






 本文详细介绍了如何在Python环境下从头开始构建和训练扩散模型,涉及环境配置、数据预处理、DDPM调度器的使用以及PytorchLightning模块的实现。通过一步步操作,读者将学会生成高质量的图像。
本文详细介绍了如何在Python环境下从头开始构建和训练扩散模型,涉及环境配置、数据预处理、DDPM调度器的使用以及PytorchLightning模块的实现。通过一步步操作,读者将学会生成高质量的图像。
目录
背景介绍
随着近两年AI绘画的爆红,Diffuser扩散模型一夜爆火。StableDiffusion为无数的内容创作者提供了创作动力。
那么,我们如何从0训练一个属于自己的扩散模型呢?我们将接下来逐步展开
环境准备
首先我们将安装以下Python库:
- Diffusers:来自Hugging Face,我们的扩散模型的原型模型将从这里进行拉取并加载。
- Pytorch:因为我们安装的Diffusers库依赖其运行,包括模型本身也是Pytorch模型,因此后期重训练也是对其必不可少。
- Datasets:来自Hugging Face,用于从Hugging Hub上拉取数据集。
- TorchVision:用于图像张量变换
- Numpy:用于执行张量和矩阵的类型转换。
安装包
首先我们利用conda创建一个虚拟环境:
conda create -n hugging
接下来为hugging安装python3
# 如果是Windows则不需要source activate
source activate && conda activate hugging
conda install python -y
之后我们接下来安装其他库:
pip install diffusers[torch] -i https://pypi.tuna.tsinghua.edu.cn.simple # 这个命令基本可以把diffsuers下属的依赖安装下来
pip install pytorch-lightning -i https://pypi.tuna.tsinghua.edu.cn/simple
提前准备
首先,我们需要将依赖的库导入进来:
import numpy as np
import torch
import torch.nn.functional as F
from matplotlib import pyplot as plt
from PIL import Image
import torchvision
接下来,我们将定义两个预处理函数:show_images()和make_grid()
def show_images(x):
"""给定一批图像,创建一个网格将其转换为PIL图像"""
x = x * 0.5 + 0.5 # 将(-1, 1)范围转换为(0, 1)
grid = torchvision.utils.make_grid(x) # 使用torchvision生成图像网格
# 使用.detach()解构网格
grid_im = grid.detach().cpu().permute(1, 2, 0).clip(0, 1) * 255
# 使用Image.fromarray()将Numpy矩阵加载为PIL图像
grid_im = Image.fromarray(np.array(grid_im).astype(np.uint8))
# 返回PIL图像
return grid_im
def make_grid(images,size=64):
"""给定一个PIL图像列表,将它们叠加成一行以便查看"""
# 将图像转换为RGB,由于我们要生成8个图像,因此为size*len(images),size
output_im = Image.new("RGB",(size*len(images),size))
for i,im in enumerate(images):
output_im.paste(im.resize((size,size)),(i*size,0))
return output_im
接下来,指定运行计算设备:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
数据制备
datasets提供了一个load_dataset()函数,概述接受两个常用参数:
- datasets_id(datasets_path):当该参数指定为datasets_id时,如(
<huggingface_username/repo>)时,load_datasets将调用git从Hugging Face Hub拉取数据,而如果指定的是:<path_to_datasets>,则此时可以从本地加载数据集。 - split:指定
load_datasets()函数从数据集中加载什么类型数据集。
接下来我们来加载蝴蝶图像数据集,每一张图为32x32x3的蝴蝶图像:
from datasets import load_dataset
dataset = load_dataset("huggan/smithsonian_butterflies_subset",split="train")
来自笔者的小贴士:如果你对自己家的网络
“超级自信”,你可以通过load_datasets管道去加载数据集,反之,我更建议您先安装git-lfs后,并使用git克隆该数据集。
接下来指定DataLoader小参:
batch_size = 64
image_size = 32
接下来我们定义预处理管道:
# 定义图像变换过程
preprocess = torchvision.transforms.Compose([
# 将输入的数据重塑为32x32x3
torchvision.transforms.Resize((image_size,image_size)),
# 进行随机水平翻转
torchvision.transforms.RandomHorizontalFlip(),
# 将输入转换为张量
torchvision.transforms.ToTensor(),
# 利用标准化映射到[-1,1]
torchvision.transforms.Normalize([0.5],[0.5])
])
定义一个适用于子集上的数据预处理函数:
def transForms(example):
# 先将图像数据转换为RGB图像,然后交给预处理管道
images = [preprocess(image.convert("RGB")) for image in example["image"]]
return {"images":images} #返回一个字典
将变换函数应用在数据集上:
dataset.set_transform(transForms)
创建DataLoader:
train_dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
)
数据预览
由于dataset类本身是个iterator(),因此我们本质上可以使用next(iter(iterator))的方式迭代加载完整的数据,事实也的确如此。还记得我们刚才在preprocess()函数中return的{'images':images}吗没所以接下来我们可以这样做:
# 加载8张图片
xb = next(iter(train_dataloader))["images"].to(device)[:8]
print("x shape:",xb.shape)
# 用我们之前的show_images()函数加载这组图像,并重塑为64*64
# 使用近似值填充方法
show_images(xb).resize((8 * 64, 64),resample=Image.NEAREST)
Jupyter输出如下:
x shape: torch.Size([8,3,32,32])

什么是噪声调度器?
