










快速推进语音处理技术,助力算法的广泛应用
为促进语音处理技术的发展和应用,通义实验室正式开源 ClearerVoice-Studio —— 一个集成语音增强、语音分离和音视频说话人提取等功能的语音处理框架。该平台不仅提供了顶尖的预训练模型和算法,还吸引了众多开发者积极参与和体验,为语音技术的进步注入更多可能性。
在 ClearerVoice-Studio 平台中,我们融入了多种创新的语音处理算法,搭配经过精心调优的模型,旨在为用户提供卓越的语音处理体验。
🌟 ClearerVoice-Studio 的核心特色
-
预训练模型:内置高性能预训练模型,基于大规模高质量数据集优化,无需从零开始,开箱即用!
-
易用性:简洁直观的设计,支持灵活的推理与训练接口,轻松集成到您的项目中;
-
功能全面:融合多种高级算法,涵盖语音增强、分离与目标说话人提取等多种任务;
-
社区驱动:面向研究人员、开发者和爱好者,打造协作创新的开放平台,鼓励共同进步;
-
开源透明:所有模型、算法和代码公开,供全球开发者学习和使用;
-
实验验证:模型经过大规模数据集验证,效果稳定可靠。
💡 ClearerVoice-Studio 能为您做什么?
-
高效去除背景噪声,将嘈杂语音处理成高质量、清晰的语音信号;
-
从复杂音频混合中轻松分离目标语音,满足多种语音处理需求;
-
使用音视频结合的模型精确提取目标说话人的语音信号;
-
使用模型训练和调优工具进行模型效果打磨;
-
未来将陆续推出更多强大的语音处理功能,敬请期待!
📂 如何找到我们?
-
GitHub 仓库:ClearerVoice-Studio
-
在线体验 Demo:Hugging Face Space
背景
随着语音技术的普及,语音质量已成为人们关注的焦点。然而,环境噪声、混响、设备拾音等问题,常常使语音质量和可懂度大打折扣。
