








聊聊故事点背后的故事
Q1、敏捷项目能不能不估算故事点,直接估算工作量?
【观点一】:在策划扑克法中先估算故事点有其固有的优点,最无法替代的优点是故事点不是绝对的工作量,避免了团队在迭代早期盲目的承诺,第一个迭代可以只估故事点不估工作量,是一种保护团队的行为,体现了敏捷以人与团队为本的文化,多数策划扑克法没用起来的团队往往也是这种文化薄弱甚至背道而驰的。
此时策划扑克就不是最适合的方法。在估算中如果充分进行了沟通、拆分并理解了估算对象、碰撞了观点、分析了多方面的影响,就基本是一种好的估算方法,无论你命名为什么方法;反之,严格按照策划扑克法的套路执行了但没有达到上述效果,那还是需要反思原因和改进。

【观点二】:在特定场景下跳过规模直接估计工作量是可以的,而且更简单有效,比如:需求相比老产品有延续性,团队的水平是已定的明确的并且大家看法相同没有疑义。
内外因素都有很大不确认性时,跳过规模直接估算工作量就是在冒险。这里内部因素指的对团队不同场合下开发能力的准确认知;外部因素主要是指需求。
这有点类似于另一个问题:跳过详细设计可不可以写代码?一般开发情况下,我们可采用"蓝帽"方式思维,一板一眼,严谨细致。但对开发的对象已经非常熟悉,用"红帽"的跳跃思维方式也足以应付多数的情况。
【观点三】:新研发项目或新增功能项目都可以先估规模再导出工作量(无论作什么规模单位都可以,我个人更赞同于功能点方法);产品更新维护类项目则可以直接估算工作量。
我遇到一个客户,他们是产品类项目,当一个产品推出后,后续就是针对这个产品的不断地版本更新维护,这个周期可能会延续几年时间,而一个一个的版本发布短则一周一个版本,长则一个月一个版本。而这种版本基本上都是对产品的维护,一个变更点可能涉及多个功能点的修改。
所以建议他们直接估算工作量。这里所说的变更是对发布版本缺陷修改、性能优化等。不是整块或整功能的变更。
【观点四】:让你估计一个人的体重你怎么估计?一个人站在那里,让你估计他的体重。你是思考了他的身高、体型,与自己或其他知道体重的人做了对比,然后才估计出来150斤还是130斤。在脑袋里和其他人对比时,对比了身高、体型,为什么,因为你认为这两者决定了一个人的体重。
当你估计某个需求的工作量时,你在脑袋里想了这个功能的大小,复杂度等等,然后才会得出工作量的估计值,你在脑袋里估计了规模,不是没估计规模!你在脑袋里的运算过程要和其他人沟通一下,这才有了故事点、功能点、复杂度等等!你想到了,你得说出来或写出来,和其他人达成一致,这才是本质。
有些软件估计规模是没用的,因为规模没有决定工作量,比如人工智能对弈的软件AlphaGo,对其估计规模就没有太大意义,复杂度才是对这类算法软件最重要的影响工作量的因子。故事点其实不仅仅代表了规模,还包含了复杂度在里面。
所以,我认为:在估计工作量之前,是要估计规模或复杂度,无论你叫故事点,还是功能点,或者其他计量单位都无所谓,需要说出来,和别人讨论一下!
Q2、在估算的时候,其实无法说服自己去考虑过规模这个维度,甚至需要跟很多人解释规模的确切定义是什么。得出经验判断,往往就是一个模糊不清晰的过程,为什么是3而不是5,也是无法说服自己的。
【答】:考虑规模,复杂度等,就是让你清晰的过程。估计工作量之前考虑规模,复杂度等,就是要让你讲理!估计为3人天、10人天的理由是什么?说出道理来!
不是敏捷要求你做规模估算,而是:你在估计工作量估算时,就做了规模估计!