我们知道:扩散模型本质上是在模拟物理意义上的扩散现象,那么在扩散的过程中一定要不断的添加噪声。好比向一杯干净的水中滴下一滴墨水,并还原墨水在水中扩散的过程。
如果我们是一位经验老道的实验人团,我们自然知道应该如何滴入墨水:一次滴几滴或者多少毫升?或者说要加入多少滴或者多长时间的墨水?
这个时候我们就需要一本“实验操作手册”或者一个能自动帮我们添加墨水的机器,那就是:噪声调度器。
噪声调度器的工作原理
噪声调度器可以十分精确地在每一个时间不上加入含有指定权重的噪声:
q
(
x
t
∣
x
t
−
1
)
=
N
(
X
t
;
1
−
β
t
X
t
−
1
,
β
t
I
)
q
(
x
1
:
t
∣
x
0
)
=
∏
t
=
1
T
q(x_t|x_{t-1}) = N(X_t;\sqrt{1-\beta_t}X_{t-1},\beta_tI)q(x_1:t|x_0) = \overset{T}{\prod \limits_{t=1}}
q(xt∣xt−1)=N(Xt;1−βtXt−1,βtI)q(x1:t∣x0)=t=1∏T
其中
1
−
β
t
\sqrt{1-\beta_t}
1−βt是噪声带有的系数,
x
t
x_t
xt是当前时间步下的观测样本,而
x
t
−
1
x_{t-1}
xt−1是之前的时间步上的观测样本。噪声调度器本质上是去
x
t
−
1
x_{t-1}
xt−1下的观测样本,将其附带一个
1
−
β
t
\sqrt{1-\beta_t}
1−βt的权重系数,并与一个
β
t
\beta_t
βt的系数进行相加。这样我们就从纯净的图像上得到了一个带噪声的图像。
利用DDPM调度器为图像“填噪”
接下来,我们将利用Diffusers中自带的DDPMScheduler()调度器来创建一个基于DDPM算法的噪声调度器:
noise_scheduler = DDPMScheduler(
num_train_timesteps=1000
)
由于我们指定了调度要执行1000个时间步,因此我们需要创建一个[0,999]的线性插值矩阵,来代表我们的时间步:
timesteps = torch.linspace(0,999,8).long().to(device)
同样的我们要创建一个与采样数据集大小相同的噪声矩阵:
noise = torch.randn_like(xb) # 生成[0,1]满足正态分布的噪声
使用.add_noise()将噪声添加到图像上:
noisy_xb = noise_scheduler.add_noise(
xb,noise,timesteps
)
print("Noisy x shape:",noisy_xb.shape)
show_images(noisy_xb).resize((8 * 64, 64),resample=Image.NEAREST)
Jupyter输出如下:
Noisy x shape: torch.Size([8, 3, 32, 32])

模型构建
接下来我们将引入UNet这一经典跳跃连接模型进行我们的模型构建,首先先从diffusers中导入UNet2DModel类:
from diffusers import UNet2DModel
接下来定义一个属于我们自己的UNet模型:
model = UNet2DModel(
sample_size=image_size, # 输入图像的大小
in_channels= 3, # 输入图像的通道数
out_channels=3, # 输出图像的通道数
layers_per_block=2, # 每个UNet块中使用的ResNet层数
block_out_channels=(64,128,128,256), # 每个UNet块中的输出通道数
down_block_types=(
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # 在末尾部分使用采用注意力机制的下采样模块
"AttnDownBlock2D"
),
up_block_types=(
"AttnUpBlock2D", # 同理,在反向过程中使用代用注意力机制的上采样模块来模拟退化过程
"AttnUpBlock2D",
"UpBlock2D",
"UpBlock2D"
),
).to(device)
创建一个PytorchLightning模块
首先,导入pytorchlightning:
import pytorch_lightning as pl
这里我们不需要使用pl.seed_everything()来设置随机种子。
接着我们开始定我们的Lightning模块:
# 定义一个PyTorch Lightning模型
class LightningModel(pl.LightningModule):
def __init__(self,model):
super().__init__()
self.model = model.to(device)
self.noise_scheduler = DDPMScheduler(
num_train_timesteps=1000,
#使用beta_schedule加载预制调度策略
beta_schedule="squaredcos_cap_v2"
)
self.loss_method = torch.nn.functional.mse_loss
self.loss_metrics= []
#使用AdamW优化器而非Adam
self.optimizer = torch.optim.AdamW(
self.model.parameters(),