无论是录制清晰语音却因周围环境嘈杂充满噪声,还是在地铁、餐厅等喧闹场景中与人通话时不得不提高嗓音,这些场景都体现了语音处理技术的迫切需求。特别是在复杂的多人对话环境中,如何有效分离目标说话人的语音信号,避免其他干扰,一直是语音处理领域的难点和热点。
ClearerVoice-Studio 正是为了解决这些痛点而推出的。通过融合复数域深度学习算法,我们大幅提升了语音降噪和分离的性能,能够最大限度地消除背景噪声并保留语音清晰度,同时保持语音失真最小化。
核心模型与算法亮点
-
FRCRN 模型:在 2022 年 IEEE/INTER Speech DNS Challenge 中取得整体第二的优异成绩,展现出卓越的语音增强能力。
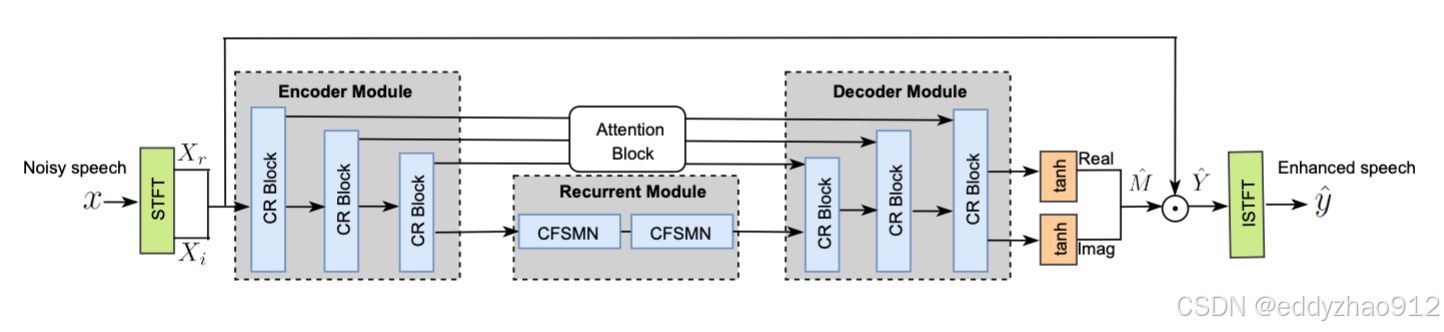
-
MossFormer 系列模型:在语音分离任务中表现卓越,首次超越 SepFormer,获得业内广泛认可。目前,MossFormer 框架已扩展至语音增强和目标说话人提取任务。基于 MossFormer2 的 48kHz 语音增强模型在有效抑制噪声的同时,大幅降低了语音失真。
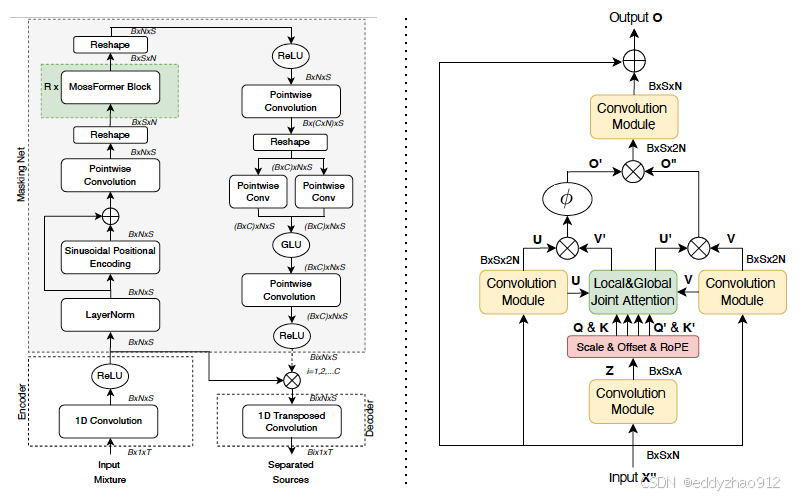
我们致力于将这些先进模型和算法通过 ClearerVoice-Studio 平台开放给更多用户,希望为开发者、研究者和企业提供强大的语音处理工具,助力创新应用落地。
成果展示
感谢广大用户对我们平台的支持!
基于 FRCRN 语音降噪模型 和 MossFormer 语音分离模型,我们在 ModelScope.cn 上的累计使用量已突破 500 万次。这是对我们算法能力的高度认可,更是对开源模式的肯定!
为此,我们将持续优化平台功能,扩大开源影响力,与更多用户共同推动语音技术的发展。

🎧 体验 ClearerVoice-Studio 的卓越性能