Q3、感觉就是3人天,没去细想为什么。这也是为什么快的一个原因吧。那可能不同的人,在应用经验法估算的时候,也有不同的思考深度之分。
【答】:快,未必代表好。一大本需求,一拍脑袋,需要3人年,这种估计有啥用啊?为什么3人年,得讲出道理来,所以需求要拆分、细分,对小需求估算,累加起来,然后得到总数。每个小需求怎么估计?也得继续拆分,继续讲理。拆细后,估算的总体结果更接近实际。
这篇博文里有关于这个理论的描述:https://blog.csdn.net/dylanren/article/details/28239921。
不讲理的估算无法说服自己,无法说服别人,不能起到激励的作用,不能起到作为管理基准的作用,也就会导致计划与实际的大偏差,不能承诺,或承诺了也没人信。
Q4、并非不讲理,而是讲不出理。也许大脑神经元的关联并非简单的线性关系,一些决策不一定非得通过右脑的逻辑思维来组织一个完美的答案,经验法和模型法的偏差到底多大似乎也没有定论。
【答】:这里需要区分一下估计工作量的方法:
1不讲理的估算方法。
2经验法。
3模型法。
你说的讲不出道理,是第一种,这在实践中其实不存在,因为总能有道理。
经验法不是不讲理。故事点也是讲理的。宽带DELPHI方法也是经验法,也是讲理的,需要大家讨论为什么那么估算。
模型法与经验法的估算差别多大,我有2个研究结论给你参考
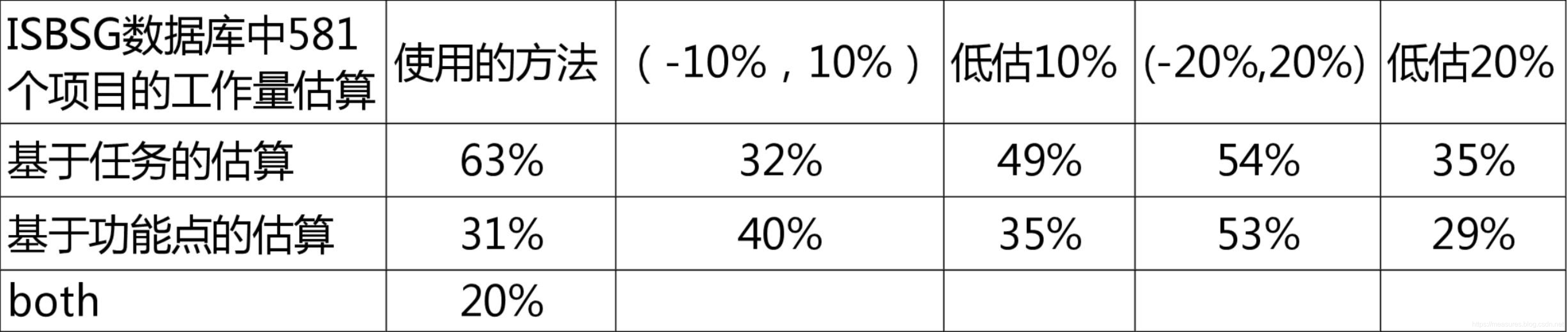
Capers Jones、Standish的研究结论表明:采用模型法进行估算的项目成功的概率是采用经验法估算的项目的2倍!
Q5、如果能明确讲出来规模和复杂度及其换算关系,那还叫经验法吗?是否属于经验法,区别在于这些估算过程的运算逻辑是书面的还是非书面的?预测投入和其准确性应如何平衡才是合理的?
【答】:我们所说的模型法,是指有数学公式来计算的方法。
其他的都归类到经验法了。
在工作量估算时,我们也可以采用定额法:
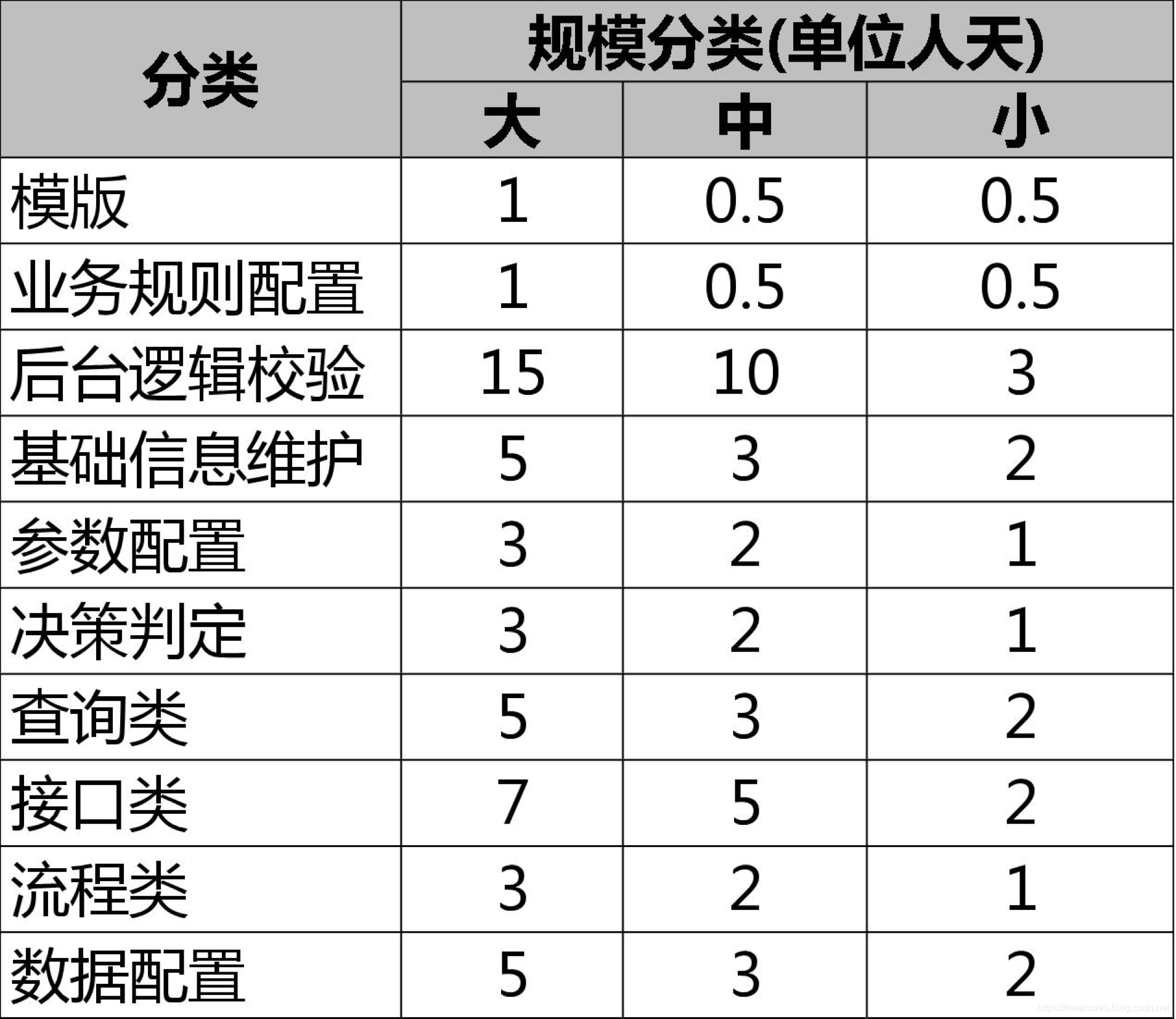
如,先对历史的同类的软件进行类别与规模大小的划分,得到如下的经验数据表:
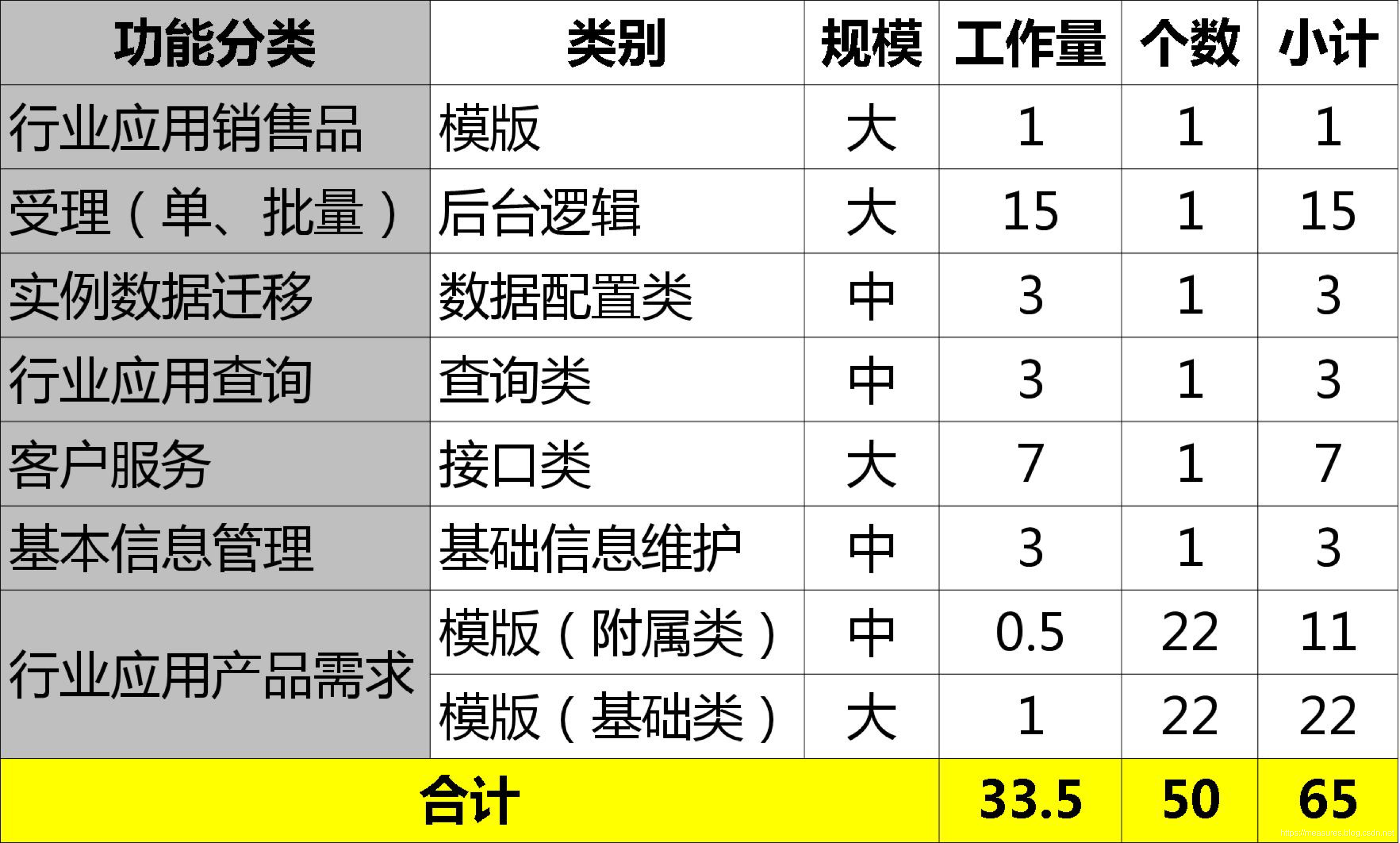
当拿到一个具体的项目需求后,再对新项目的需求归类、区分规模的颗粒度,然后查表得到工作量的估算:
这个方法里面的定额是怎么得到的?
