







在上一部分中,我们已经了解了自然语言处理的基本知识:自然语言处理NLP(1)——概述。
在这一部分中,我们将简要介绍NLP领域的基本模型——语言模型,我们还将对自然语言处理的基础——语料库的概念进行介绍。这些都是在学习自然语言处理之前所必备的知识。此外,我们默认大家有一定的信息论和概率论基础,在这里不对信息论和概率论知识进行赘述。
接下来,我们进入正题。
【一】语言模型
在这一部分中,我们讨论的语言模型主要是统计语言模型,除此之外,我们在今后的文章中还会对神经网络语言模型进行介绍。
所谓语言模型,就是利用数学的方法描述语言规律。而统计语言模型,就是用句子S出现的概率P(S)来刻画句子的合理性(而不进行语言学分析处理),这是统计自然语言处理的基础模型。
假设句子S=w1,w2,...,wn,其中,wi可以暂时看作句子中的第i个词(在后面会进行具体介绍)。由于自然语言是上下文相关的信息传递方式,可以很自然地讲句子S出现的概率定义如下:
P(S) = P(w1)P(w2|w1)...P(wn|w1,w2,...wn-1)
特别地,当i=1时,P(w1|w0) = P(w1),概率定义与条件概率相同。
在统计语言模型中,输入是句子S,输出是句子S的概率P(S),模型参数是各个P,即,P(wi|w1,w2,...,wi-1)。
wi被称为统计基元,可以是字、词、短语、词类等等,通常以“词”代替;
wi由w1,w2,...wi-1决定,由特定一组w1,w2,...wi-1构成的一个序列称为wi的历史。
说到这里,相信大家已经发现了一个很现实却很重要的问题:在这个模型中,参数的数量也太多了!
假设我们的统计基元个数为L(在这里可以将其理解为词汇表),那么一句话中的第i个基元就有L^(i-1)种不同的历史情况。我们必须考虑到这所有不同的历史情况下产生第i个基元的概率,于是,对于长度为m的句子,模型中有L^m个自由参数P(wm|w1…wm-1)。
这样算来,这会是一个很可怕的参数数量,假设L = 5000(词汇表中的词数有5000不过分吧),m = 3,模型中的自由参数就达到了1250亿!这还仅仅是对应着一个三个词的句子,而汉语中平均每句话中有22个词,这将是一个天文数字。
要解决这个问题,就要减少历史基元的个数,也就是减少决定wi的历史词的数目。
等等!看到这里,是不是有点熟悉,这不就是大名鼎鼎的马尔可夫链嘛!(不熟悉马尔可夫链的朋友们可以自行百度一下~)
没错,我们称其为马尔可夫方法:假设任意一个词wi出现的概率只与它前面的wi-1有关,将原模型简化为二元模型:
P(S) = P(w1)P(w2|w1)...P(wi|wi-1)...P(wn|wn-1)
在此基础上,提出n元文法(n-gram):一个词由它前面的n-1个词决定(注意,是n-1哦,不是n)。
一元文法(1-gram):n=1,P(wi|w1,w2,...,wi-1) = P(wi),出现在每一位上的基元wi独立于历史;
二元文法(2-gram):n=2,P(wi|w1,w2,...,wi-1) = P(wi|wi-1),1阶马尔可夫链;
三元文法(3-gram):n=3,P(wi|w1,w2,...,wi-1) = P(wi|wi-2,wi-1),2阶马尔可夫链;
……
以此类推。
理论上讲,n元文法中的n越大越好(越能保留句子词之间的相关性),但是正如上文所说,n越大也就意味着需要估计的参数越多。一般来讲,n=3用得相对较多,n=4的时候参数就已经太多了。
值得注意的是,即使采用n较大的高阶模型,也无法覆盖全部的语言现象(因为现阶段,对于人类来讲,语言依然是一个谜)。
了解了语言模型之后,问题来了:如何估计语言模型的参数呢?(用于计算P(S)的各个P(wi|wi-n+1,...,wi-1)值)
利用极大似然估计(Maximum Likelihood Evaluation,MLE)。
从个人理解的角度出发,我认为利用极大似然估计在语料中统计语言模型参数的过程,可以形象化地概括为两个字:数(三声)数(四声)。
极大似然估计的过程大致如下:
假设我们的语料库中只有三句话(语料库的概念将在后面进行介绍):
1. John read Moby Dick
2. Mary read a different book
3. She read a book by Cher
现在,我们想要估计2-gram模型中,‘John read a book’ 这句话出现的概率。
