







最近大家对pandas-profiling的好评很多,主要是它可以只使用一行代码就能获取数据的很多信息,于是乎,我也想安装试用一下,结果安装过程就遇到了很多问题,还好有百度的众多大神在,问题都得以解决。我这里实在jupyter notebook中实现的。
1. 安装pandas-profiling
可以使用conda或pip在Anaconda Prompt中进行安装
pip install pandas-profiling
conda install -c conda-forge pandas-profiling
会出现下面的报错
ERROR: Cannot uninstall 'llvmlite'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
从报错可以看出llvmlite的问题,具体不是很清楚,但是可以用下面的方法来解决
解决方法
pip install --ignore-installed llvmlite
如果出现其他的错误,可能是pip包需要升级或者matplotlib包需要升级,按照提示把要升级的包进行升级就ok了
#升级pip
python -m pip install --upgrade pip
#升级matplotlib
pip install --upgrade matplotlib
这样基本就可以安装成功了。
2. 使用pandas-profiling
先导入需要的包
import pandas as pd
import pandas_profiling
读取数据并生成报告
这里以一份油品数据为例,调用profile_report方法生成EDA分析报告
data = pd.read_excel('oil_data_for_tree.xlsx')
查看报告
pandas_profiling.ProfileReport(data)
使用to_file方法另存为.html文件
profile = data.profile_report(title="oil_data")
profile.to_file(output_file="oil_data.html")
3. 查看报告
上面简单几步就可以搞定啦,现在我们来看下生成的报告