1没有历史数据时,靠回忆,靠经验得到。
2有历史数据时,要建立历史数据的性能基线得到定额。
这种定额法是否也算模型法呢?我们也可以认为是模型法,只不过这个模型是查表得到的而已。
Q6、规模*复杂度*效率=工作量。如果这个也算公式,那它应该不属于经验法了
【答】:是的,有公式算模型法。
Q7、数学公式也应该有设想公式和经统计学证明的公式吧。如何证明这个设想公式的有效性?
【答】:数据公式的合理性要做回归分析,证明有效性。
很多公司自定义了工作量估算方法,这种方法是否合理呢?需要把实际的工作量与估计的规模进行相关性分析,看看是否强相关!
如:某嵌入式软件公司将需求细拆分之后,直接用需求的个数代表软件的规模,没有采用功能点、故事点、代码行等方法度量规模,对多个项目多个周的数据采集分析后得到如下的回归方程:
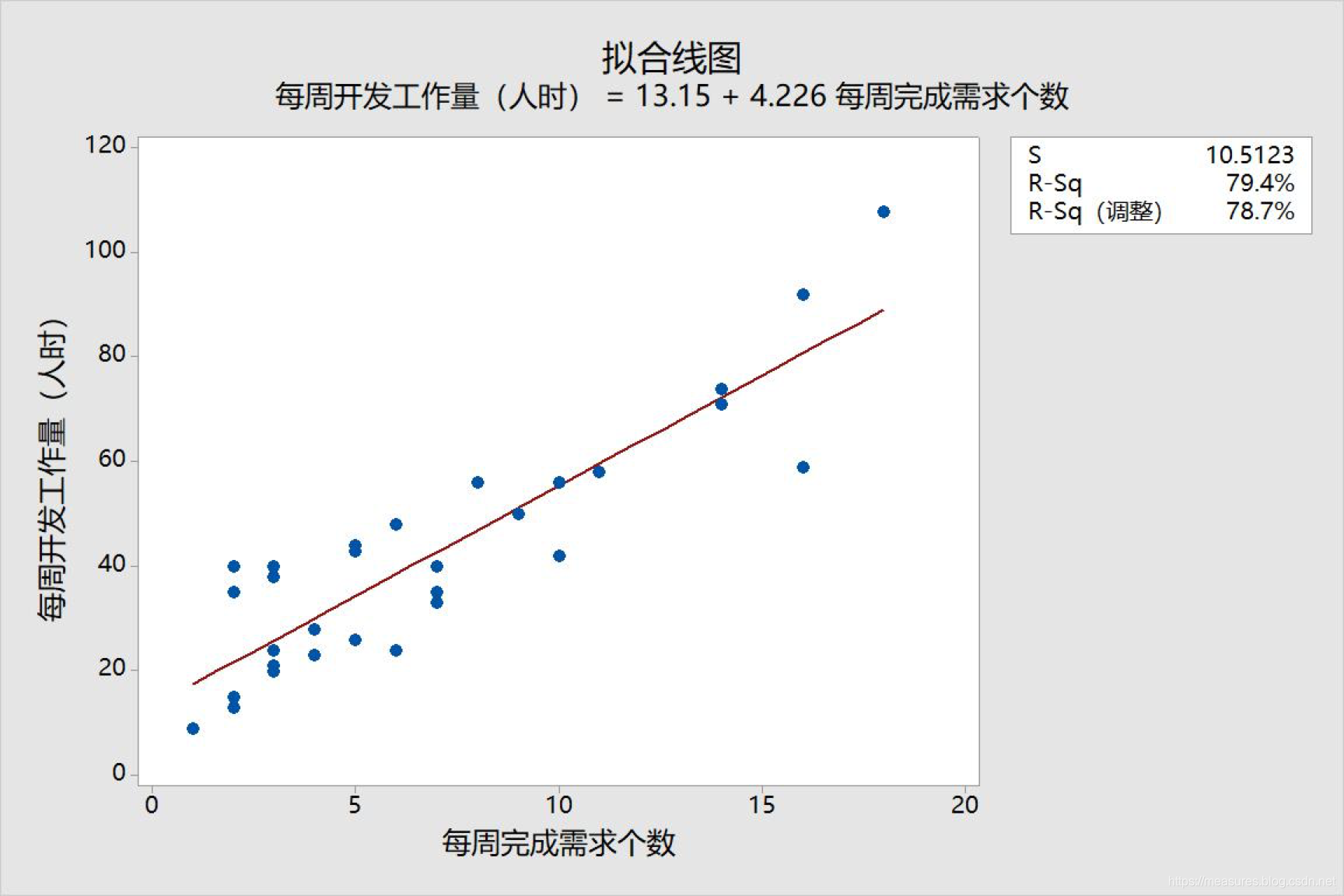
 转存失败
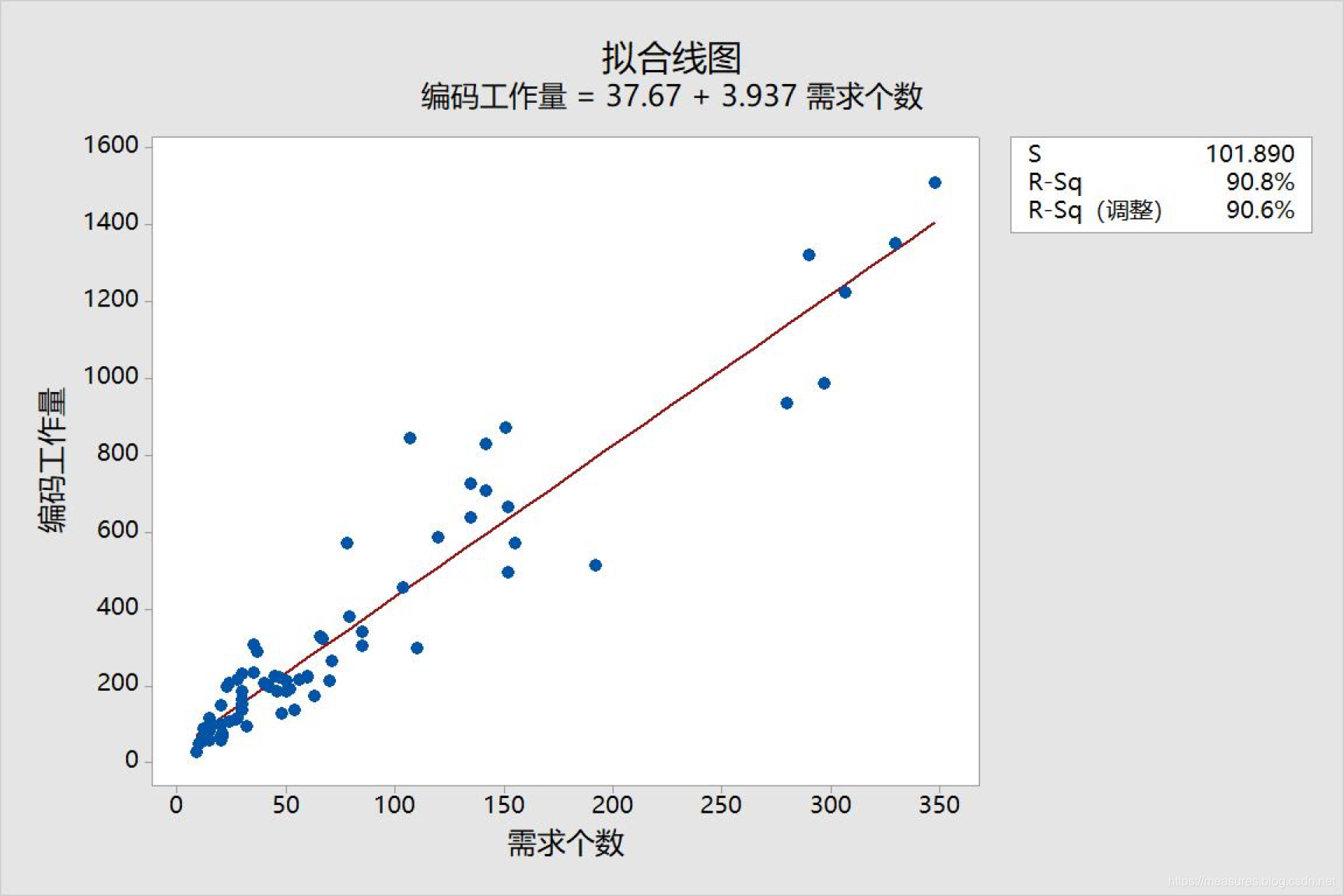
