






前言:目前翻译都是在线的,要在C#开发的程序上做一个可以实时翻译的功能,好像不是那么好做。而且大多数处于局域网内,所以访问在线的api也显得比较尴尬。于是,就有了以下这篇文章,自己搭建一套简单的离线翻译系统。以下内容采用python提供基础翻译服务+ C#访问服务的功能,欢迎围观。
系统环境: WIN10
开发环境:VS2022 + VS CODE
开发语言环境: Python3.8 + .NET 6
以下正文:
1、由于本地环境没有python,所以先安装python有关环境先。
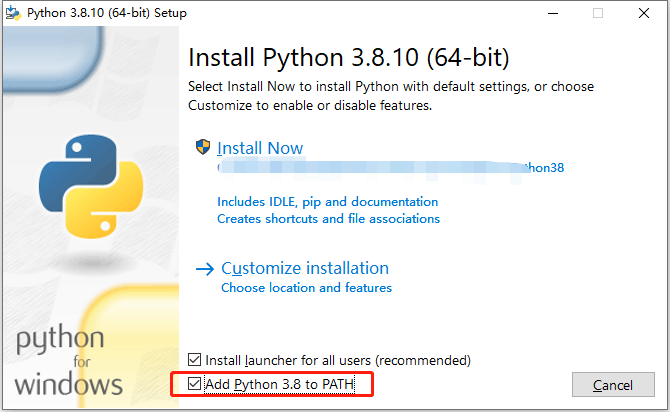
2、安装好以后,控制台下输入 python,进入如下终端内容,就代表安装成功了。建议安装时候,选择自动添加到环境变量里面,这样不需要自己配置了。

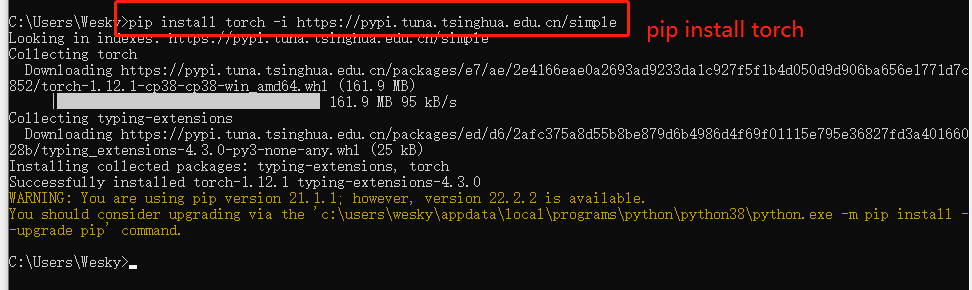
3、由于翻译功能,会使用到一些已有的模型进行计算,所以以下需要安装几个包。第一个是pytorch, 输入 pip install torch 即可安装。如果安装比较慢,在后面设置一个镜像,可以加速,例如此处我使用的清华的加速器:https://pypi.tuna.tsinghua.edu.cn/simple
