







 本文深入剖析MapReduce的工作流程,从MapTask的输入处理、Shuffle阶段、ReduceTask的输入与输出,到Yarn的资源分配与任务调度。详细讲解了InputSplit、RecordReader、Mapper、Partitioner、Combiner、Shuffle和Reduce过程,以及自定义InputFormat、OutputFormat等关键组件。通过对MapReduce的深入理解,有助于优化Job执行效率。
本文深入剖析MapReduce的工作流程,从MapTask的输入处理、Shuffle阶段、ReduceTask的输入与输出,到Yarn的资源分配与任务调度。详细讲解了InputSplit、RecordReader、Mapper、Partitioner、Combiner、Shuffle和Reduce过程,以及自定义InputFormat、OutputFormat等关键组件。通过对MapReduce的深入理解,有助于优化Job执行效率。
写在前面的话
MapReduce作为hadoop的编程框架,是工程师最常接触的部分,也是除去了网络环境和集群配 置之外对整个Job执行效率影响很大的部分,所以很有必要深入了解整个过程。本文写作的目的在于使得读者对整个MapReduce过程有比较细致的了解,当自己需要定制MapReduce行为时,知道该重写 哪些类和方法。在写作时,我贴了部分认为重要的源码和接口,并跟着自己的理解,对于某些内容,结 合了自己在工作中遇到的问题,给出了实践参考。
总体概览
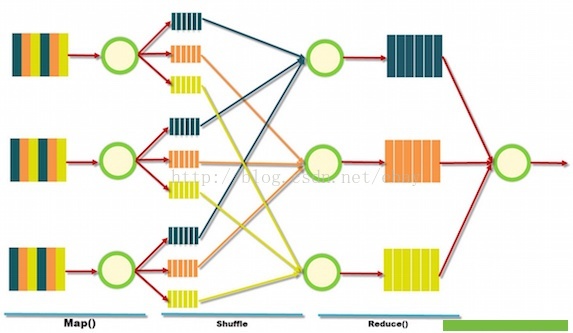
[本图摘自http://blog.sqlauthority.com/]
比较High Level的来看,整个MapReduce过程分为三步:· Map:读取输入,做初步的处理,输出形式的中间结果· Shuffle:按照key对中间结果进行排序聚合,输出给reduce线程·Reduce:对相同key的输入进行最终的处理,并将结果写入到文件中。
用经典的WordCount例子来简单说明一下上面的过程。假设我们现在要做的是统计一个文本中单词的个数,我们将文件切分成几个部分,然后创建多个Map线程,处理这些输入,输出的中间结果是的形式,shuffle过程将同样Key的元组,也就是word相同的,分配到同样的reduce线程中,reduce线程 汇总同一个word的元组个数,最终输出。
我这么一说,你是不是感觉已经理解MapReduce了?差不多吧,但是理解与深入理解是1与10000 的差距,下面让我提几个细节方面的问题:
1. 原始数据是怎么切分的,又是以什么形式传递给Map线程的?
2. 有多少个map线程,怎样控制他们?
3. 输出写到磁盘的过程是怎样的?
4. 如果要保证同一个中间结果key交给同一个reduce,要不要排序?什么时候排序?
5. 满足什么条件的中间结果会调用一次reduce方法,满足什么条件的中间结果会交给一个reduce 线程?
6. 有多少reduce线程,怎样控制他们? 7. 有多少输出文件? ...