转存失败某银行软件开发公司,也是直接计量了需求个数,然后估计工作量,历史的79个历史项目的数据证明了这种方法在本公司内的合理性:
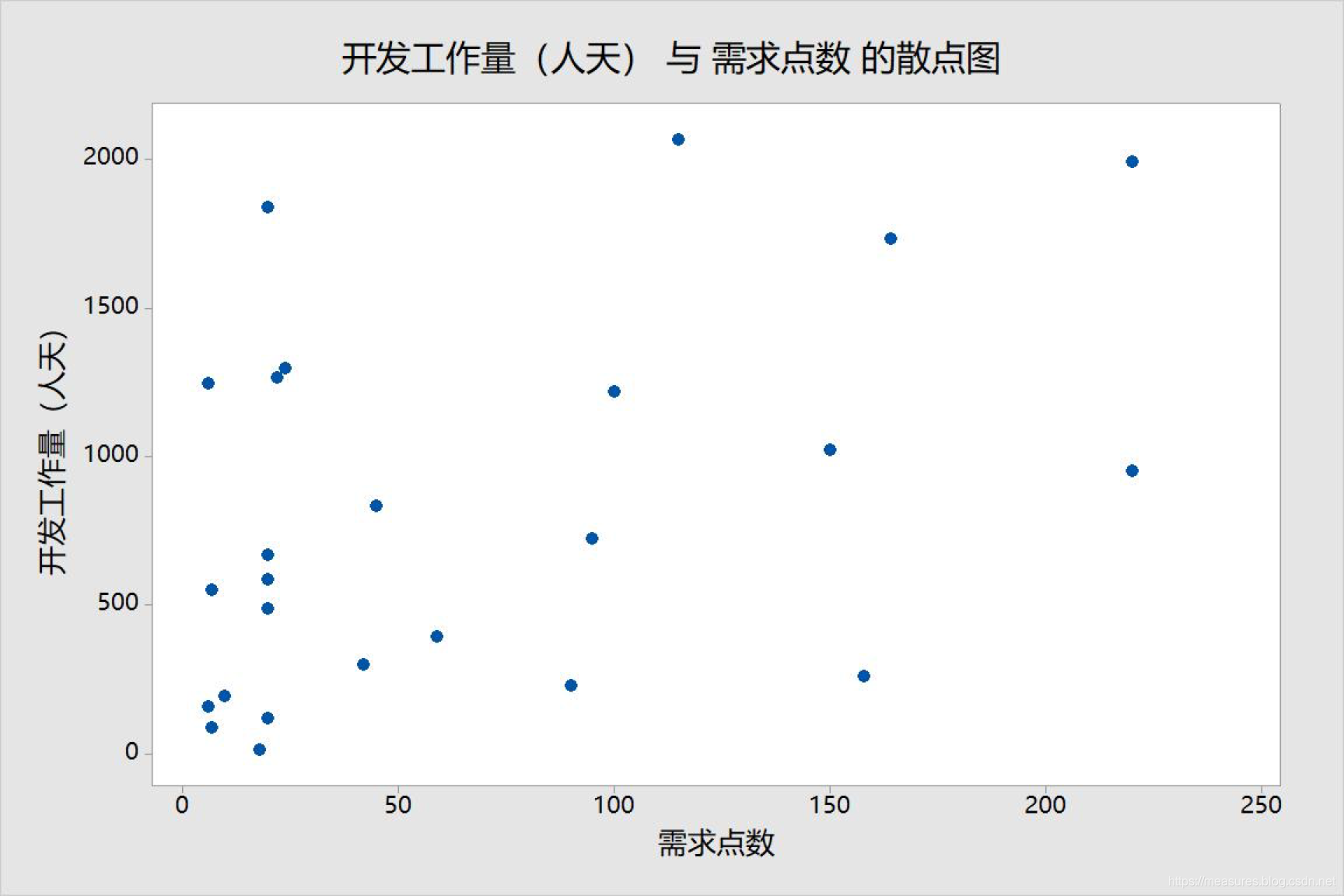
而也有的公司自定义了需求点数,但是历史数据却证明了这种方法的失败,也就是在这家公司内定义的需求点是不合理的:
有一个客户提供了一个项目的故事点与工作量的散点图:
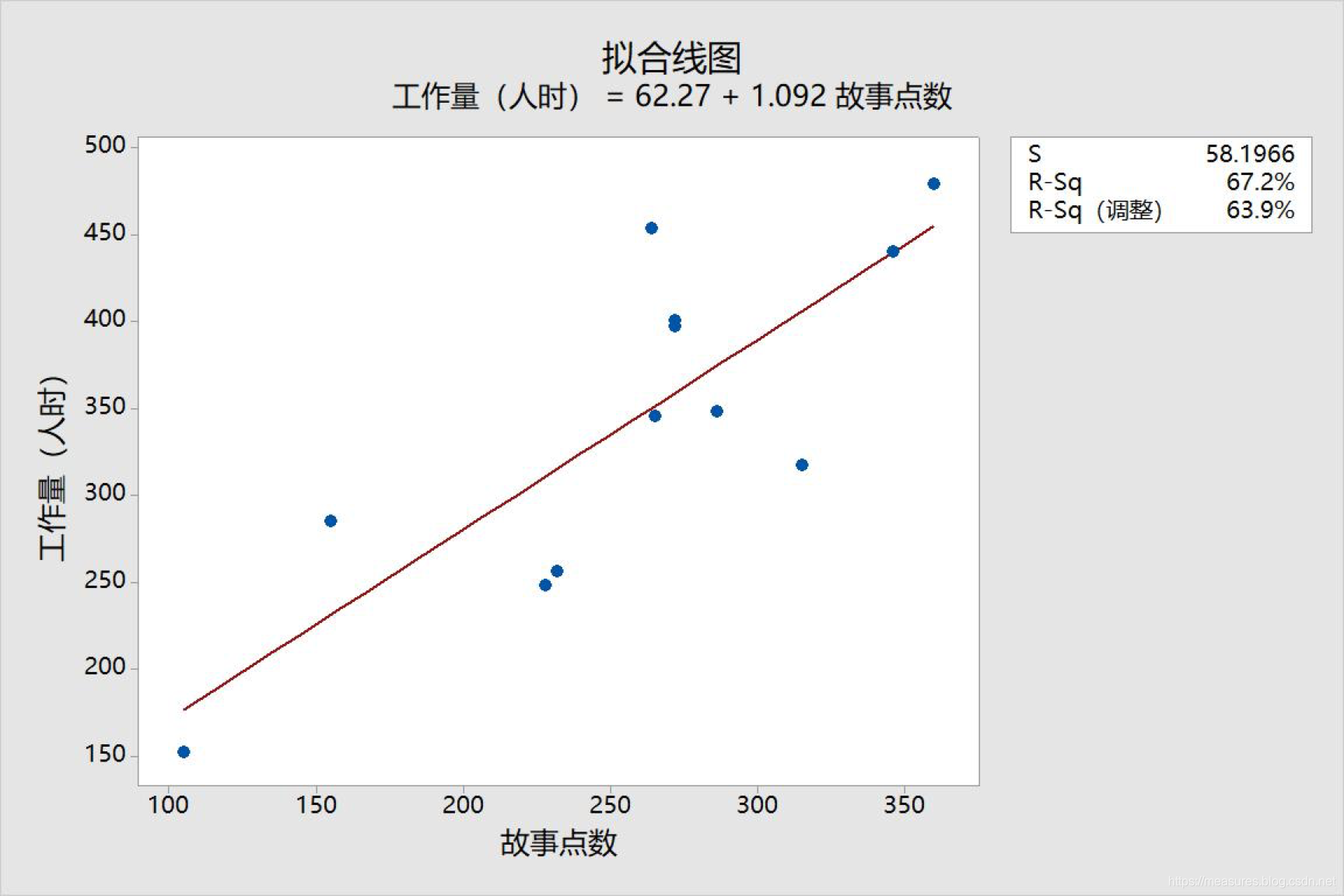
此图可以说明在此项目中采用故事点的方法也是合理的。
在敏捷界也有专家提倡采用鸡蛋法估计规模,就像我们买鸡蛋时数个数不称重一样,其原理同上,只要你数的是鸡蛋,而不是把鸡蛋与鹌鹑蛋一起数即可。鸡蛋的大小要有可比性!不能两个鸡蛋的规模偏差太大!

也有公司采用了业内的公式到自己公司内来使用,比如有的公司采用了COCOMO模型,或者业内的一些度量组织公布的模型,此时,都需要在公式内用自己的实际数据做调整,否则,这个模型的偏差可能很大!正如我们不能用美国的胖子标准来判断中国人是否胖类似。
Q8、那经验法与模型法的区别,是有没有公式,还是有没有去做这个证明?