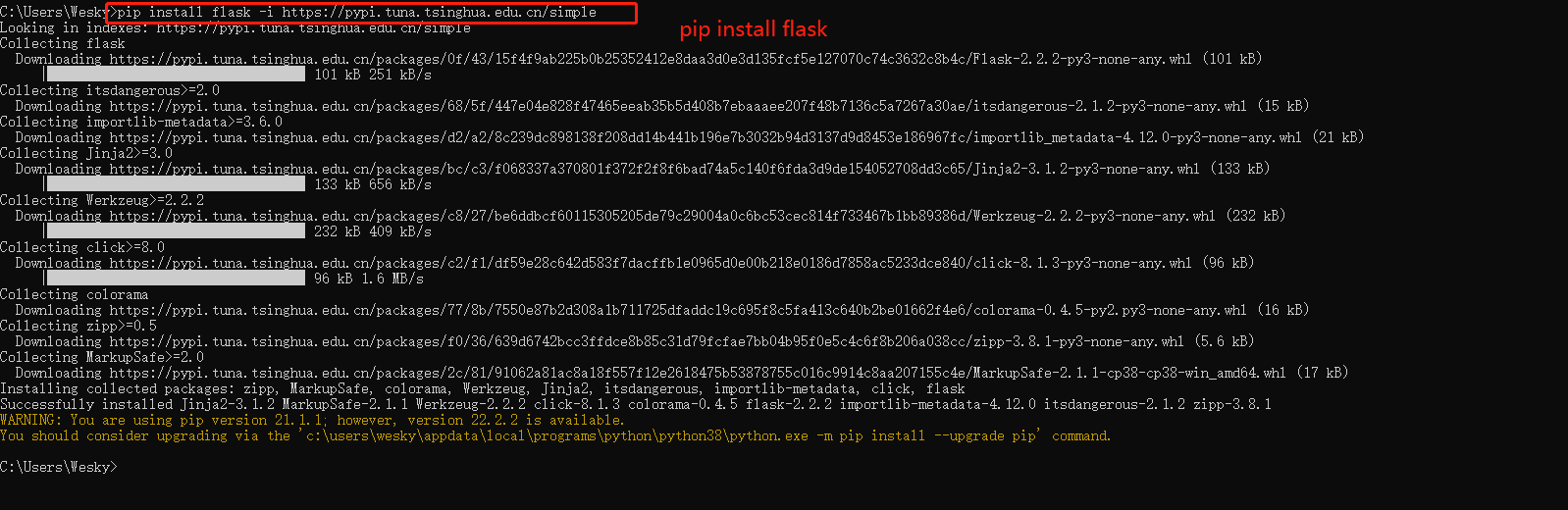
4、然后安装flask: pip install flask
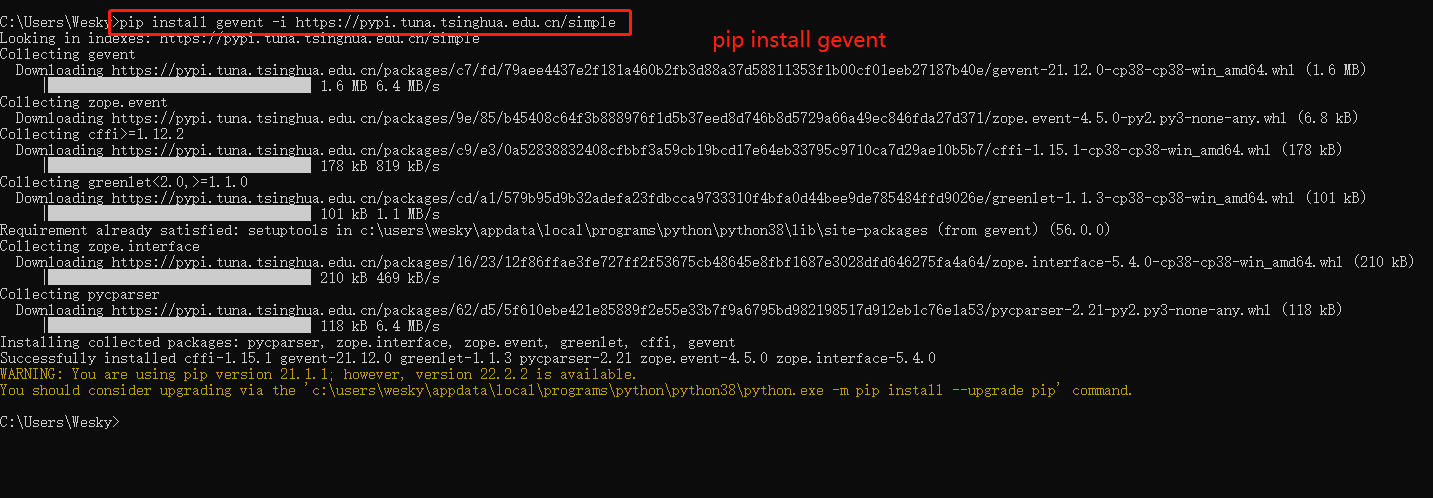
5、接着需要安装 gevent: pip install gevent
6、接着是 transformers
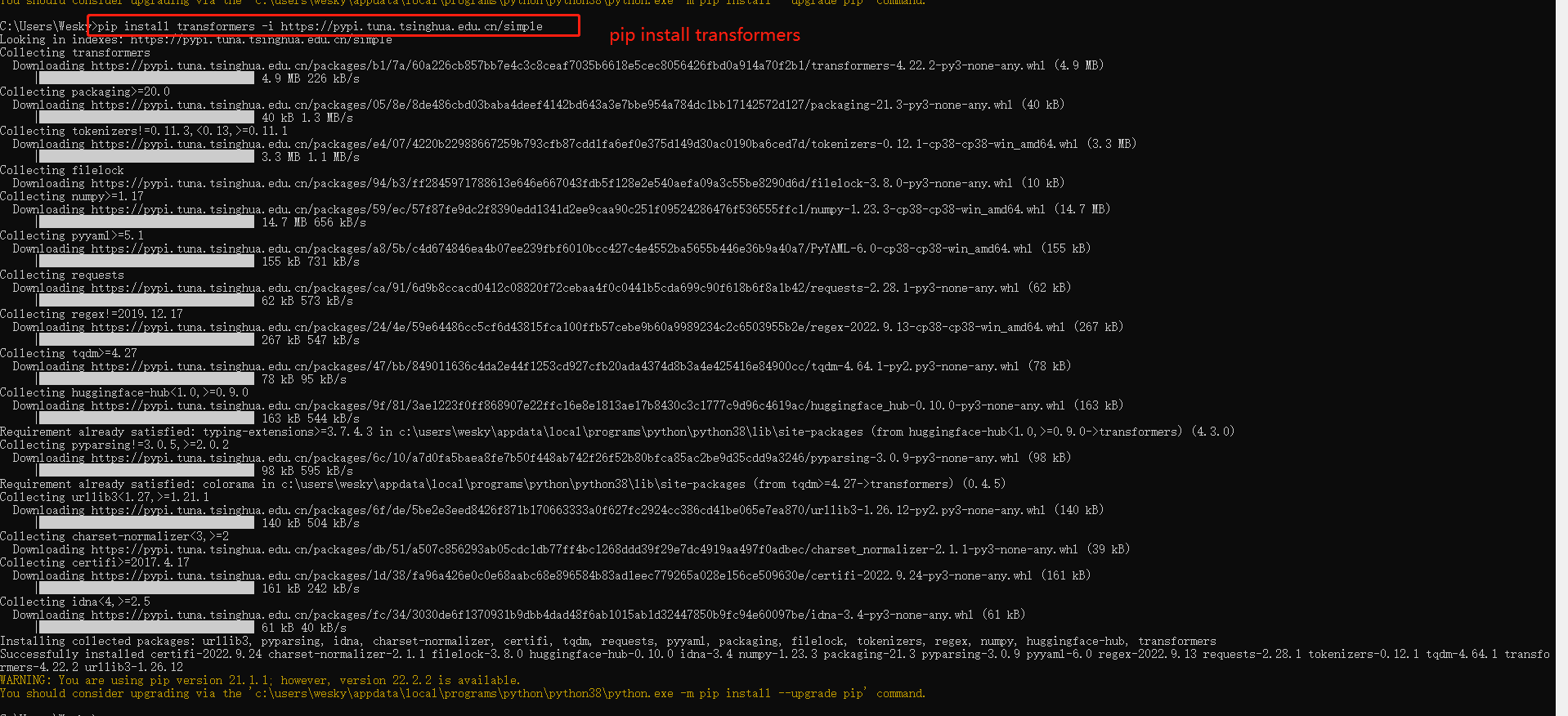
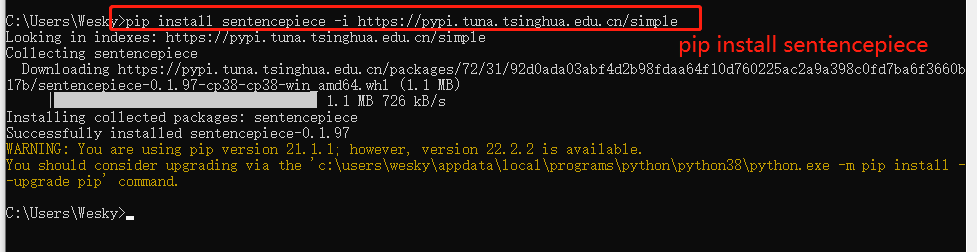
7、安装transformers时候,有的会自动安装sentencepiece包,有的时候不会。如果上面查找没有,就手动安装一下:
8、以上包安装完毕,打开VS CODE,创建一个python语言文件
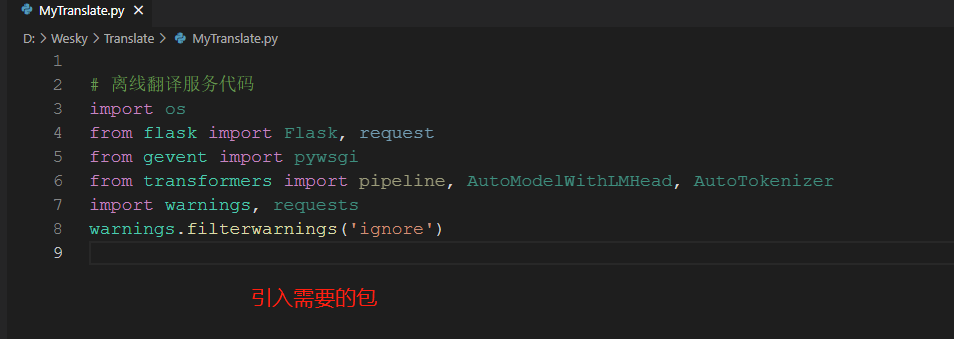
9、此处文件命名为 MyTranslate.py 然后引入可能所需要的包