是不是有很多问题都看不懂啦?没关系,下面我就详细讲解这个过程。
Yarn的资源分配与任务调度
之所以要讲解这一部分,是因为MapReduce过程牵扯到了框架本身的东西,我们得知道计算线程 是怎么来的,怎么没的。
Hadoop由1.0进化成2.0,变更还是很大的,1.0里整个job的资源分配,任务调度和监控管理都是 由一个JobTracker来做的,扩展性很差,2.0对整个过程重新设计了一下,我们重点来看2.0的内容。
一个Job要在集群中运行起来,需要几个条件,首先,运算资源,可能包括内存,cpu等,其次,得 有一个任务的调度算法,安排运行的先后顺序,最后,得知道工作进行的顺不顺利,并把情况及时的反馈给上级,以便及时的做出响应。下面分别说明。
下面我们首先看看1.0时代hadoop集群是怎么管理资源和调度任务的。
hadoop1.0的资源管理
hadoop1.0的资源管理
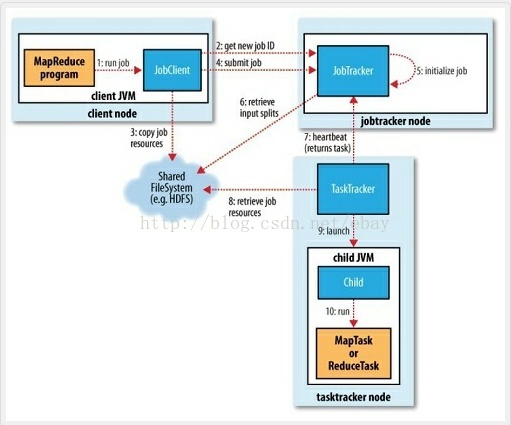
[本图来自百度百科的“MapReduce”词条]
对于一个集群来说,资源有很多维度,比如内存,CPU等,1.0时代将节点上的资源切成等份,使用 slot的概念来抽象,根据对资源占用情况的不同,又可细分为Map slot和reduceslot。slot代表一种运 行的能力,像许可证一样,MapTask只有获得了Map slot后才可以执行,ReduceTask同理。对于一个 节点,有多少slot是事先配置好的。
JobTracker和TaskTracker共同管理这些slot,其中JobTracker运行在NameNode上,负责资源 的分配和任务的调度,TaskTracker运行在Data Node上,负责所在节点上资源的监控和task的管理。 具体一点,当用户的任务提交给jobtracker之后,jobtracker根据任务的情况决定要启动多少MapTask 和ReduceTask,然后根据TaskTracker反馈的slot使用情况(以及其他的因素,比如根据数据的存储情 况),决定给哪几个TaskTracker分配多少个MapTask和多少个ReduceTask。接收到任务后,TaskTracker 负责启动JVM来运行这些Task,并把运行情况实时反馈给JobTracker。
注意,TaskTracker只有监控权,没有调度权,也就是它只能把运行情况反馈给JobTracker,在他这里有多少个Task,当task失败时,重启task之类的管理权限,都在JobTracker那里。JobTracker的 任务管理是Task级别的,也即JobTracker负责了集群资源的管理,job的调度,以及一个Job的每个Task 的调度与运行。
打个比方,JobTracker是一个极度专权的君王,TaskTracer是大臣,君王握有所有的权利,大臣们 被架空,君王说事情怎么做,底下的就得怎么做,大臣只管执行,并把进行情况告诉君王,如果事情搞砸了,大臣也不得擅作主张的重新做一遍,得上去请示君王,君王要么再给他一次机会,要么直接拖出 去砍了,换个人完成。
极度专权早晚累死,而且一个人的力量终归是有限的,这也是1.0时代很大的问题。所以新时代采取了全新的设计。Yarn的资源控制与任务调度
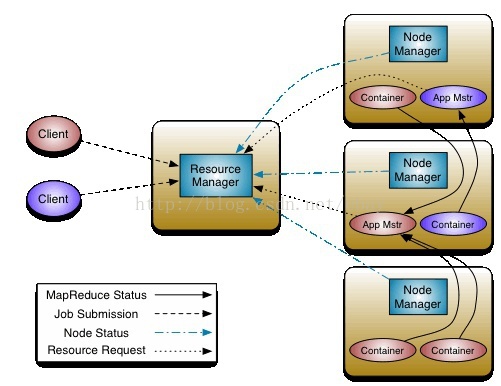
[本图摘自http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html]
Yarn用Container的概念来抽象资源,Container描述了自己的位置,自己拥有的CPU,内存等资 源的数量。Container跟任务完全独立了,是一个完全硬件的抽象。比1.0里使用计算时槽更加细粒度, 也更易于理解。
资源控制由ResourceManage(RM)和Node Manager(NM)两个角色参与,其中Node Manager 管理所在node上的container,并把资源的使用情况汇报给ResourceManager,Resource Manager 通过Node Manager返回的信息,掌握着整个集群的资源情况。为了便于管理,Hadoop集群的管理 员可以建立多个队列,每个队列配置一定量的资源,用户可以向一个或多个队列提交Job。作为集群的 用户,可以到50030端口查看集群的队列的分配和负载情况。

当一个用户提交了一个job给ResourceManager, Resource Manager 并不是直接衡量它所需的 资源并调度,而是下放给一个Application Master(AM)的角色,这个AM全权负责用户提交的这个Job,它会根据Job的情况向RM申请资源,RM告诉AM它可以使用的Container的信息,AM再将自己 Job的task放到这些Container中运行并监控。如果有失败的task,AM可以根据情况选择重启task。
有几个关键的点我列出来,以确保理解正确:
1. 集群的资源监控由RM与NM合作完成,任务调度与监控由RM与AM完成,结构更加清晰。
2. RM对任务的管理是Job级别的,即它只负责为整个Job分配资源,并交给AM去管理。RM得到了大大的解放。
3. 与TaskTracker相比,AM拥有更多的权利,它可以申请资源并全权负责task级别的运行情况。
4. 与TaskTracker相比,AM可以使用其他机器上的计算资源(即Container)。这些资源也不再有Map和Reduce的区别。
继续上面的例子。我用壮丁来比喻Container,壮丁有很多属性,比如家乡(location),力气( 内存),财产(CPU),君王(RM)通过锦衣卫(NM)来掌握各个地方(Node)壮丁的使用情况。 当有百姓提出一个要求(提交一个Job),比如兴修水利,君王不再事无巨细的过问这件事情,而是叫 一个合适的大臣(AM)过来,比如此例中的水利大臣,问他需要多少人,多少钱,然后衡量一下国力, 播一些壮丁给他用。水利大臣可以使用全国范围内的壮丁,对他们有绝对的领导权,让他们干嘛就得干 嘛。事情要么圆满完成,水利大臣给君王报喜,要么发现难度太大啊,尝试了好多办法都失败了(job尝 试次数到达一定数量),只好回去请罪。
君王遵循政务公开的原则,所有job的运行情况都可以通过50030端口查看:
好了,讲了这么一大通,我想关于Job怎么跑起来,task怎么来怎么没,应该有个概念了。用户将自 己的代码上传到集群的一个client Node上,运行代码,代码里会对自己的job进行配置,比如输入在 哪,有哪些依赖的jar包,输出写到哪,以什么格式写,然后提交给ResourceManager,ResourceManager 会在一个Node上启动ApplicationMaster负责用户的这个Job,AM申请资源,得到RM的批准和分配 后,在得到的Container里启动MapTask和ReduceTask,这两种task会调用我们编写的Mapper和Reducer等代码,完成任务。任务的运行情况可以通过web端口查看。
MapReduce 计算框架最重要的两个类是Mapper和Reducer,用户可以继承这两个类完成自己的 业务逻辑,下面以这两个类的输入输出为主线详细讲解整个过程。例子总是最容易被人理解的,所以讲解过程有看不懂的,可以回来查看这个简单的job。用户想使用MapReduce的过程统计一组文件中每 个单词出现的次数,与经典的WordCount不同的是,要求大写字母开头的单词写到一个文件里面,小写 的写到另一个文件中。
Mapper的输入

所谓源码之前,了无秘密,先上mapper的源码。
Mapper的源码
<span style="font-size:12px;">public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/*** The <code>Context</code> passed on to the {@link Mapper} implementations. */
public abstract class Contextimplements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
/*** Called once at the beginning of the task. */
protected void setup(Context context) throws IOException, InterruptedException {
// NOTHING
}
/*** Called once for each key/value pair in the input split. Most applications * should override this, but the default is the identity function.*/
@SuppressWarnings("unchecked")protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException { context.write((KEYOUT) key, (VALUEOUT) value);
}
/*** Called once at the end of the task. */
protected void cleanup(Context context) throws IOException, InterruptedException {
// NOTHING
}
/*** Expert users can override this method for more complete control over the * execution of the Mapper.* @param context* @throws IOException*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context); }
}
} </span><span style="font-size: 24px;">
</span>可以简单的说,Mapper的输入来自于Context。我们先看一下MapContext的实现:
public class MapContextImpl<KEYIN,VALUEIN,KEYOUT,VALUEOUT>extends TaskInputOutputContextImpl<KEYIN,VALUEIN,KEYOUT,VALUEOUT> implements MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
private RecordReader<KEYIN,VALUEIN> reader; private InputSplit split;
public MapContextImpl(Configuration conf, TaskAttemptID taskid, RecordReader<KEYIN,VALUEIN> reader, RecordWriter<KEYOUT,VALUEOUT> writer,
OutputCommitter committer, StatusReporter reporter, InputSplit split) {
super(conf, taskid, writer, committer, reporter); this.reader = reader;this.split = split;
}
/**
* Get the input split for this map.
*/
public InputSplit getInputSplit() { return split;
}
@Override
public KEYIN getCurrentKey() throws IOException, InterruptedException { return reader.getCurrentKey();
}
@Override
public VALUEIN getCurrentValue() throws IOException, InterruptedException { return reader.getCurrentValue();
}
@Override  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7425
7425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