lr=4e-4,
)
self.loss = None
def training_step(self,batch,batch_idx):
# 从批次中读取图像
clean_images = batch["images"].to(device)
# 生成噪声
noise = torch.randn(clean_images.shape).to(device)
# 生成与bs相同、[0,调度器步数]的时间步向量
# 切记要转换为long类型
timesteps = torch.randint(
0,noise_scheduler.num_train_timesteps,(clean_images.shape[0],)
).to(device).long()
# 添加噪声
noisy_images = noise_scheduler.add_noise(
clean_images,noise,timesteps
)
# 从模型中预测
noise_pred = model(noisy_images,timesteps,return_dict=False)[0]
self.loss = self.loss_method(noise_pred,noise)
self.loss.backward(self.loss)
self.loss_metrics.append(self.loss.item())
self.optimizer.step()
self.optimizer.zero_grad()
def configure_optimizers(self):
return self.optimizer
def plot_loss(self):
plt.plot(self.loss_metrics)
plt.xlabel("Step")
plt.ylabel("Loss")
plt.show()
创建Pytorch Ligtning Trainer训练器对象
想要训练一个Pytorch Lightning模型,我们需要使用一个Pytorch Lightning Trainer训练器对象来进行训练:
# 创建一个PyTorch Lightning Trainer
trainer = pl.Trainer(
accumulate_grad_batches=5, # 指定训练器每5个batch记录更新一次提取信息
max_epochs=50 # 设置训练器最大的迭代菜蔬
)
Jupyter输出如下:
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
其中GPU和TPU好理解,跟别是图形处理器和张量处理器。而IPU则代表ImageProcessingUnit,即图像处理单元。HPU则代表Hyper-heterogeneous Processing Unit,即代表超异构处理。
Pytorch Lightning这点十分省心,当您配备了不同的计算设备或多卡计算环境,Pytorch Lightning将自动帮您料理一切,剩下的只需交给时间,等待奇迹的诞生。
接下来,我们实例化我们模型后,将DataLoader和模型一并喂给我们的Trainer即可开始训练了:
# 训练模型
lightning_model = LightningModel(model)
trainer.fit(lightning_model,train_dataloader)
Jupyter输出如下:
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Paramas |
|---|---|---|
| model | UNet2DModel | 18.5M |
18.5 M Trainable params
0 Non-trainable params
18.5 M Total params
74.145 Total estimated model params size (MB)
可以看到,Pytorch Lightning自动为您列出了可用的GPU设备数量、参与训练的模型数量、参数大小、类型、名称等等。
最后通过50次迭代我们得到了如下的损失函数曲线:
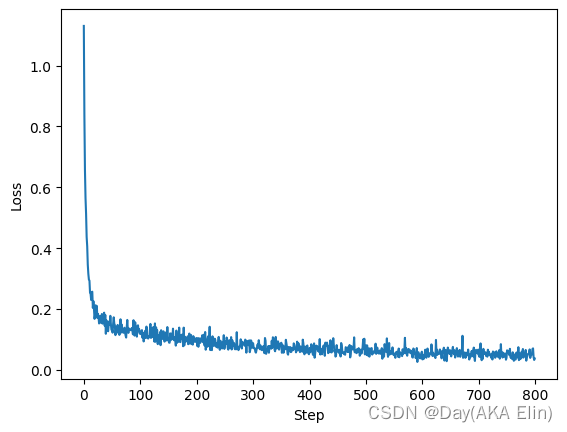
非常不错对吧,接下来就是见证奇迹的时刻了。
用模型生成一些新图像吧
现在,我们从lightning_model中把训练后的模型和调度器提出来:
model = lightning_model.model
scheduler = lightning_model.noise_scheduler
接下来重新创建一个DDPMPipeline管道:
# 从预训练管道中加载模型
butterfly_pipeline = DDPMPipeline(
unet=model,
scheduler=noise_scheduler,
)
接下来见证魔法:
output = butterfly_pipeline()
output.images[0]
由于管道最终输出的是PIL Image类型的图像,那么这意味着我们不需要使用诸如matplotlib或者numpy等手段显示图像:
好了,我们的蝴蝶生成出来了!
结语
希望通过本教程,你能够深刻理解扩散模型以及其噪声调度器的工作原理,也能基于此训练出自己的扩散模型。
祝你玩的开心~


















 2823
2823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