10、接着,上 https://huggingface.co/Helsinki-NLP 上面,查找需要的语言翻译模型。此处使用的离线翻译,使用的该项目下的。
11、Models里面有上千个语言模型,选择自己需要的名称,记住就行。
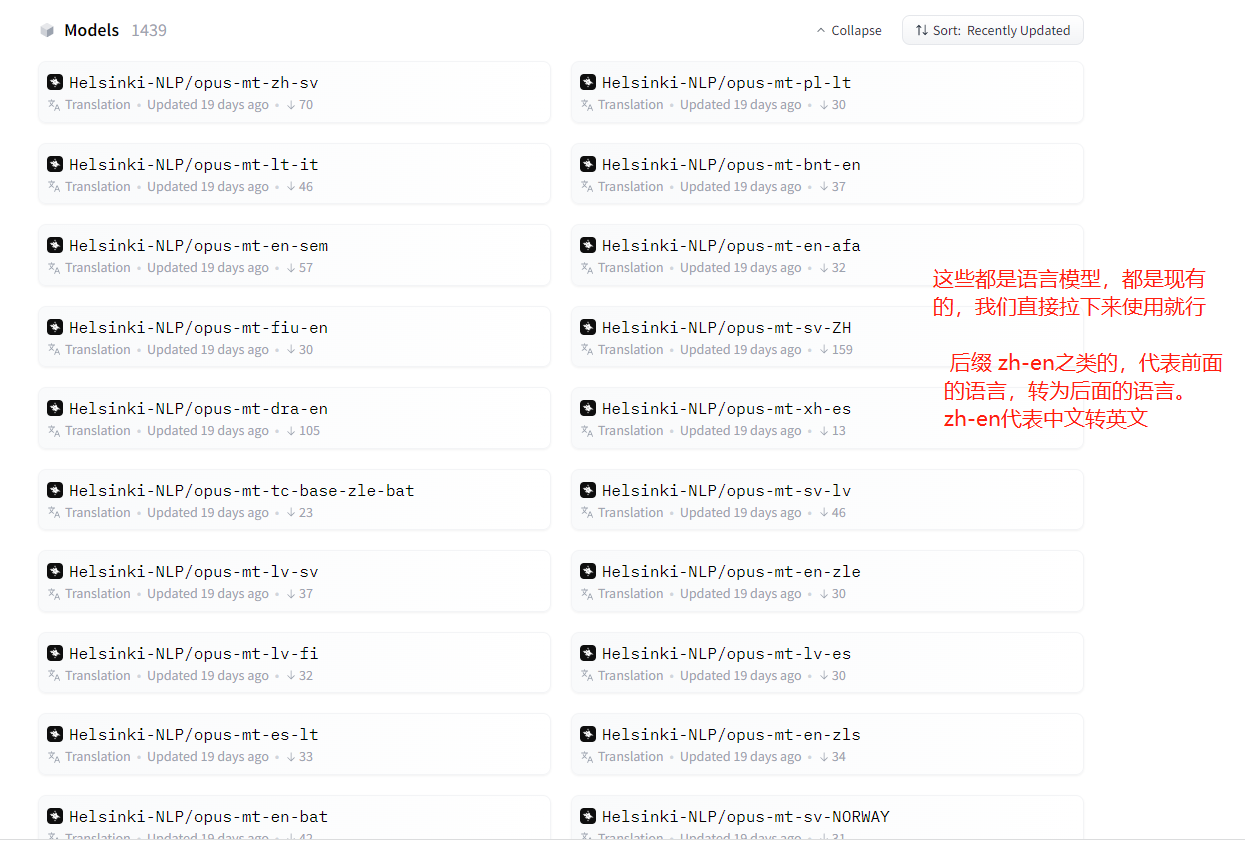
12、此处,我选了四个模型,分别是英汉/汉英 以及德汉/汉德的翻译模型。有关代码实现如下所示。
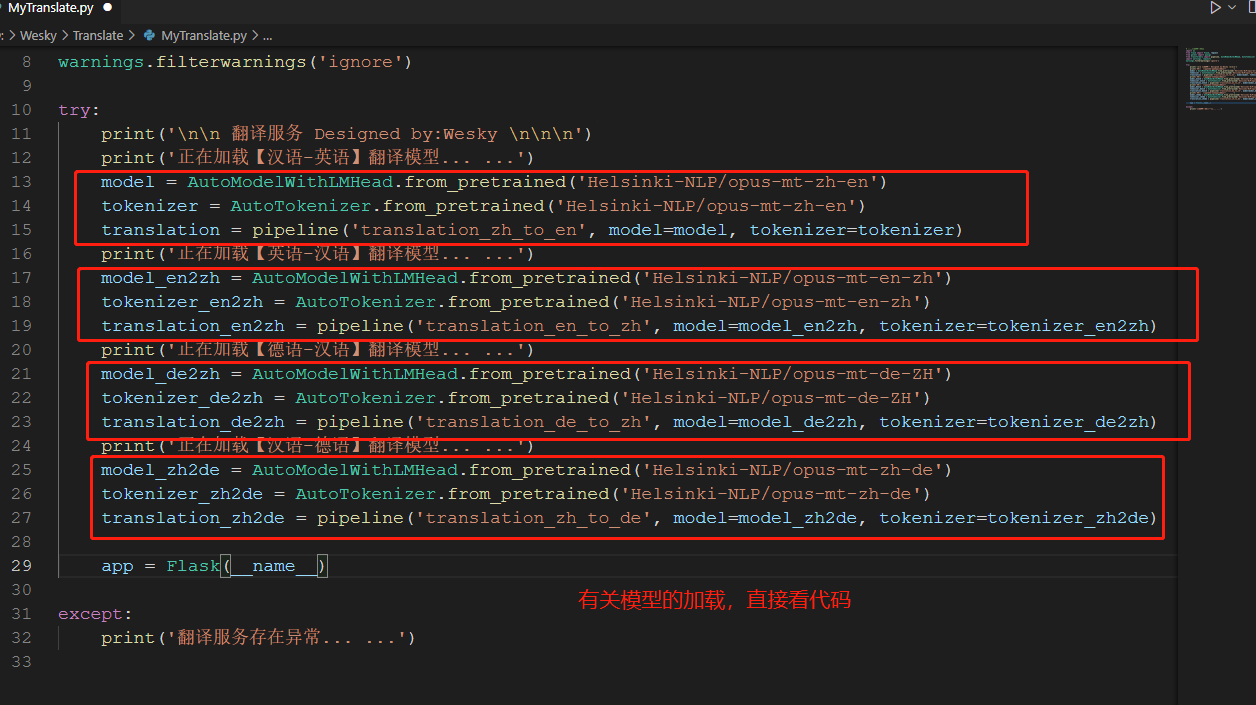
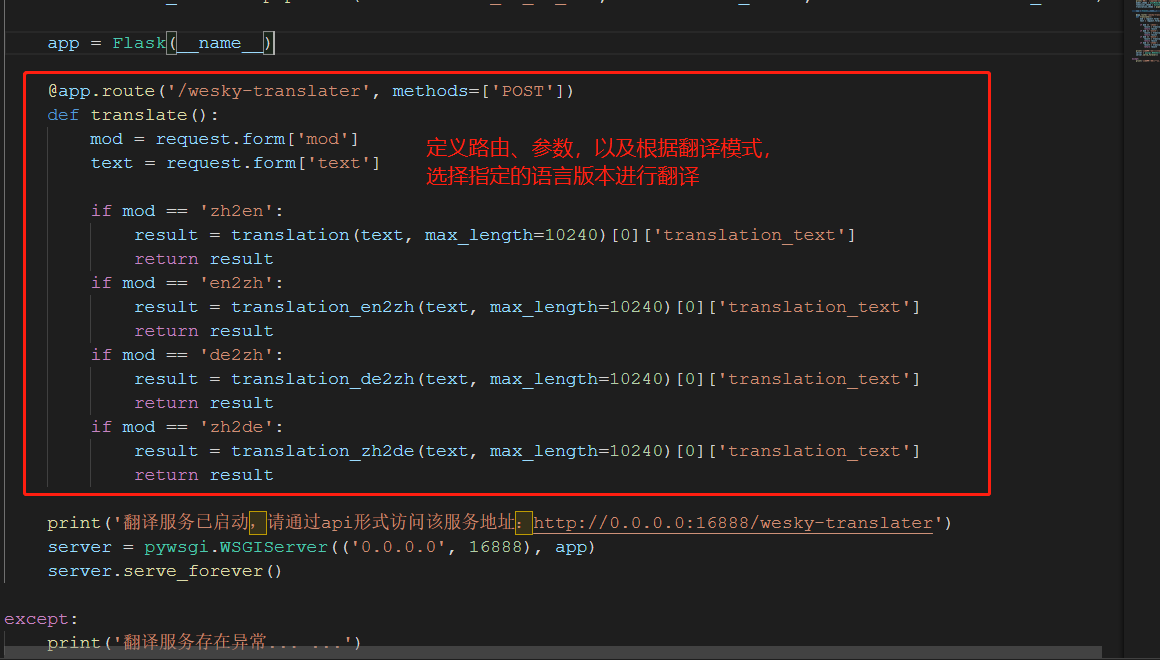
13、接着定义一个api接口,用于提供给外部访问(毕竟主业不是python,提供api就可以跨语言来访问该服务了)。有关代码如下所示。
14、VS CODE上运行程序,可以看到终端控制台上面打印出一些下载进度。这是因为本地现在还没有模型,我们选择的四个模型,会被下载到本地来,这样下次就不需要再下载模型了。
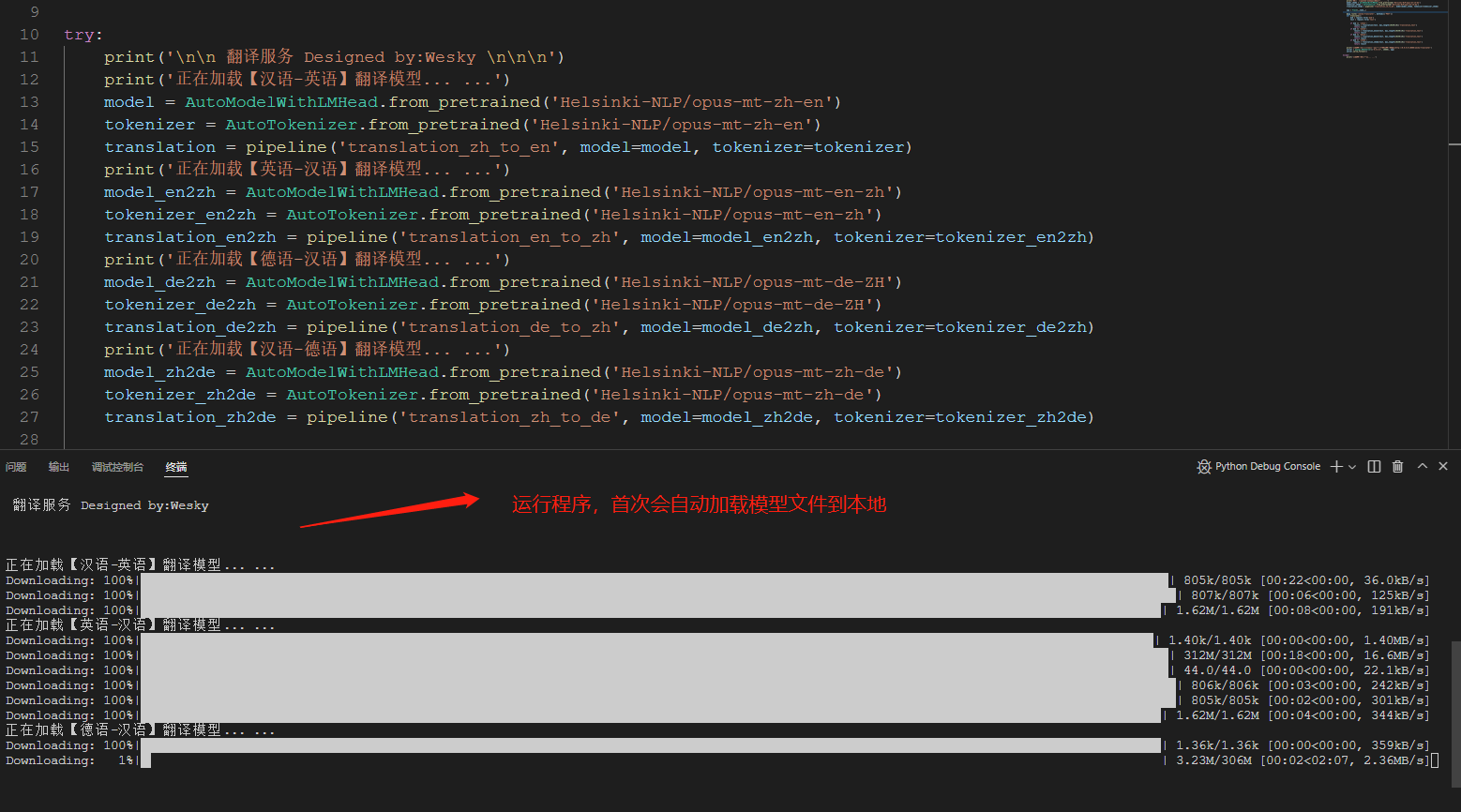