【答】:模型法要有公式或模型。有模型没有用历史数据验证,这是模型本身的问题。
我看到的很多企业是有这个公式的,但是这个公式没有历史数据的证明,所以通常都会给客户提一个改进建议:估算模型或方法的合理性应基于收集的历史数据通过相关性分析等统计手段进行验证。
Q9、工作量估算一个作用是预测,做估算需要花时间,花了时间但预测结果不一定准确,如何取舍?经验法偏差30%,人力资源投入3分钟,模型法偏差5%,人力资源平均投入1小时。如何选择?
【观点一】:可以是一种平衡,需要考虑投入产出,这种投入产出是否可以准确度量呢?这需要思考。另外当我们理解工作量估算的作用时,仅仅是预测吗?
我们做sprint planning就是为了做计划吗?我们做策划扑克法就是为了做估算吗?
沟通在前,沟通是过程,估算值、估算结果是这个过程的输出。
做估算的目的我自己更倾向定义为:
1沟通,达成一致的深刻理解。
2得到一个估算值,作为计划的基础。
这也是为什么我力主把COSMIC规模度量方法作为一种需求梳理的手段导入到项目组中,度量出的功能点是自然的输出,也可以认为是副产品。
正如测试驱动的开发,测试不是目的,是手段,产品代码才是目的,才是最终的交付物。
【观点二】:我认为在估算时,大家初次对一个故事进行估计,并发现结果不收敛时的价值,远远大于收敛的价值,所以估算的价值在于:
1、它是一种对需求是否达成了一致理解的判断方法。
对需求达成一致理解是需求沟通的目的,怎么判断这个目的是否实现了呢?判断需求是否达成一致理解的方法我们可能罗列出来一堆,但是通过是否收敛来判断更直观。
它可是“量化”的。如果收敛了,那么我们不能判断需求理解是100%的达成了一致,但是,如果不收敛,我们可以100%的得出来结论,不收敛的原因包括:
a) 有人对需求有误解,需求理解不一致;
b)需求有缺陷。
通过给出估算值最高和最低两组人的对需求理解的陈述及讨论,我们可以达到第9问观点二第2条所列的价值。
2、发现需求缺陷,有助于Team的成长
需求能否挑出来错,那倒不一定,也许能挑出来,也许不能。但是这一定是Team成长、分享的最佳时机。给需求挑错的方法,大家首先想到的是评审。
在估算值离群的成员陈述需求理解的环节中,可能得到的结论:
a) 估算值低的:
可能1:对需求想简单了--证明需求描述模糊 或者对业务的掌握不全面;
可能2:开发资源了解更透彻,掌握的开发资源更多。
b) 估算值高的:
可能1:需求想复杂了–-证明需求模糊或者对业务的掌握不全面;
可能2:开发资源了解不足。
如果需求模糊,那就是给需求挑出来了缺陷。如果需求没有问题,针对估算值离群成员发言的讨论就是更有针对性的分享和培训!
可惜的是,在估算值离群的成员陈述的时候,大多都说:“我理解错了”,而不去向其他成员陈述自己到底是怎么理解的,其他成员也不去追究他们到底是怎么想的,片面去追求尽快的达成估算的收敛状态。
如果抓不住怎么交流需求这个环节,策划扑克牌估算的价值就大打折扣了。
3、督促TEAM独立思考自己对需求的理解
如果自己的估算值离群了就需要解释自己的看法,为避免尴尬,聪明的人就要有所准备,那就是如果自己离群了,自己怎么表达自己的看法,这是一种压力!评审的效果如何,部分依赖于评审专家的责任心,如果没有个人评审效果的评价,他们是没有压力的。
4、避免因为需求缺陷或对需求理解不到位而导致的返工。
Q10、这些附加值是不是只有估算一种途径来解决?
【答】:嗯,可以有其他的方法替代。
但是是否比这个方法更好呢?正如很多企业不做TDD,采用其他方法做质量控制,是否效果能比TDD更好呢?
Q11、是否可以根据真实反馈对估算进行修订?
【答】:可以。
1、对于估算的结果,如何发现和实际结果偏差较大,可以根据实际调整估算结果,对未开工的任务调整估算值。
2、在估算领域中有估算锥的模型,随着时间的推移,随着项目的进展,估算的偏差率是逐渐缩小的。
3、如果你采用了模型法进行了估算,y=ax+b, y为工作量,x为局部规模。在实际中对几个需求或几个模块用了几次模型,发现在本项目组中存在一致的偏差,此时你可以调整公式中的b或a的值,来调整估算模型。
如果x是整体规模,即,项目的总规模度量值。模型的不适用性只能到项目结束时才能发现,此时已经没必要修改估算值了。我们的客户大地保险是x为局部规模与总体规模都建立了模型。

















 5261
5261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