想亲身体验我们算法的强大吗?您只需点击以下链接即可轻松上手:
🔗 ClearerVoice-Studio on HuggingFace
如何操作:
-
准备一段包含噪声的语音文件或者多人说话的音频/视频;
-
上传至指定页面;
-
一键处理后,您可以在线试听/试看,也可以下载处理结果到本地。
清晰的音质、卓越的降噪效果,就在指尖触达!
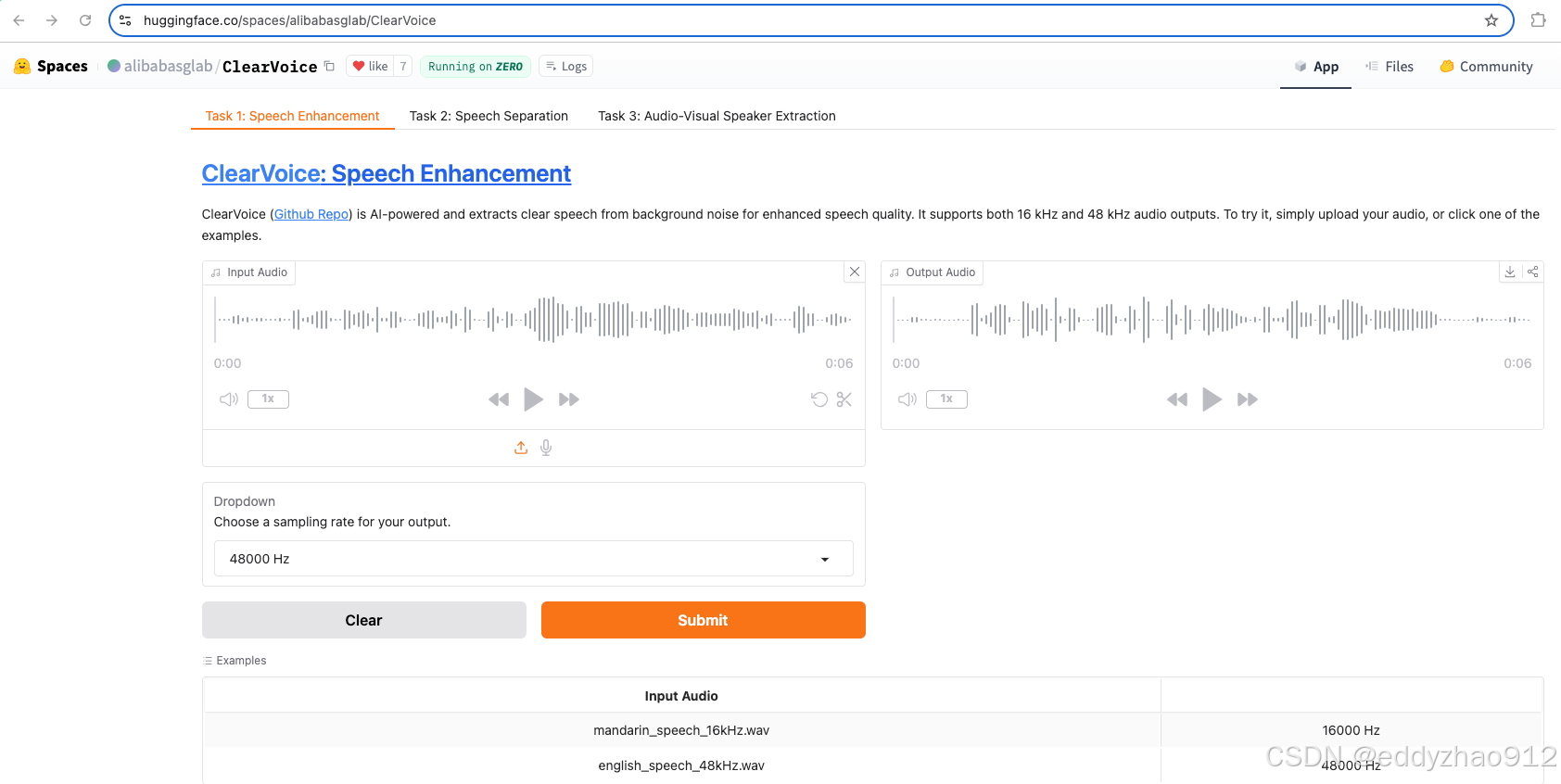
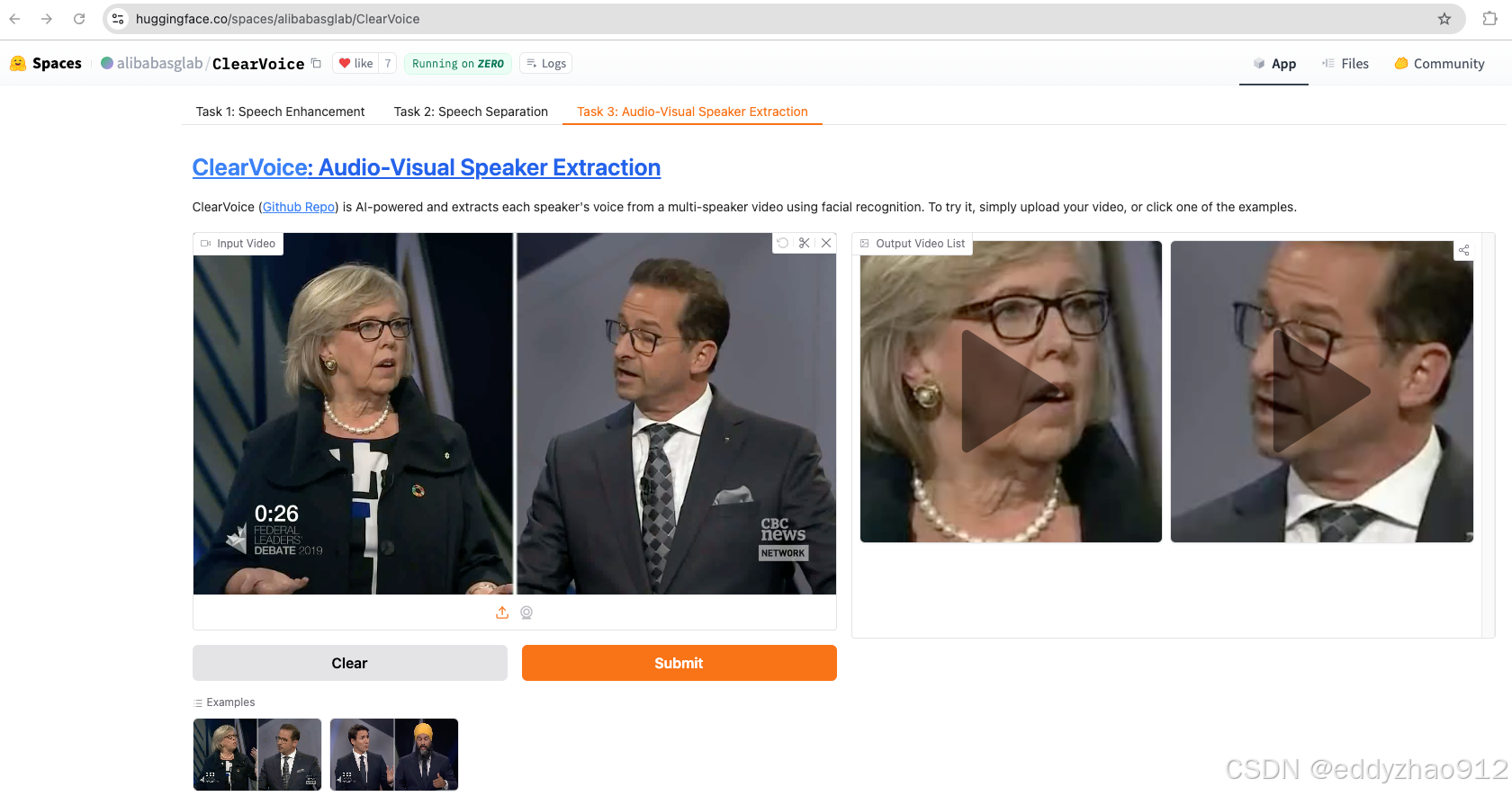
更多模型评测结果及技术细节,请访问 ClearerVoice-Studio 页面了解详情。
🤝 加入 ClearerVoice-Studio 开源社区
ClearerVoice-Studio 是一个由社区驱动的开源平台,我们深信协作的力量。您的每一份支持,都将推动语音处理技术更进一步!
🔗 支持我们的方式
-
为 GitHub 仓库加星⭐,并分享给更多感兴趣的朋友;
-
贡献代码,一起完善平台功能;
-
提供反馈和使用案例,帮助我们不断改进;
-
加入社区讨论,共创想法和技术创新。
让我们携手突破语音处理的边界,探索更清晰、更纯净的声音世界!
感谢您的支持与信任!❤️
文献参考:
【1】Zhao, Shengkui and Ma, Bin and Watcharasupat, Karn N. and Gan, Woon-Seng, “FRCRN: Boosting Feature Representation Using Frequency Recurrence for Monaural Speech Enhancement”, ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
【2】Zhao, Shengkui and Ma, Bin, “MossFormer: Pushing the Performance Limit of Monaural Speech Separation using Gated Single-head Transformer with Convolution-augmented Joint Self-Attentions”, ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
【3】Zhao, Shengkui and Ma, Bin et al, “MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation”, ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
搜索索引:
语音超分下采样 语音超分辨率 谱减法 噪音消除 语音降噪算法代码 语音降噪 深度学习
语音降噪cnn语音降噪小波python 语音信号降噪 python 语音降噪增强 ai语音降噪 实时语音降噪 python 语音信号降噪matlab 语音信号降噪增强 语音增强模型 语音增强matlab代码 语音增强算法 语音增强数据集 语音增强 python 语音增强开源项目 语音增强方法综述 matlab语音增强 语音信号增强系统设计 python 语音降噪增强 语音分离算法 语音分离方法 语音分离模型 语音分离任务 语音分离api 语音分离的挑战matlab 语音分离多说话人 语音分离多通道 语音分离语音实时分离 语音处理 语音分离 语音去噪 变频 回旋 回声 含SNR 滤波器 谱减法

















 1822
1822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