15、 模型加载完毕,启动服务。此处0.0.0.0代表本机ip都可以被访问,我们正常使用时候,本机就127.0.0.1即可;如果是局域网或者外网,那就提供真实IP即可。
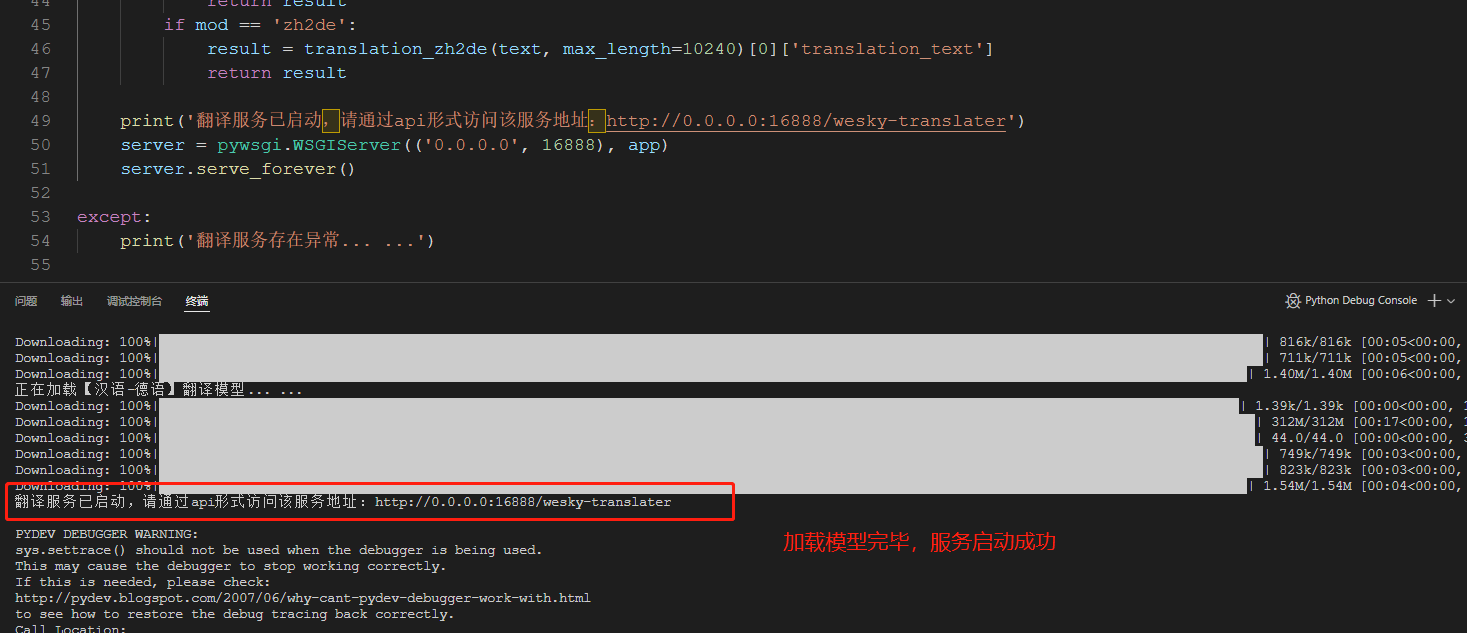
16、下载的模型,会自动下载到当前用户文件夹下,具体效果如下图所示。所以如果某个服务器没有外网,也可以直接拷贝该.cache文件夹到指定服务器下面的某用户下,也可以被识别。
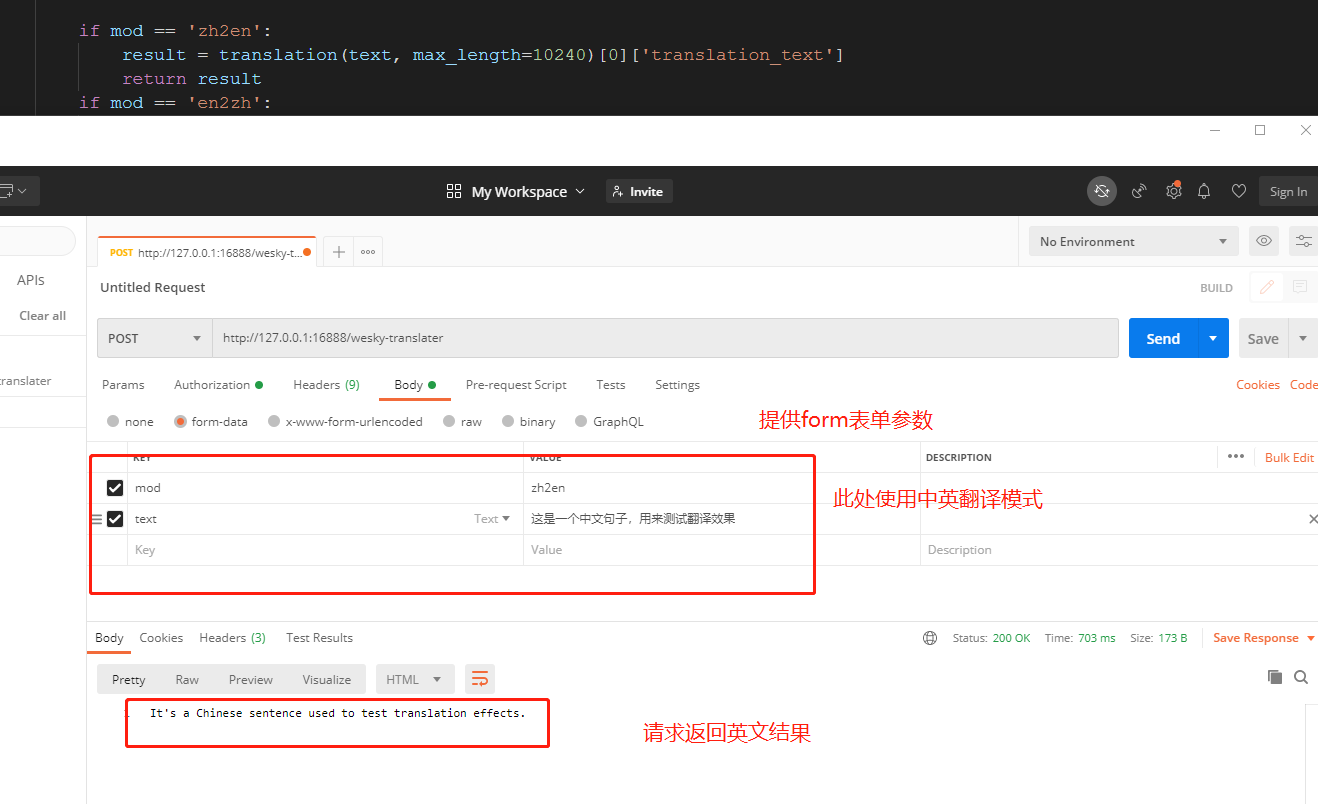
17、打开postman,做个简单的测试。可以看到,服务是可以被成功访问的,说明代码可以跑,问题不是很大。
18、换一种翻译模式再试一下:
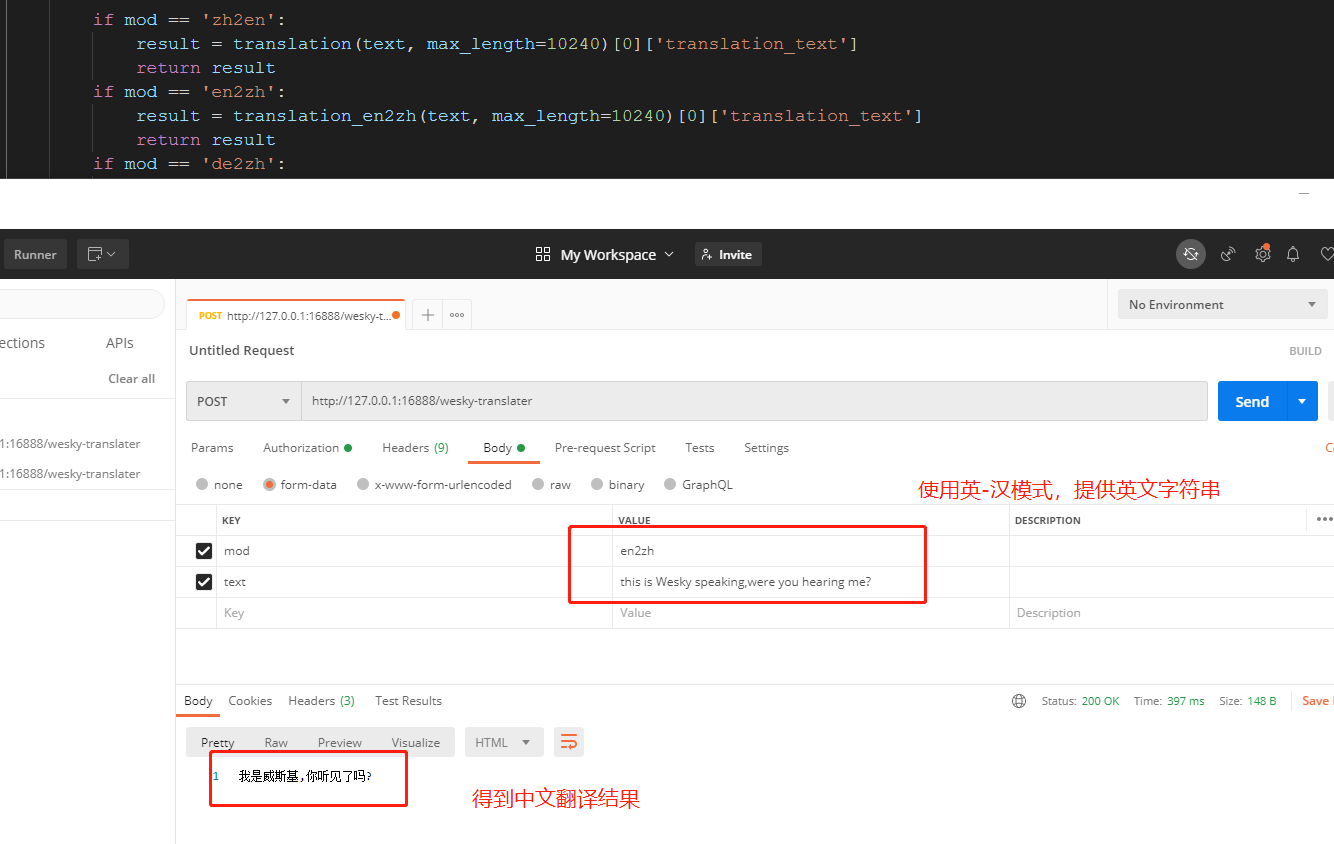
19、再试一试另类点的,看看效果:
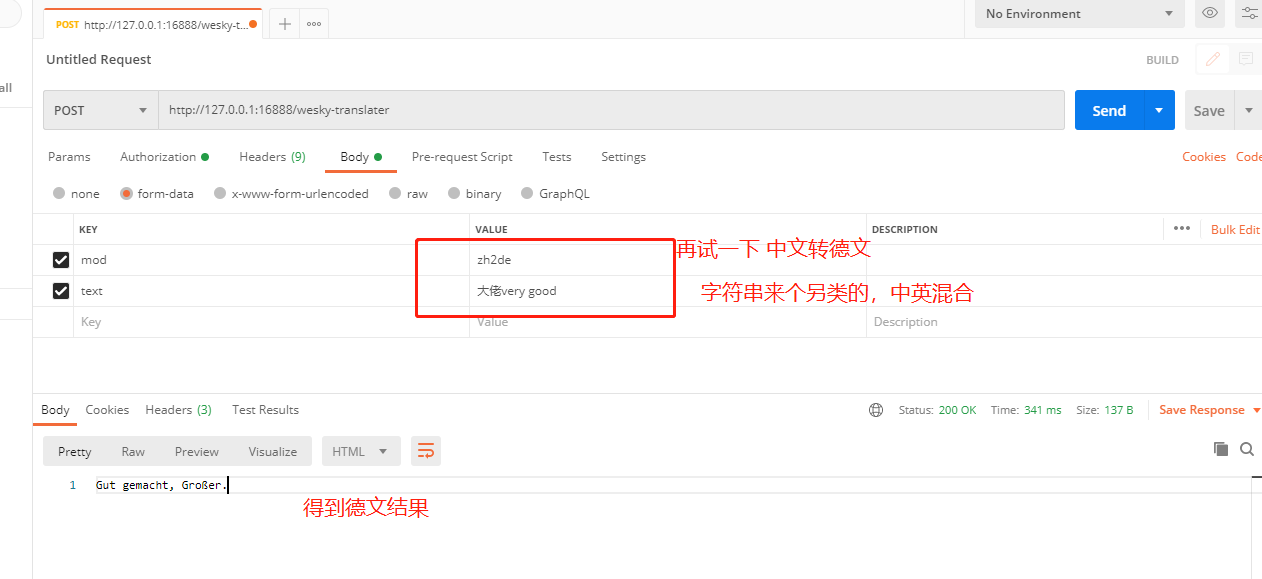
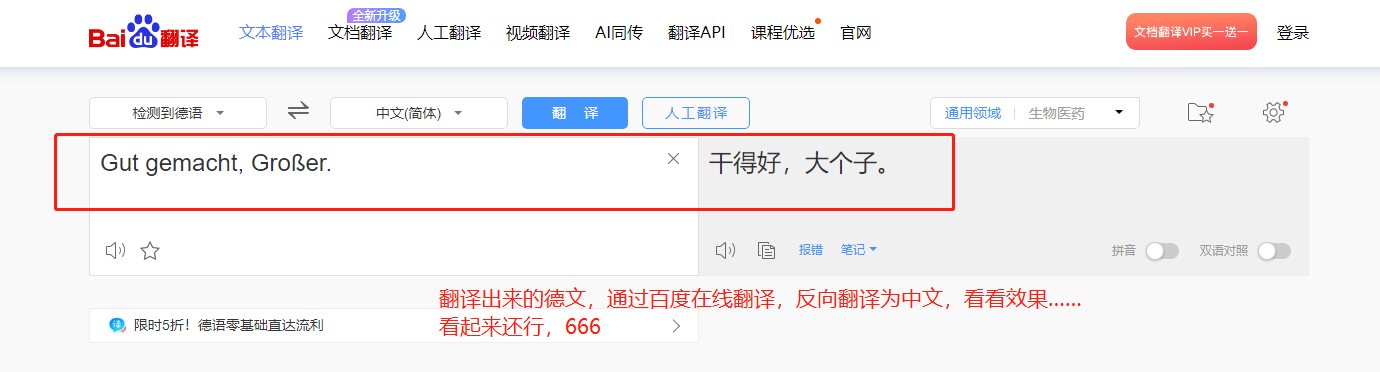
20、看不懂德文,把德文搞到百度在线翻译上面反翻译回来,看来语意好像差不多。