可以看出报告大体由5部分组成,分别是
1. 数据集概况(基本信息)
- 变量数(列)、观察数(行)、数据缺失率、内存;
- 数据类型的分布情况
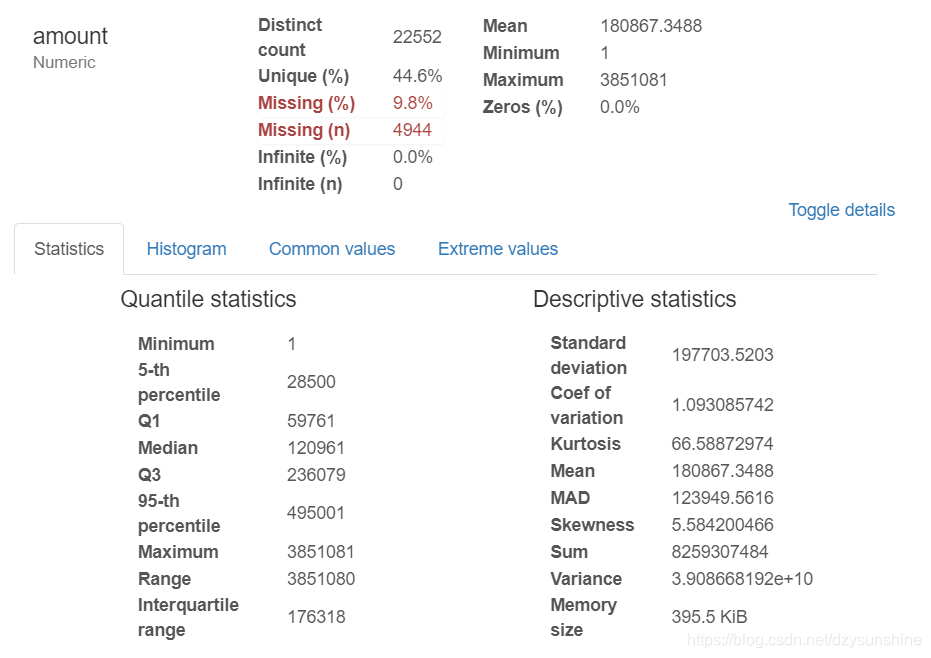
2. 每个变量的详细情况
- 要点:类型,唯一值,缺失值
- 分位数统计量,如最小值,Q1,中位数,Q3,最大值,范围,四分位数范围
- 描述性统计数据,如均值,模式,标准差,总和,中位数绝对偏差,变异系数,峰度,偏度
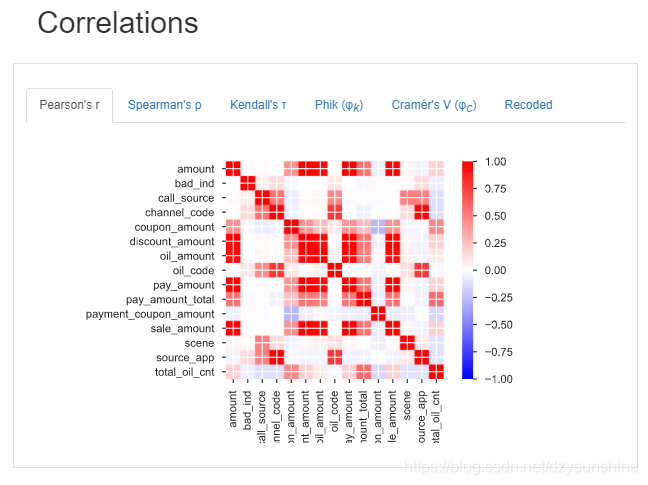
3. 相关性分析
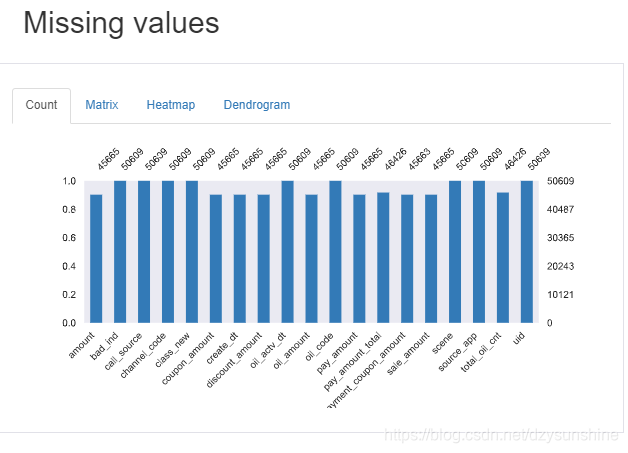
4. 缺失值情况
5. 样本信息
具体就不再一一列出,下面是报告里的一些图片,少量的代码就可以获取如此多的的信息,非常好用。
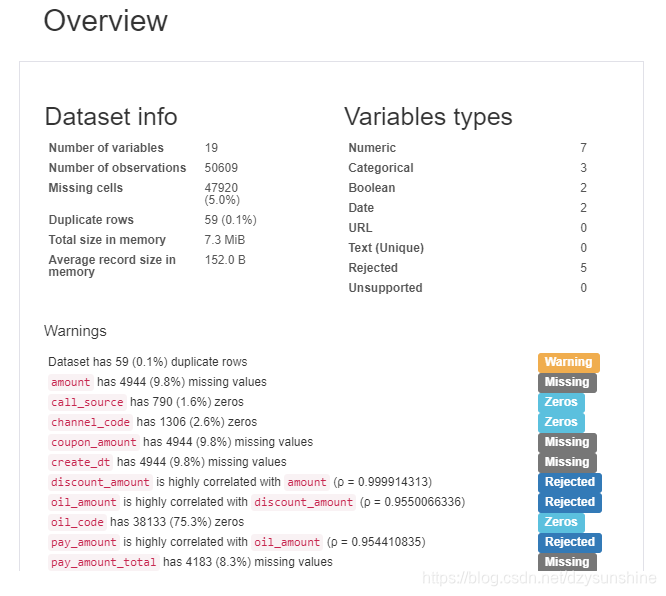
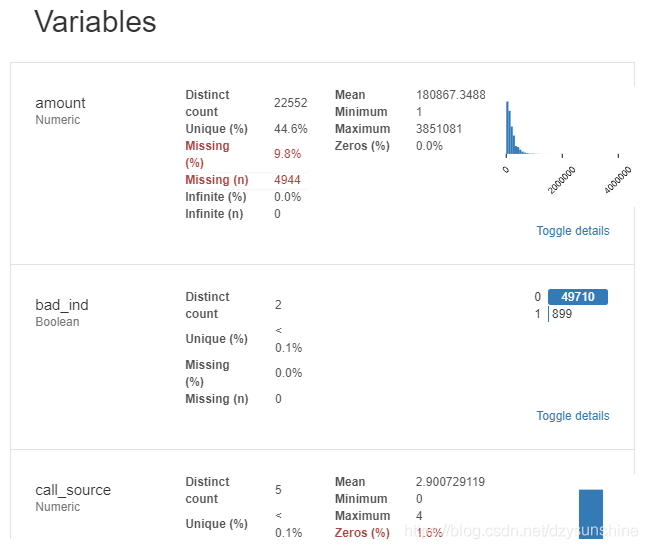
点击Toggle details,还有更为详细的信息
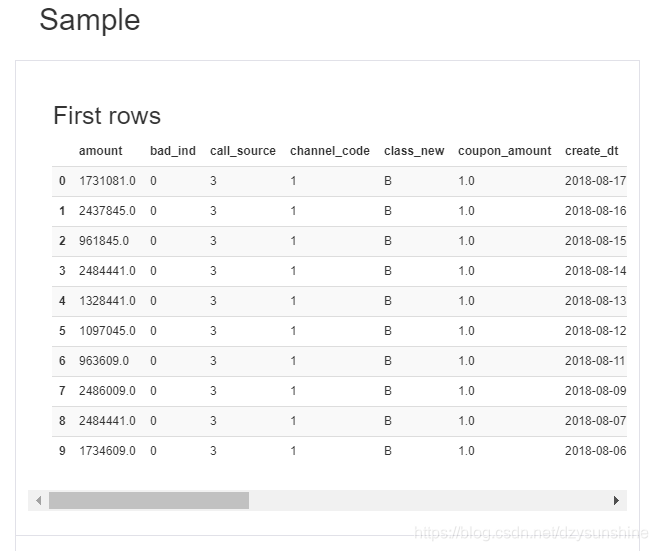
pandas里面的df.head()和df.tail()两个函数
4. 参考
https://mp.weixin.qq.com/s/y_8G8fnNloAyjrDt21Hw9A
https://blog.csdn.net/Andy_shenzl/article/details/81709409














 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









