






一、补充的专有名词:
1.detection pipeline:
—输出图中物体类别—— 图片输入—神经网络———多输出四个框(bx,by,bw,bh)用于表示bbox的信息
2.regression problem:回归问题。即根据一定的输入特征最后预测出一个值,如股票预测、成绩预测等。
3.overfitting:过拟合。训练集的loss很低,但测试集的loss很高。原因:参数过多或数据过少。解决办法:regularization(正则化)、dropout(失活)
4.regularization:正则化。对损失函数增强一个限制条件,保证其较高次的参数大小不能过大。我理解就是不让模拟出的函数过于复杂,以尽量低次幂的函数表示图形,这样就不会面面俱到,即函数不会穿过每一个点,但是会穿过大部分点,可以表示一个函数的趋势。
5.regularization parameter:正则化参数。其越大,惩罚(规范)力度越大,越能起到规范作用。但其越大,相当于把所有参数都最缩小了,极限情况为h0(x)=θ0,造成欠拟合。
正则化又分为L1正则化和L2正则化。
LI正则化

特点:对所有权重给予同样的惩罚。因此较小权重再被惩罚后就会变成0,惩罚后为0的参数不会出现到最后的模型,达到了模型稀疏化的效果。
L2正则化
特点:对绝对值大的权重给予很大的惩罚,对绝对值小的权重给予很小写惩罚
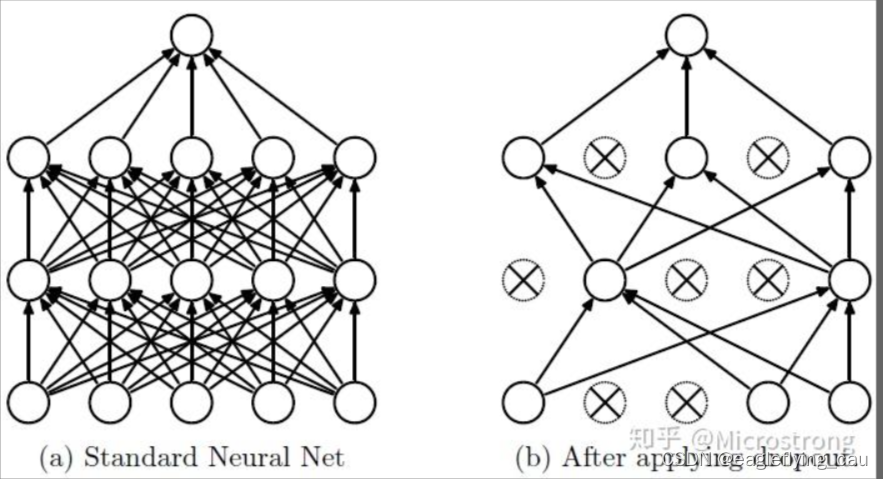
5.dropout:在前向传播中,以一定的概率让某些神经元停止工作,见下图。
流程1: 随机删减隐藏层中的部分神将元,注意输入与输出并不改变。
流程2:执行完前向传播后,把得到的损失结果加到修改后的网路(隐藏部分神经元后的网络)
流程3:重复上面两个步骤,即先回复恢复被删除的神经元,再随机删除一部分神经元
注意:这里的删除是将激活函数值设为0。
6.前向传播:输入层→隐藏层→输出层
7.反向传播:计算总误差→隐含层到输出层的权值更新→隐含层到隐含层的权值更新

8.激活函数:对输入增加非线性因素,输出变成非线性函数,让神经网络有可能学习到平滑的曲线来分割平面,而不是用复杂的线性函数去无限逼近平滑曲线去分割平面,能够更好地拟合目标函数。
9.Sigmod函数:
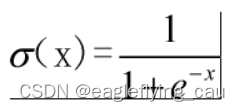

10.Non-maximal suppression:为了移除confidence较低的重复。
步骤:(1)对confidence进行排序(2)从最高分开始,若发现当前预测与之前预测class相同且IOU>0.5则保留之前预测跳过当前预测。(3)重复(2)直到检查完所有预测
1.Grid思想。这篇论文将预测的图片划分成S*S个grid,每个grid有B个Bounding boxes,每个Bounding box有5+C个信息,5分别是x,y,w,h,box cofidence score,C为C类条件概率。注:class confidence score=box confidence score*conditional class probability。(一些数学概念如下图所示,截的知乎大佬的图)

2.网络结构:24个卷积层,2个全连接层(最后),每一个卷积后都有一个池化
net = tf.pad(
images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),
name='pad_1')
net = slim.conv2d(
net, 64, 7, 2, padding='VALID', scope='conv_2')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3')
net = slim.conv2d(net, 192, 3, scope='conv_4')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5')
net = slim.conv2d(net, 128, 1, scope='conv_6')
net = slim.conv2d(net, 256, 3, scope='conv_7')
net = slim.conv2d(net, 256, 1, scope='conv_8')
net = slim.conv2d(net, 512, 3, scope='conv_9')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')
net = slim.conv2d(net, 256, 1, scope='conv_11')
net = slim.conv2d(net, 512, 3, scope='conv_12')
net = slim.conv2d(net, 256, 1, scope='conv_13')
net = slim.conv2d(net, 512, 3, scope='conv_14')
net = slim.conv2d(net, 256, 1, scope='conv_15')
net = slim.conv2d(net, 512, 3, scope='conv_16')
net = slim.conv2d(net, 256, 1, scope='conv_17')
net = slim.conv2d(net, 512, 3, scope='conv_18')
net = slim.conv2d(net, 512, 1, scope='conv_19')
net = slim.conv2d(net, 1024, 3, scope='conv_20')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21')
net = slim.conv2d(net, 512, 1, scope='conv_22')
net = slim.conv2d(net, 1024, 3, scope='conv_23')
net = slim.conv2d(net, 512, 1, scope='conv_24')
net = slim.conv2d(net, 1024, 3, scope='conv_25')
net = slim.conv2d(net, 1024, 3, scope='conv_26')
net = tf.pad(
net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),
name='pad_27')
net = slim.conv2d(
net, 1024, 3, 2, padding='VALID', scope='conv_28')
net = slim.conv2d(net, 1024, 3, scope='conv_29')
net = slim.conv2d(net, 1024, 3, scope='conv_30')
net = tf.transpose(net, [0, 3, 1, 2], name='trans_31')
net = slim.flatten(net, scope='flat_32')
net = slim.fully_connected(net, 512, scope='fc_33')
net = slim.fully_connected(net, 4096, scope='fc_34')
net = slim.dropout(
net, keep_prob=keep_prob, is_training=is_training,
scope='dropout_35')
net = slim.fully_connected(
net, num_outputs, activation_fn=None, scope='fc_36')
3.损失函数:定位损失+分类损失+confidence损失
1.分类损失

2.定位损失

3.Cofidence损失
(1)当检测到目标时

(2)当没检测到目标时

大多数box是不包含目标的,为了弥补类不平衡的问题,为了解决这个问题,引入了λnoobj(默认为0.5)
3.Non-maximal suppression:NMS,非极大值抑制
步骤:(1)对confidence进行排序(2)从最高分开始,若发现当前预测与之前预测class相同且IOU>0.5则保留之前预测跳过当前预测。(3)重复(2)直到检查完所有预测
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