【中途插播,防止被恶意转载抹除个人出处使用】 该博客原创作者 Wesky,公众号:Dotnet Dancer 博客原地址:https://www.cnblogs.com/weskynet/p/16740041.html
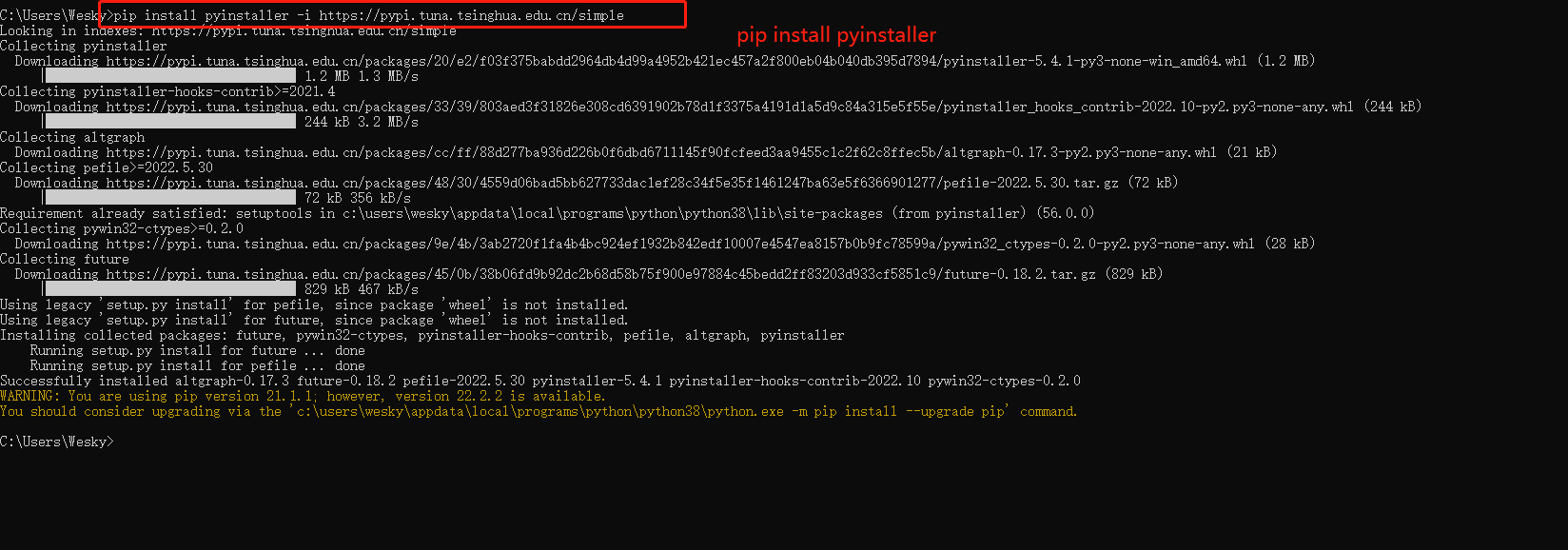
21、程序这样运行不是事儿,所以我们可以把它打包为exe程序来运行,这样就可以在不安装python环境的电脑也可以跑了。安装 pyinstaller:
22、在MyTranslate.py同文件夹下,新建一个py文件,名称不能改:hook-ctypes.macholib.py 该文件用于提供虚拟环境使用。
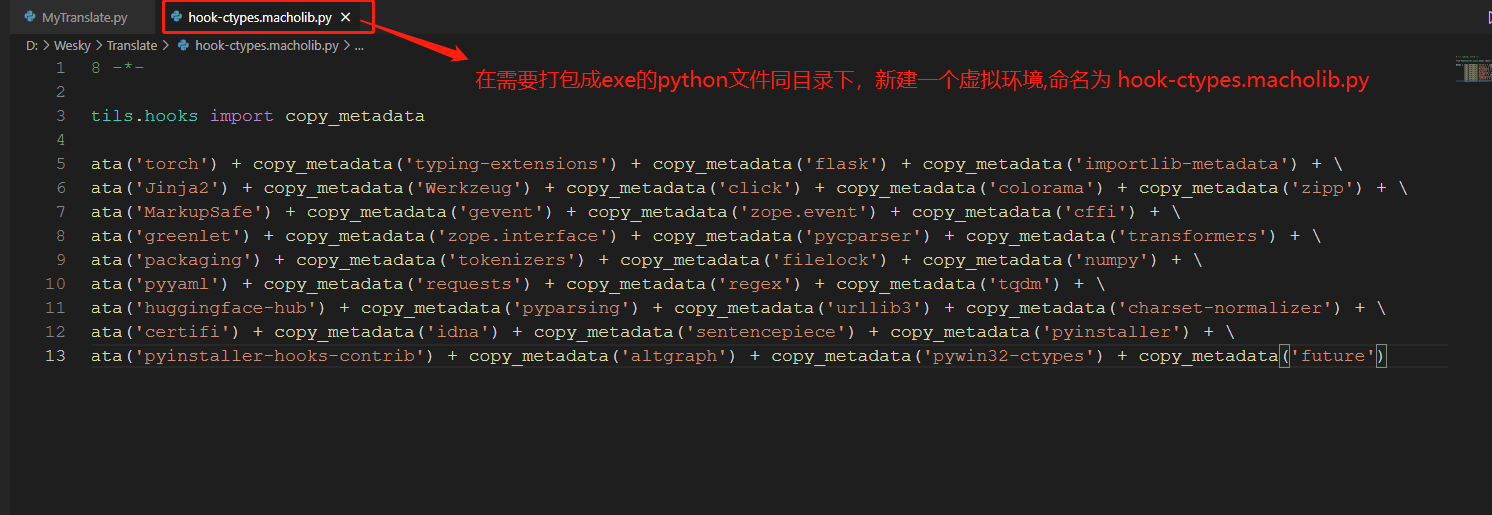
23、该文件下,需要导入所有可能用到的依赖的包。不然打包可能出错;或者打包完毕以后,运行可能出错。
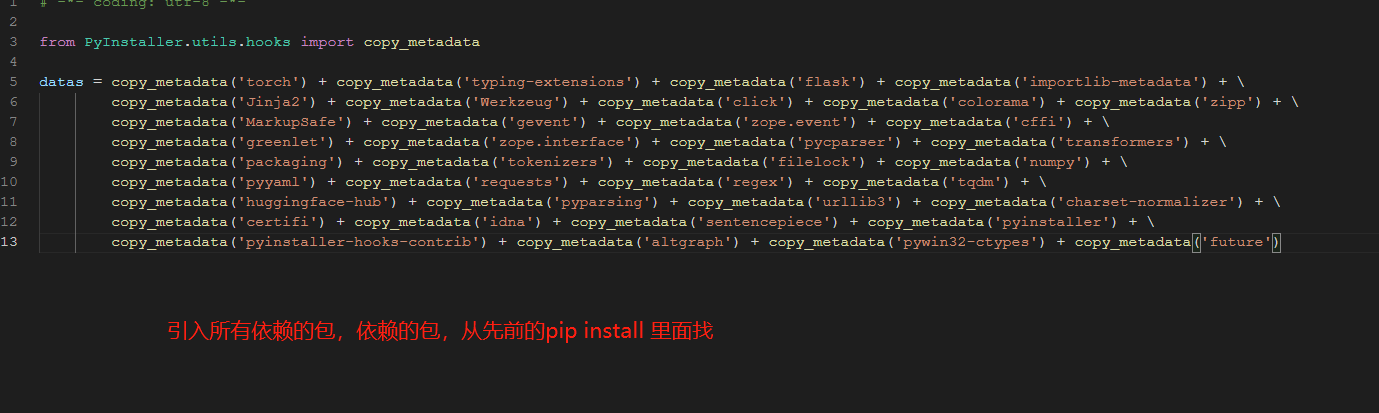
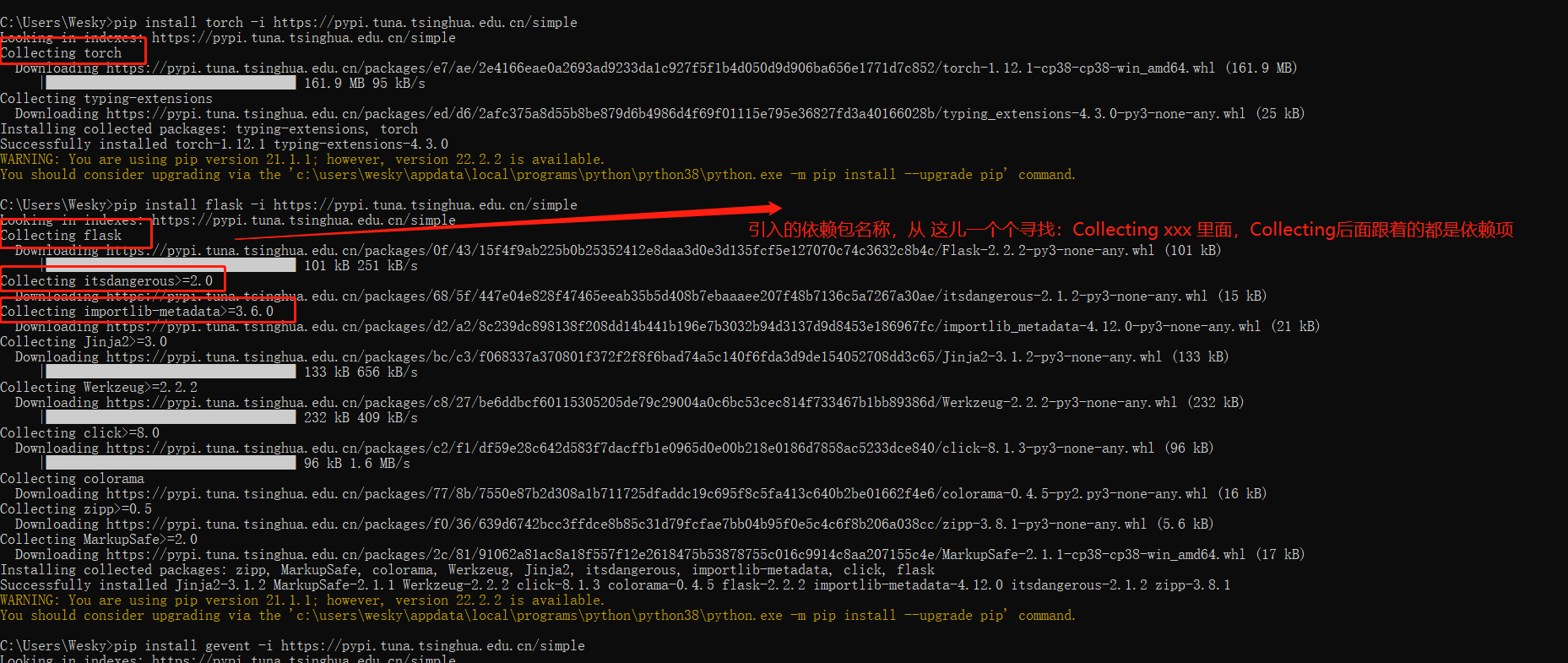
