






 该博客介绍了视频流Hash的计算方法,通过将文件分块并逐次计算哈希值,直至处理完整个文件。实验环境为Windows 10上的PyCharm,使用Python编程。博主分享了算法实现细节,包括文件指针管理和哈希值的连续计算,并验证了算法的正确性。实验体会中提到,虽然实验简单,但加深了对哈希应用的理解。
该博客介绍了视频流Hash的计算方法,通过将文件分块并逐次计算哈希值,直至处理完整个文件。实验环境为Windows 10上的PyCharm,使用Python编程。博主分享了算法实现细节,包括文件指针管理和哈希值的连续计算,并验证了算法的正确性。实验体会中提到,虽然实验简单,但加深了对哈希应用的理解。
实验四:视频流 Hash
一、问题描述:
将文件分成 1KB 的数据块(1024 字节)。它计算最后一个块的哈希并将值附加到倒数第二个块。然后它计算这个增强的倒数第二个块的散列,并将得到的散列附加到最后的第三个块。此过程从最后一个块继续到第一个块。
二、实验环境:
系统:Windows 10
IDE:pycharm
编译语言:python
三、程序代码与结果分析:
(1)算法实现
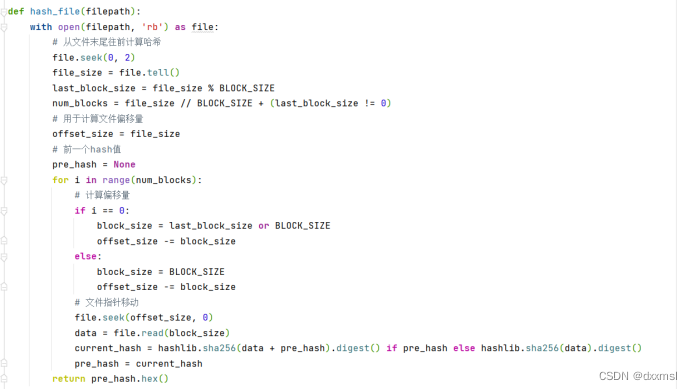
这个算法比较简单,我们只需要将文件指针直到文件结束,计算文件大小,把文件按照1024字节划分,记录下最后一块不足1024的大小,然后先让前一块hash值为空,开始计算,如果是第一块,则将文件指针执行最后一块的开始,然后读取最后一块数据,然后计算hash,对于之后的情况,每次文件指针向前移动1024字节,然后将文件内容和前一块加密连接,计算出新的hash值,直到遍历完文件结束。返回hash值,以16机制展示。
下面是main函数,我们现检验准确性,然后计算出第一个视频的hash

- 运行结果
- 可以发现,验证正确

- 实验中遇到的问题以及实验体会:
本次实验比较简单,实验过程中只有文件指针的移动稍微思考了一下,算法本身十分显然,所以没有遇到困难。
通过这次实验,对于hash的一些基本应用也有了一些了解。
源码:
import hashlib
BLOCK_SIZE = 1024
def hash_file(filepath):
with open(filepath, 'rb') as file:
# 从文件末尾往前计算哈希
file.seek(0, 2)
file_size = file.tell()
last_block_size = file_size % BLOCK_SIZE
num_blocks = file_size // BLOCK_SIZE + (last_block_size != 0)
# 用于计算文件偏移量
offset_size = file_size
# 前一个hash值
pre_hash = None
for i in range(num_blocks):
# 计算偏移量
if i == 0:
block_size = last_block_size or BLOCK_SIZE
offset_size -= block_size
else:
block_size = BLOCK_SIZE
offset_size -= block_size
# 文件指针移动
file.seek(offset_size, 0)
data = file.read(block_size)
current_hash = hashlib.sha256(data + pre_hash).digest() if pre_hash else hashlib.sha256(data).digest()
pre_hash = current_hash
return pre_hash.hex()
if __name__ == '__main__':
file = './video/6.2.birthday.mp4_download'
file_hash = hash_file(file)
print('验证正确性:', file_hash == '03c08f4ee0b576fe319338139c045c89c3e8e9409633bea29442e21425006ea8')
file_ = './video/6.1.intro.mp4_download'
print('视频1的加密结果:', hash_file(file_))
> 更多博客内容访问我的博客网站:[回锅炒辣椒的博客](https://www.xsblog.site/)


















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