P(‘John read a book’ ) = P(John|<BOS>)P(read|John)P(a|read)P(book|a)P(<EOS>| book),其中<BOS>和<EOS>分别表示句子的开始符和结束符。
我们可以从语料中(1,2,3一共三句话)统计得到:
P(John|<BOS>) = 1/3,因为<BOS>出现了三次(每个句子的开始),后面接John的有一次——即,John出现在句首;
P(read|John) = 1/1,因为John出现了一次,后面接read的有一次;
P(a|read) = 2/3,因为read出现了3词,后面接a的有两次;
P(book|a) = 1/2,因为a出现了2次,后面接book的有一次;
P(<EOS>| book) = 1/2,因为book出现了2次,book出现在句子结尾(后面接<EOS>)的有1次。
因此,P(S) = 1/18。
通过这个小小的例子,我们可以发现,语言模型可以预测句子的下一个词(已知前面的词),也可以计算一句话出现的概率,决定哪一个词序列出现的概率大。
下面,我们再举一个例子:
还是上面的语料库,还是使用2-gram,我们想要求‘Cher read a book’的概率。
看起来没什么问题啊,按着上面的套路做就可以了啊,但是在实际计算的时候我们发现:P(Cher|<BOS>) = 0,Cher这个词根本就没有出现在句首过!
这也就意味着,无论后面几个概率值是多少,我们计算出来的整个句子出现的概率都是0。
这个问题被称为零概率问题,是由数据稀疏(匮乏)造成的。
那么遇到了这个问题,该如何解决呢?
进行数据平滑。
数据平滑的方法有很多种,在这里不一一进行赘述,有兴趣的朋友可以自行百度了解。
总之,数据平滑之后,不会出现上面例子中出现的零概率问题,我们就可以安安心心地用语言模型计算一句话出现的概率啦~
到这里,对语言模型的介绍就基本结束了,我们还剩下一些边边角角的问题需要解决:比如,如何评价语言模型。
目前,语言模型的评价一般有两种方法:
1.实用方法:通过查看该模型在实际应用(如机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观。
2.理论方法:为了评价语言模型,提出了一个“困惑度”的概念,方法如下:
平滑过后的n-gram模型句子的概率为(与语言模型中的描述相同):P(S) = P(w1)...P(wi|wi-n+1,...,wi-1)...
假设测试语料T由k个句子t1,t2,...,tk构成,那么整个测试集T的概率为:p(T) = P(t1)P(t2)...P(tk)
定义模型对于测试预料的交叉熵为:
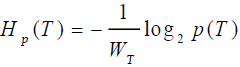
其中,分母项为测试语料T中的词数(可以理解为测试文本集的单词表)。
定义模型的困惑度为:
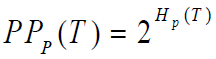
困惑度越低,模型评价越高。
在这里,多说几句题外话:
对于一个模型而言,最重要的部分有四个:输入、输出、参数、对应关系(函数)。
对于任何一个模型而言,把握住这四个基本要素,相信会帮助大家理解得更加透彻(特别是今后我们会提到的神经网络)。
【二】语料库(corpus)
语料库是什么?
语料库就是,存放在计算机里的原始语料文本 或 经过加工后带有语言学信息标注的语料文本。为了方便理解,我们可以将其看作一个数据库,我们从中提取语言数据,以便对其进行分析、处理。
语料库有三点特征:
1.语料库中存放的是在实际使用中真是出现过的语言材料。
2.语料库是以计算机为载体承载语言知识的基础资源,但并不等于语言知识。
3.真实语料需要经过分析、处理和加工,才能成为有用的资源。(这一点尤为重要,在NLP知识的学习中,需要对语言原材料进行一系列的处理才能够使用)
在这里,不对语料库进行系统的介绍,仅需要了解“我们可以从中提取语言数据来用”就可以啦~
如果有朋友对语料库的分类和现阶段一些著名的语料库感兴趣,可以自行百度了解~
现在,我们已经对统计语言模型和语料库有了基本的了解,在下一部分的内容中,我们将介绍神经网络语言模型和一些在NLP领域常用的基本的神经网络。
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
谢谢!














 1616
1616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