24、打包应用的内容,根据个人实际情况来选择,pip 下载时候,有一个 Collecting提示,提示后面就是安装的依赖包,不晓得哪些需要的,就全部搞进去,减少错误几率。
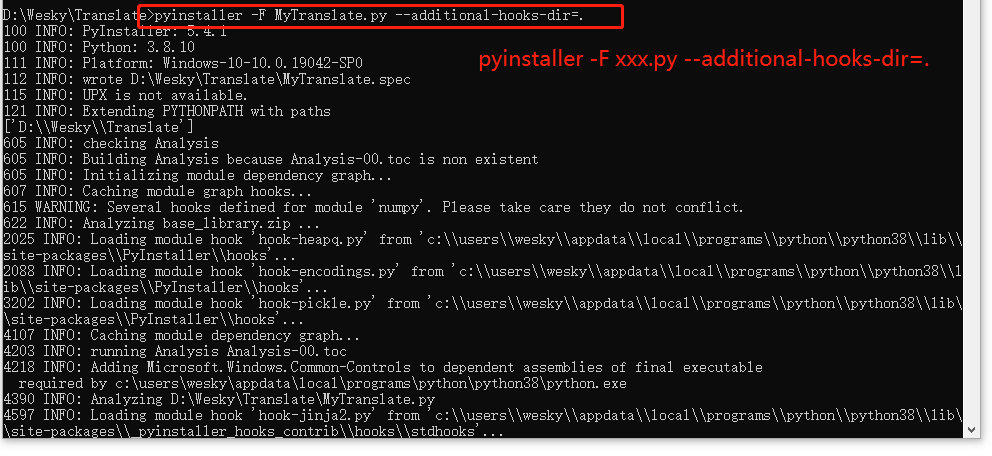
25、执行打包命名 pyinstaller -F xxx.py --additional-hooks-dir=. 如果不需要有控制台提示,可以加个 -w
26、打包安装成功了
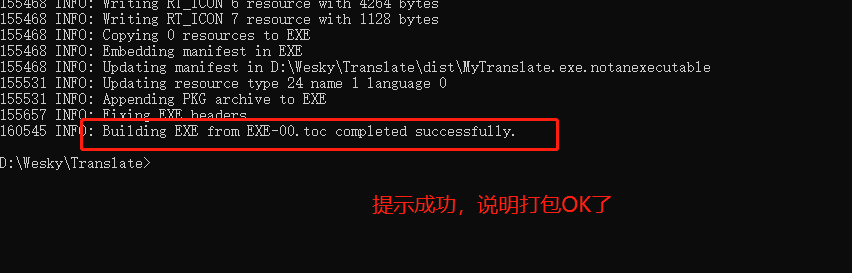
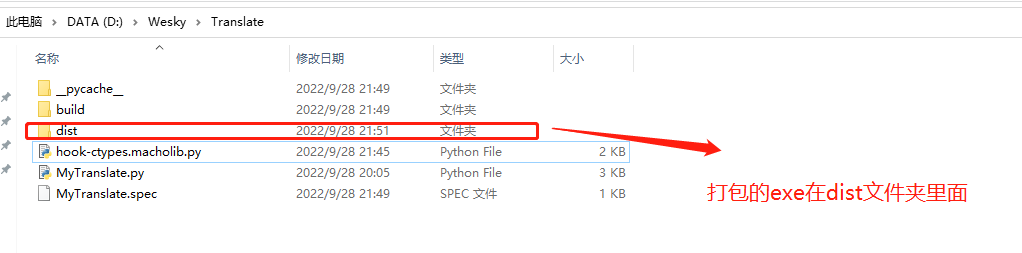
27、打包成功的exe文件,自动放在 dist文件夹下
28、生成的exe文件,如图。
29、直接运行走一波,看看效果。为了避免看不到错误提示,所以我在控制台内运行,如图
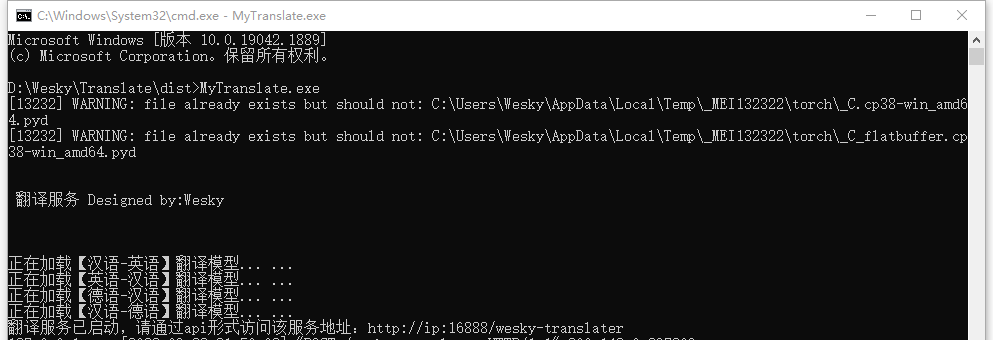
30、由于模型被下载过,所以第二次启动,不会重复下载模型。
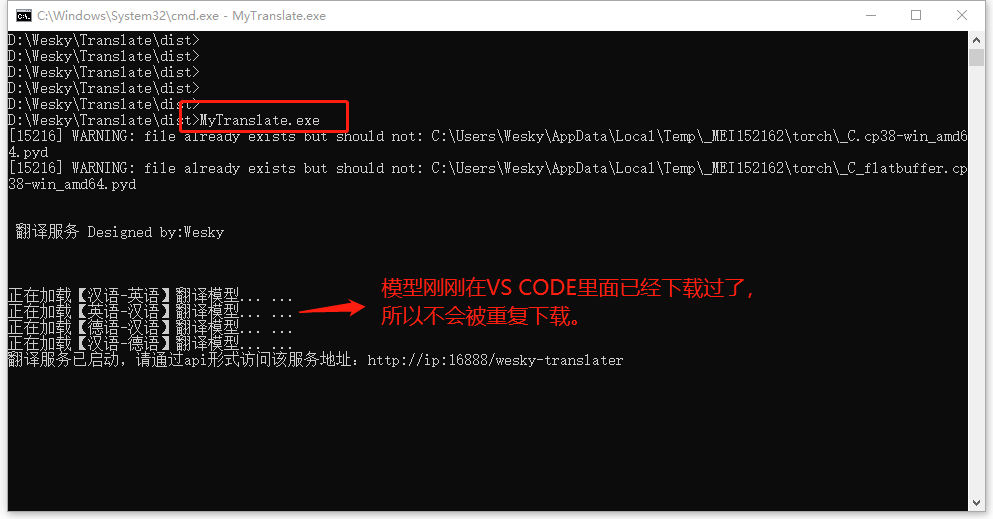
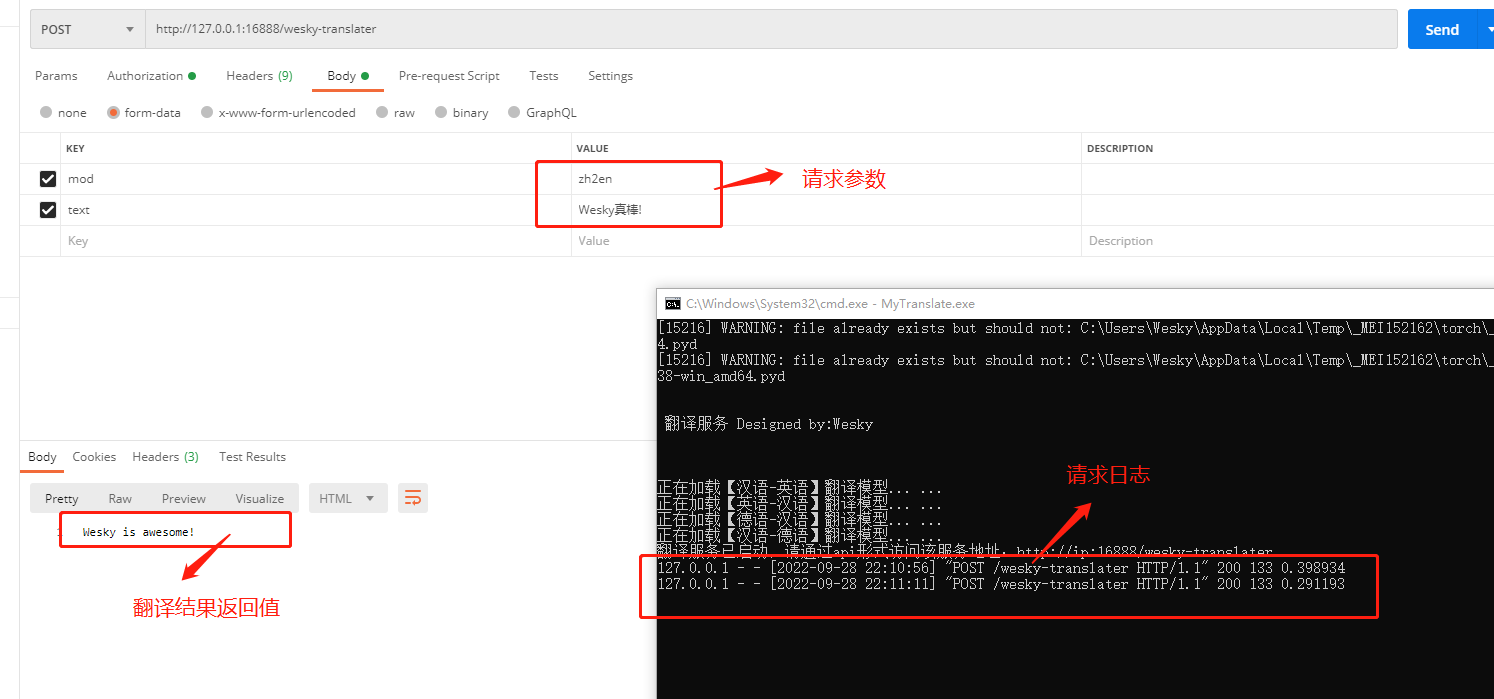
