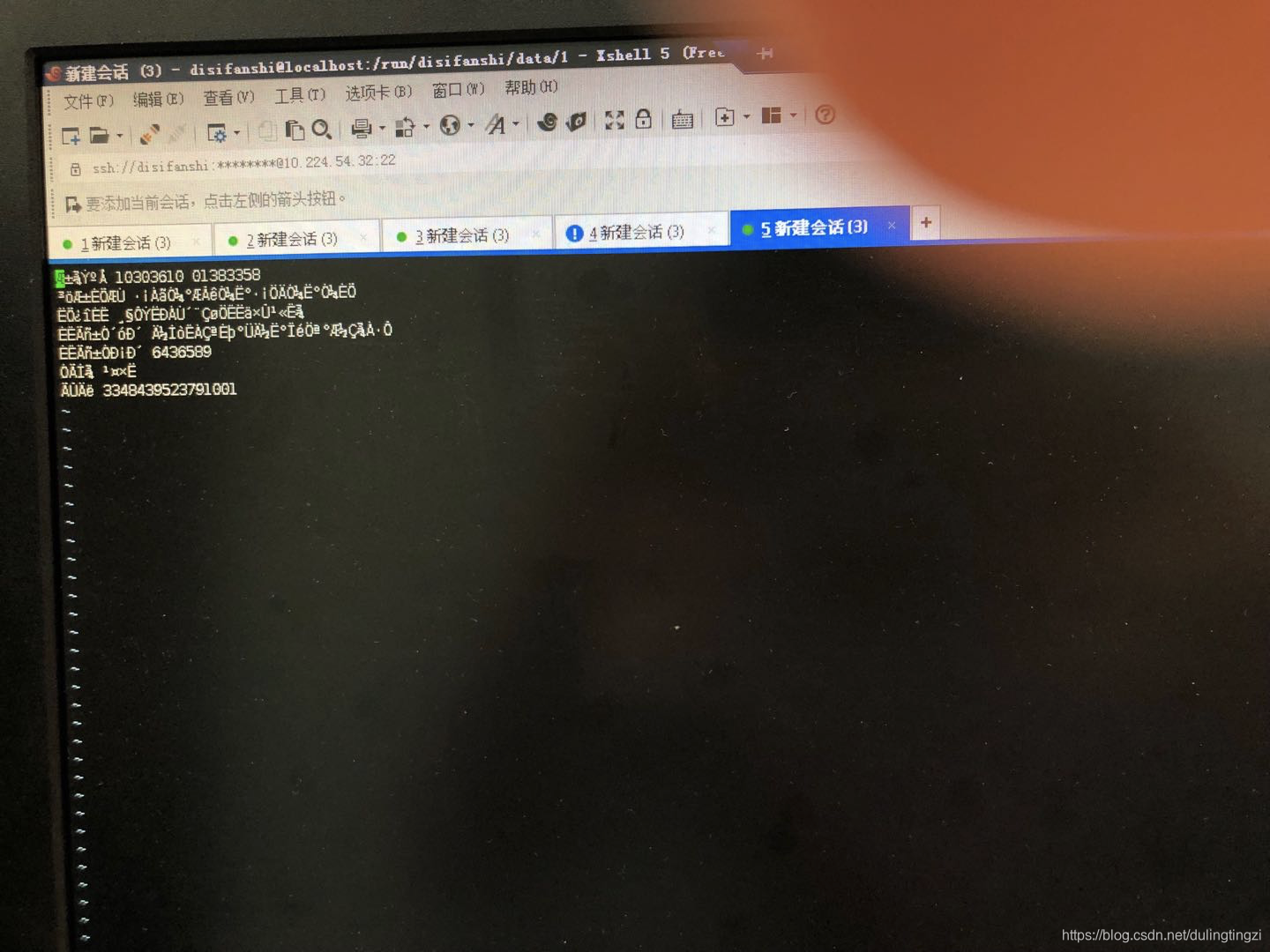
这个 ^M符号在linux下能显示出来,在windows下显示不出来,因为这是windows下的回车换行符号。
最终用下面的代码把有问题的txt筛选出来:
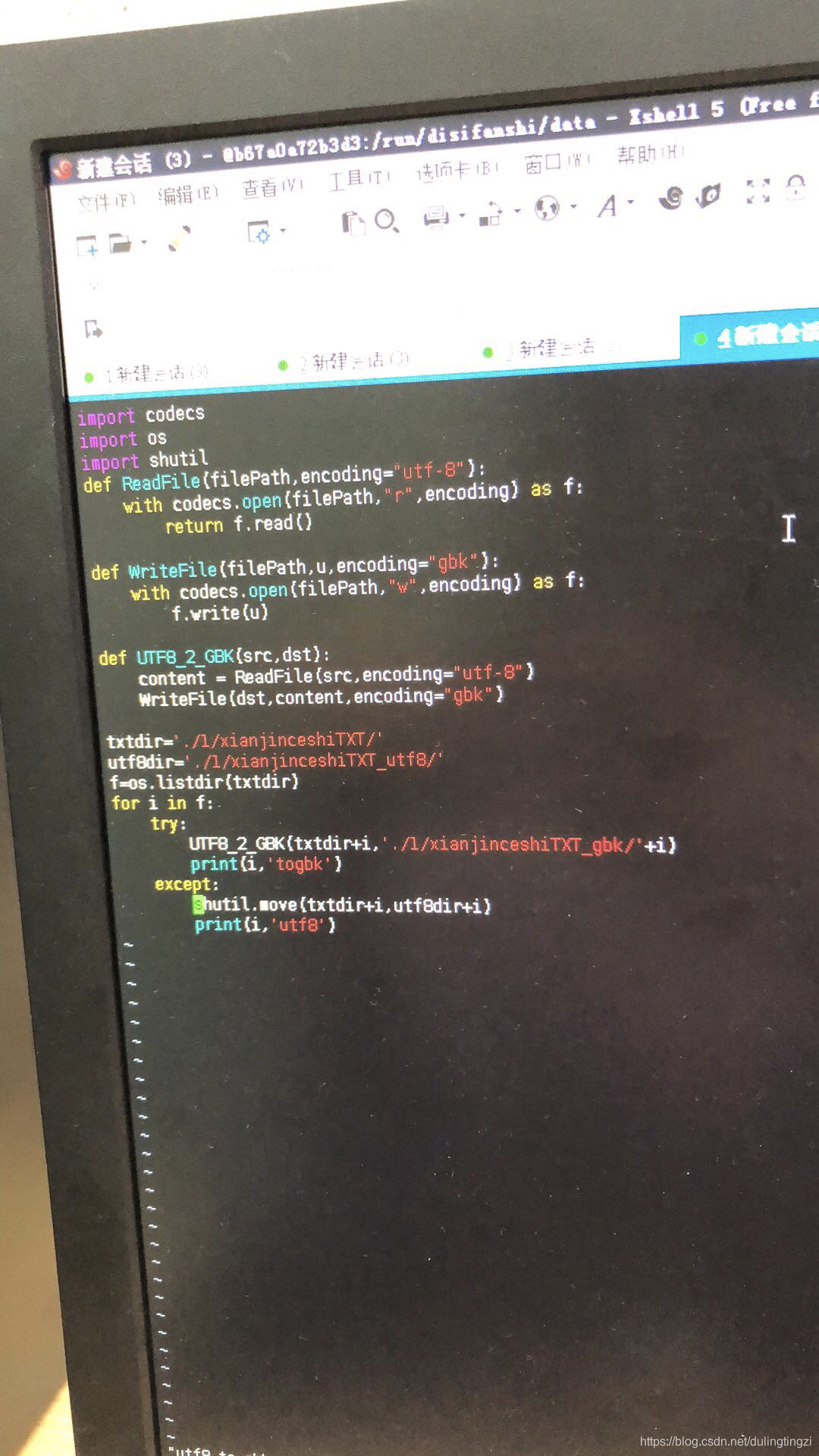