31、现在再用 Postman 走一波,看看效果。
32、直接运行的程序,难免被人不小心误操作给关闭了,所以我们还可以把他丢到Windows服务上面,这样服务器重启也不担心了。使用NSSM工具进行操作。如果想知道如何使用,也可以参考我的另一篇博客。博客地址:https://www.cnblogs.com/weskynet/p/14961565.html
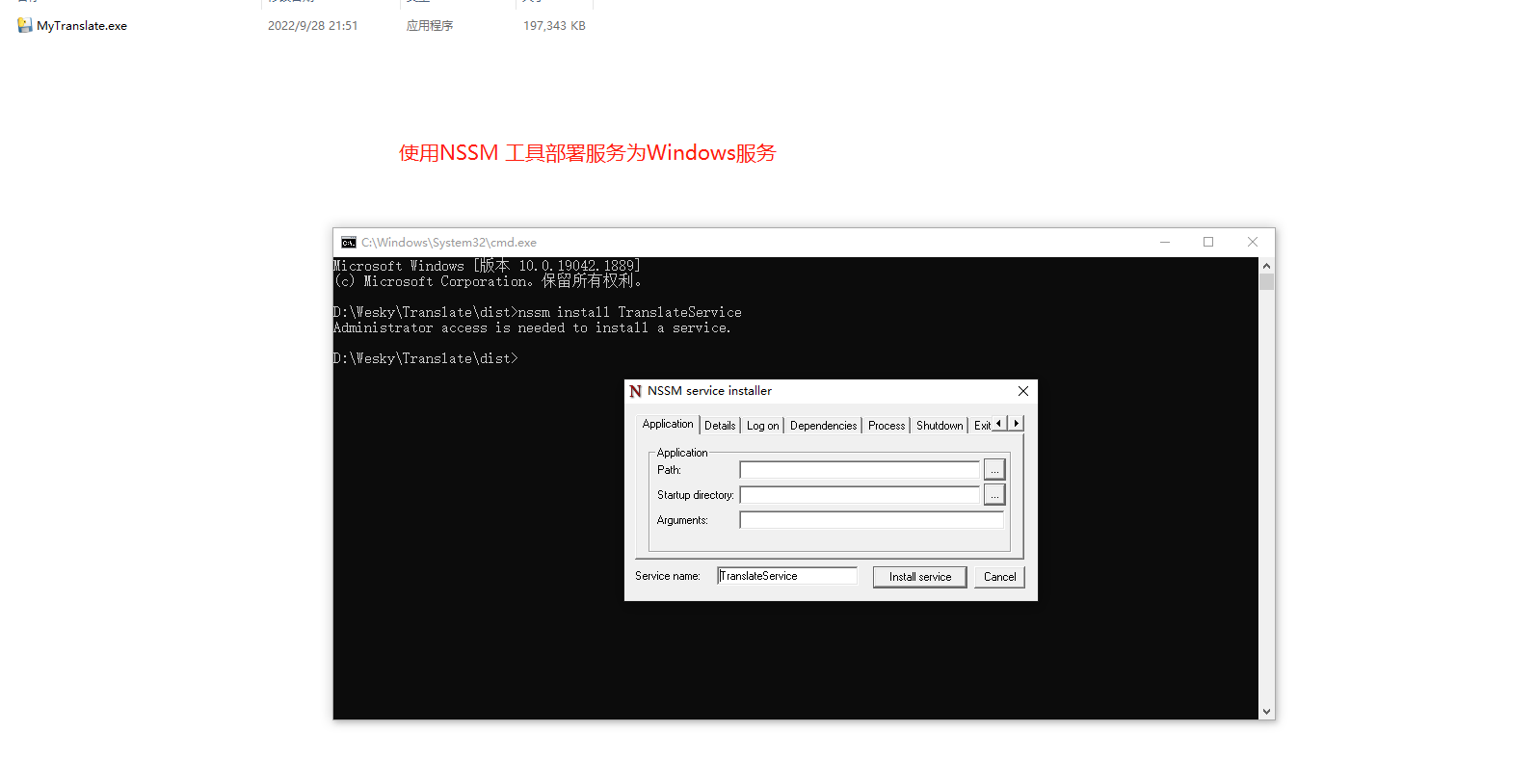
33、设置描述,备注为 离线翻译服务。安装为服务 TranslateService(名字可以随意)
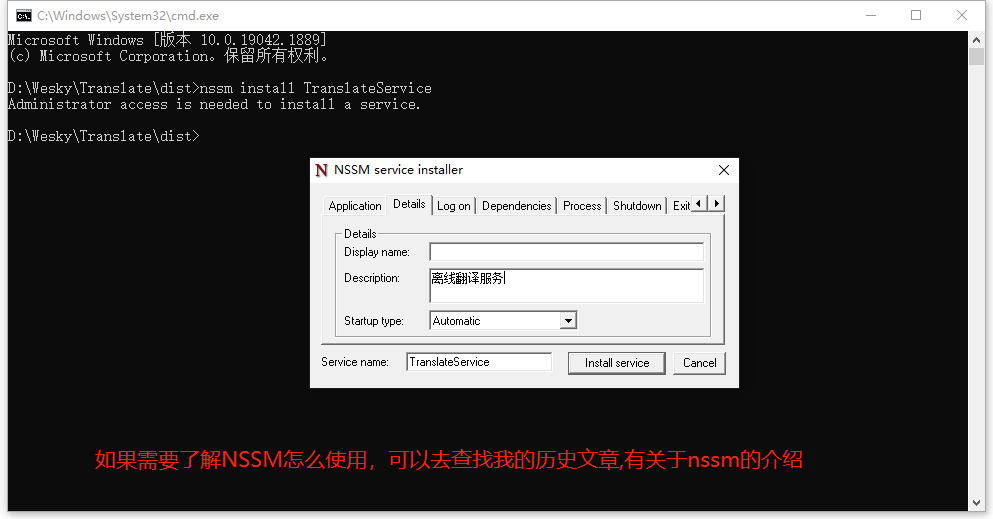
34、安装以后,可以看到已经生成一个对应的Windows服务了。
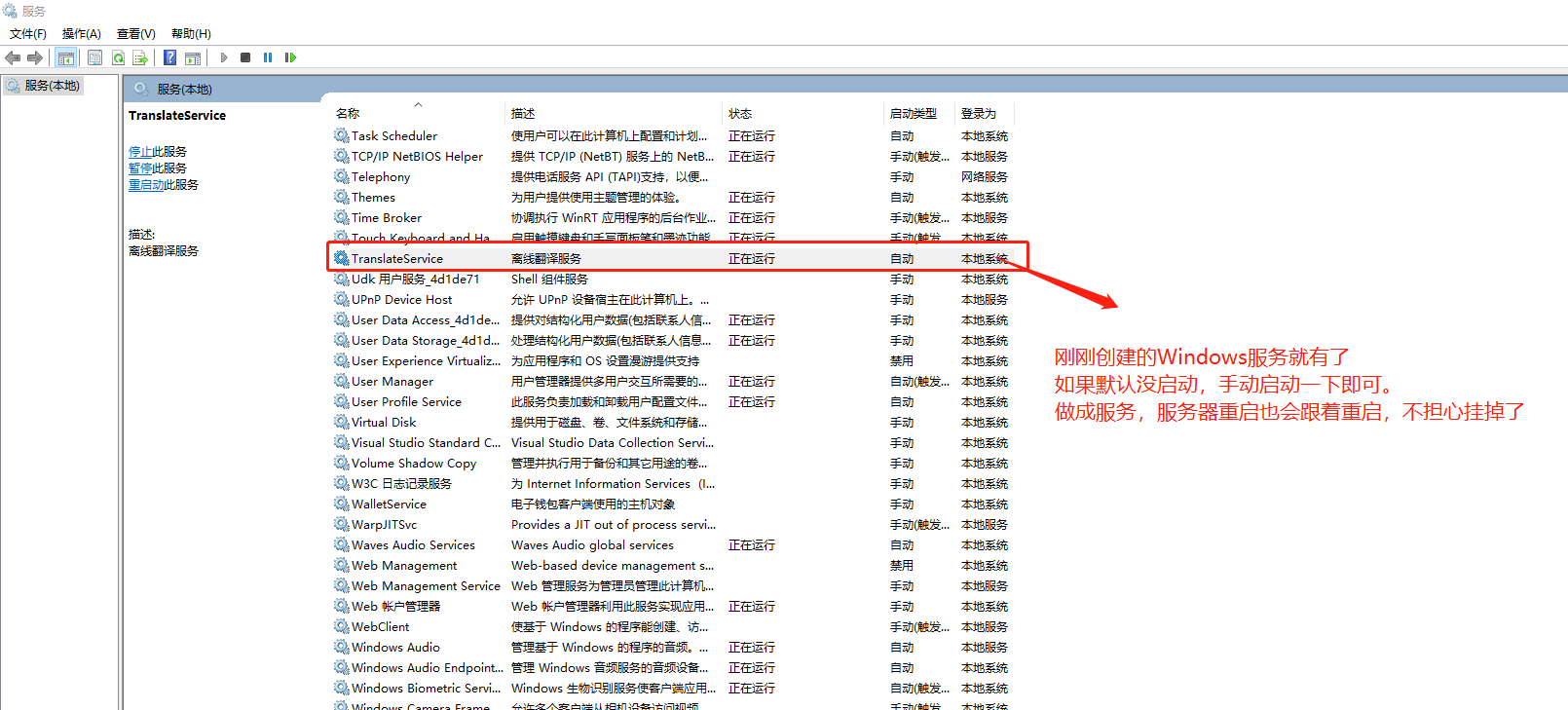
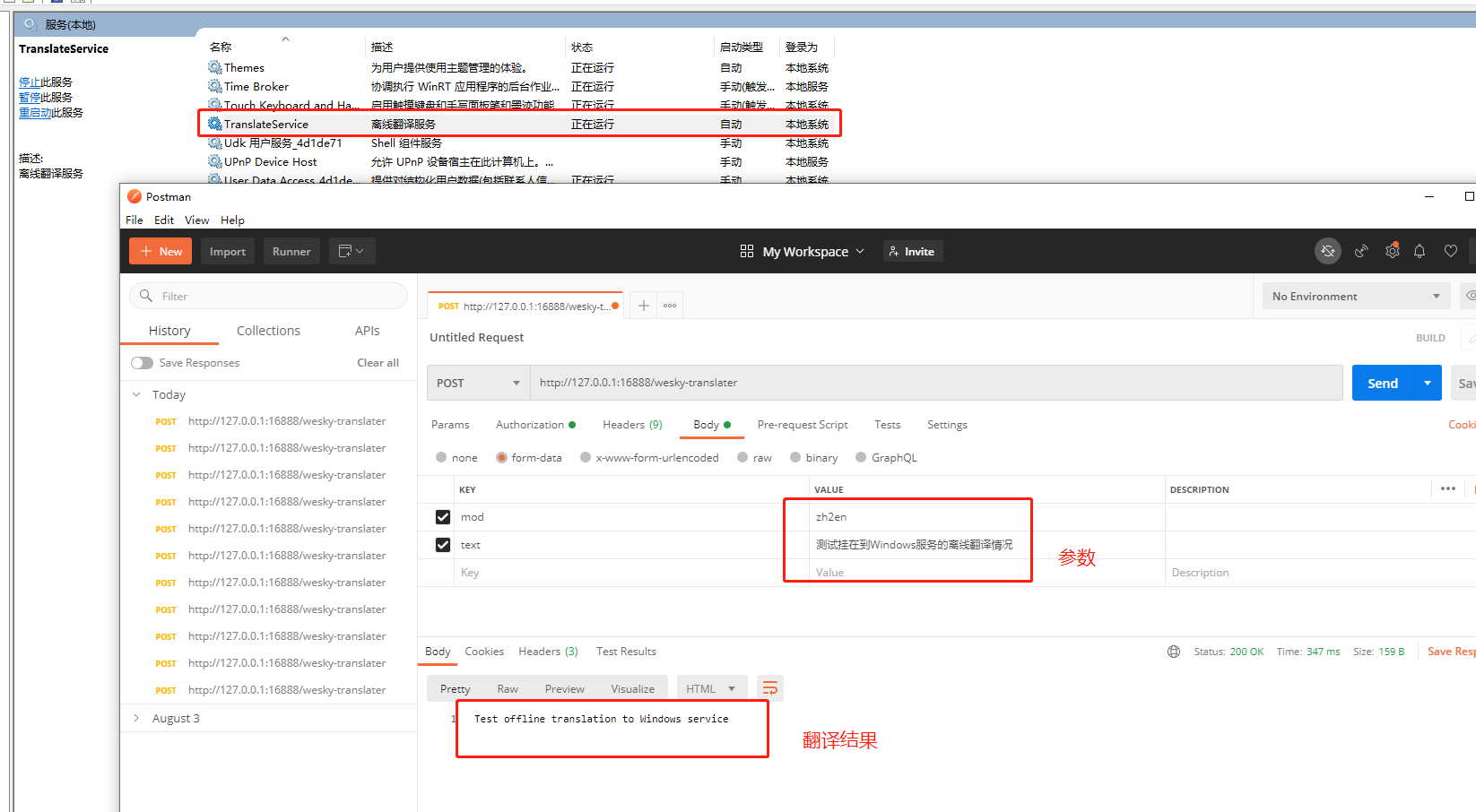
35、服务启动,可以等待一小会儿,加载模型要一丢丢时间。一小会儿以后,使用Postman进行测试一下,看看效果。