然后用notepad++把这些有问题的txt里面的换行符全部替换成空格,一键即可(notepad++真是好用)
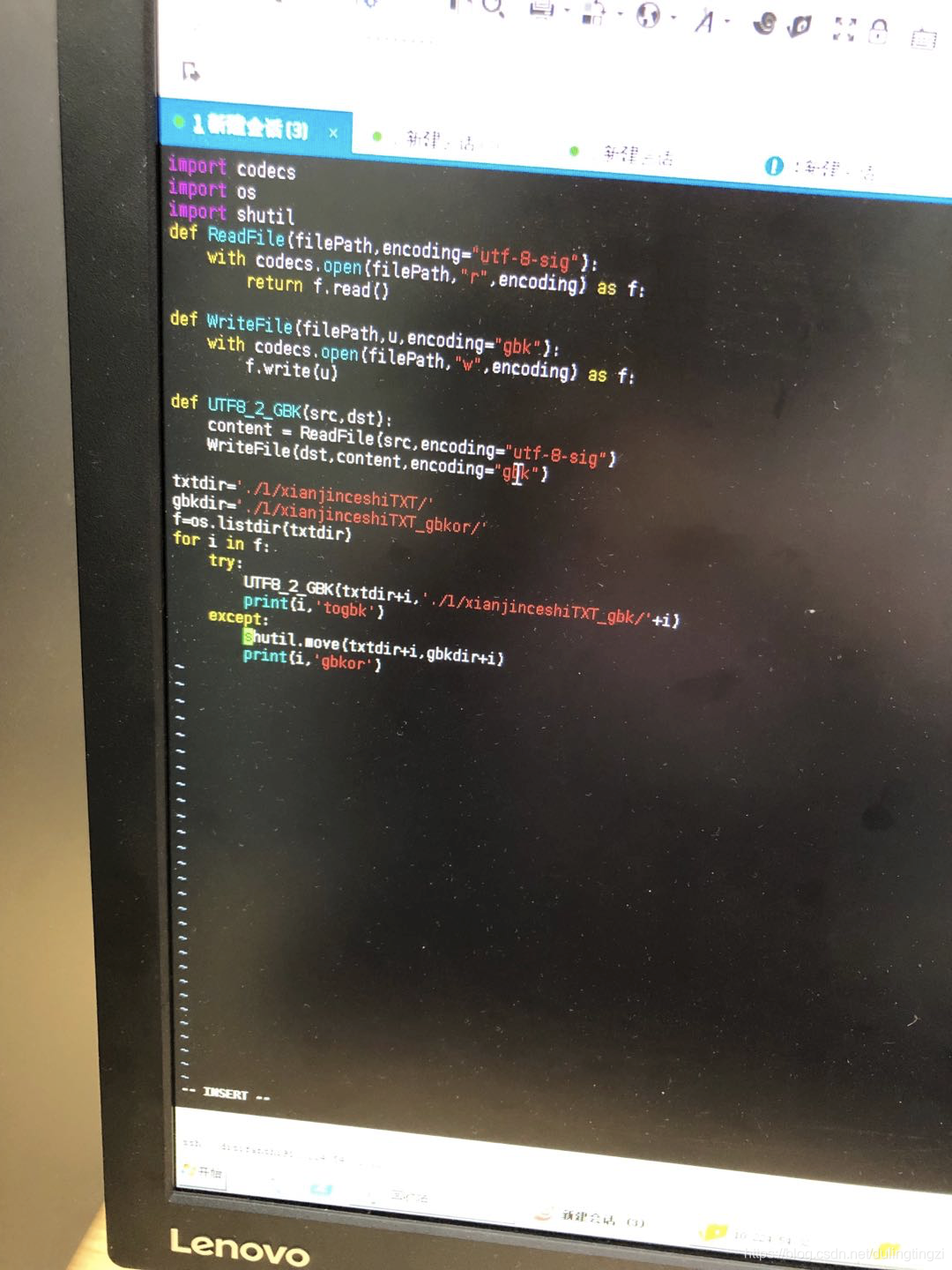
最后用下面的代码全部转成了gbk

写完这篇wiki感觉自己有当侦探的潜力,各种还原客户标注时的情形,虽然问题不是很难,但是发现问题的过程不容易啊,遇到编码问题就是要多试试多查查,瞎猫总能碰上死耗子的,不定哪种方法就成功了

















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