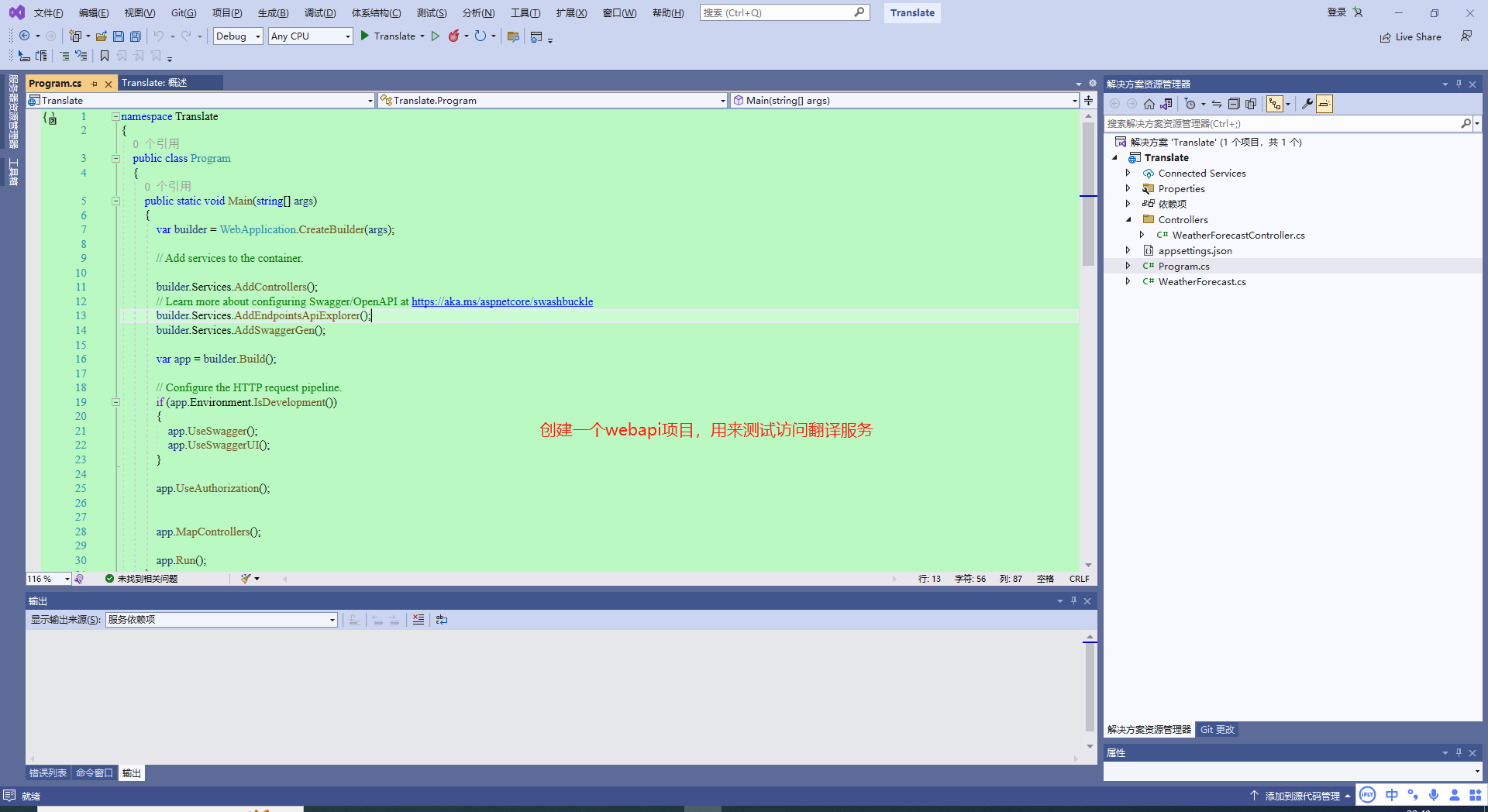
36、接下来,创建一个基于.NET的webapi程序,用来通过代码来访问翻译服务,看看能不能访问到。
37、创建一个控制器,搭建个基础模子先。
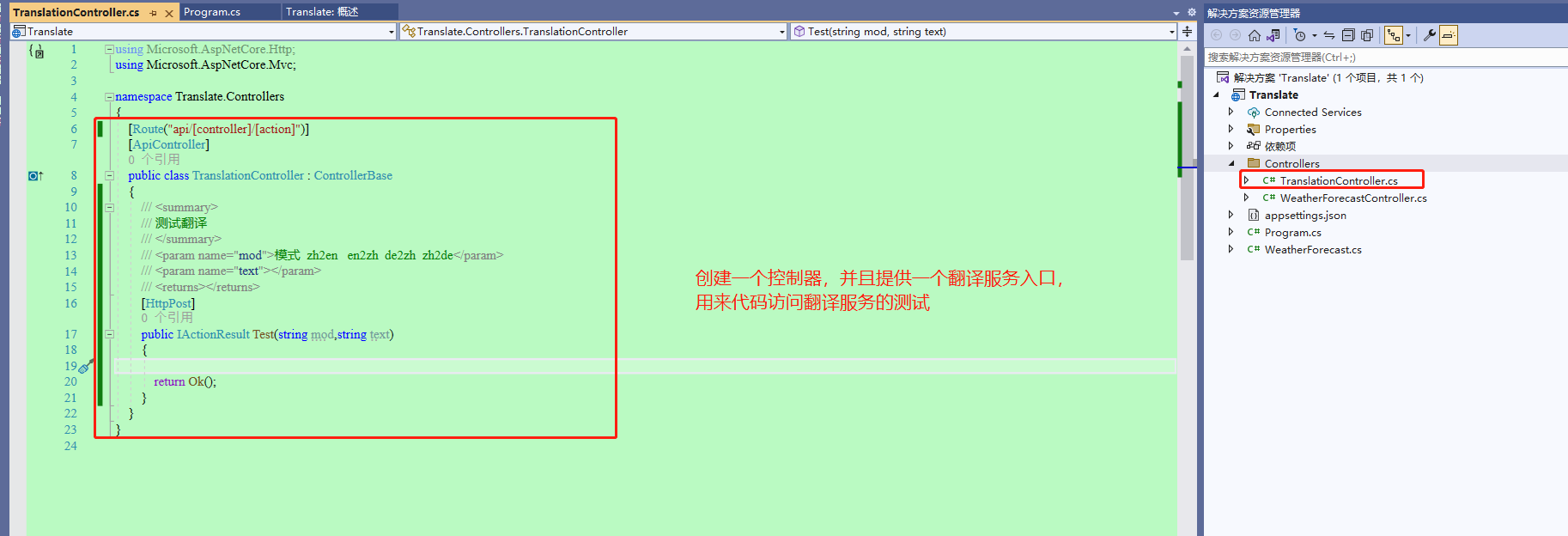
38、注入IHttpClientFactory(用来访问webapi使用的,实际上就是提供HttpClient)。然后写个简单的测试功能,直接看以下代码:
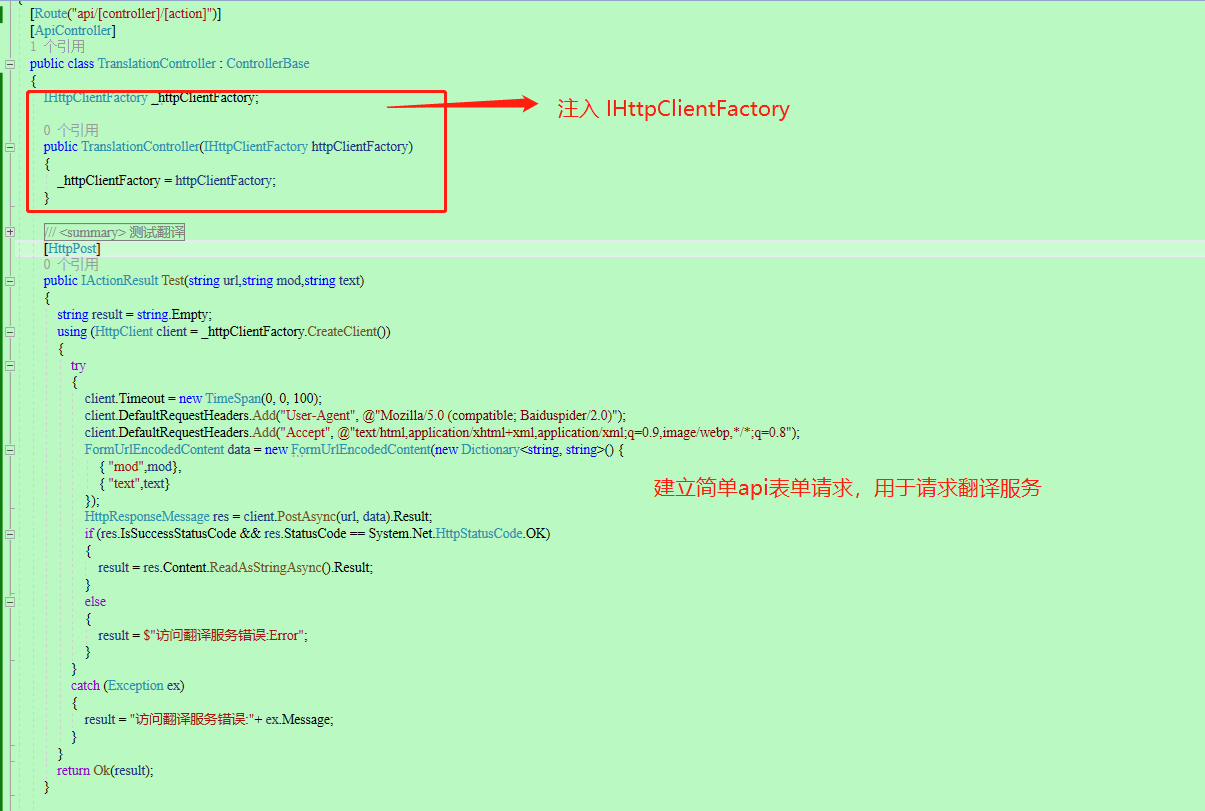
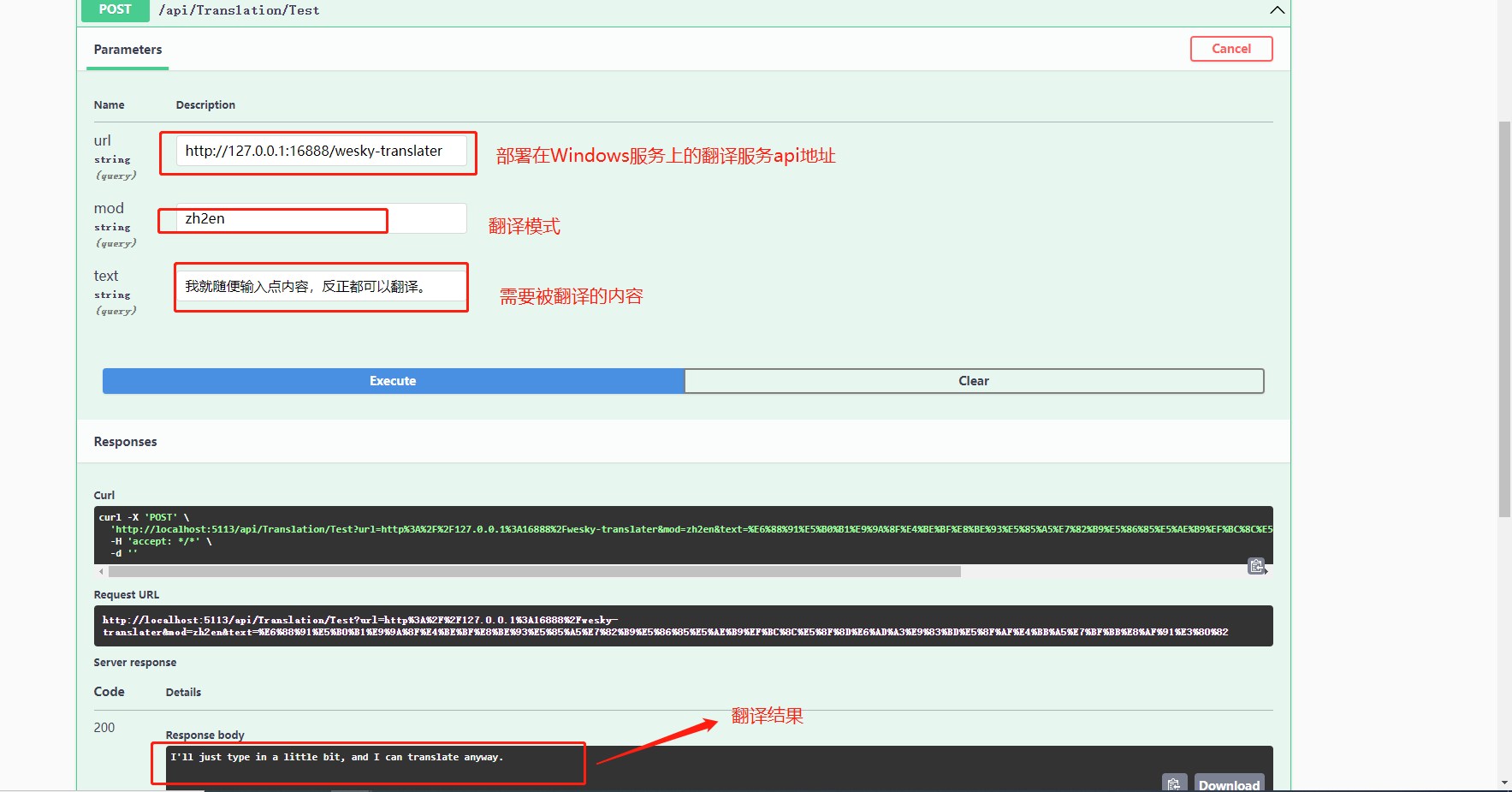
39、通过自带的swagger,走一波。输入有关参数,走一个看看,嘿,可以使用,bingo~
40、后记:如果需要源码的,可以微信搜索 Dotnet Dancer 或者扫描以下二维码,在公众号窗口发送 【离线翻译神器】,即可下载。















 1973
1973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









