







前言
我们在线性回归中很好地理解了均方误差的公式。理解了要进行全局误差优化(在线性回归中通常是梯度下降)首先得有一个损失函数来计算单个数据的损失。在多分类问题解决方法Softmax回归模型中,通常使用的损失函数就是交叉熵损失函数,在讲交叉熵损失函数之前,我们先理解了Softmax函数是如何将数据转换为概率的。
概念
交叉熵误差计算的是模型预测的概率分布与实际概率分布之间的差异。对于一个多分类问题,假设模型的输出经过 Softmax 函数转换成了概率分布
P
P
P,并且我们有真实的标签概率分布
Q
Q
Q。交叉熵损失函数如下:
H
(
Q
,
P
)
=
−
∑
c
=
1
C
Q
c
l
o
g
(
P
c
)
H(Q, P) = -∑_{c=1}^{C} Q_c log(P_c)
H(Q,P)=−c=1∑CQclog(Pc)
其中:
- C C C是类别的总数。
- Q c Q_c Qc 是真实标签的概率分布,通常是独热编码(one-hot encoded)向量,如[1, 0, 0]即表示当前类别为1或0的向量(有且只有以列为1,表示当前类别的概率为100%)。
- P c P_c Pc 是模型预测的概率分布,通过如 Softmax 函数的输出获得。
- 求和 ∑ ∑ ∑是对所有类别 c c c进行累加。
- 使用负号是因为由于
P
c
P_c
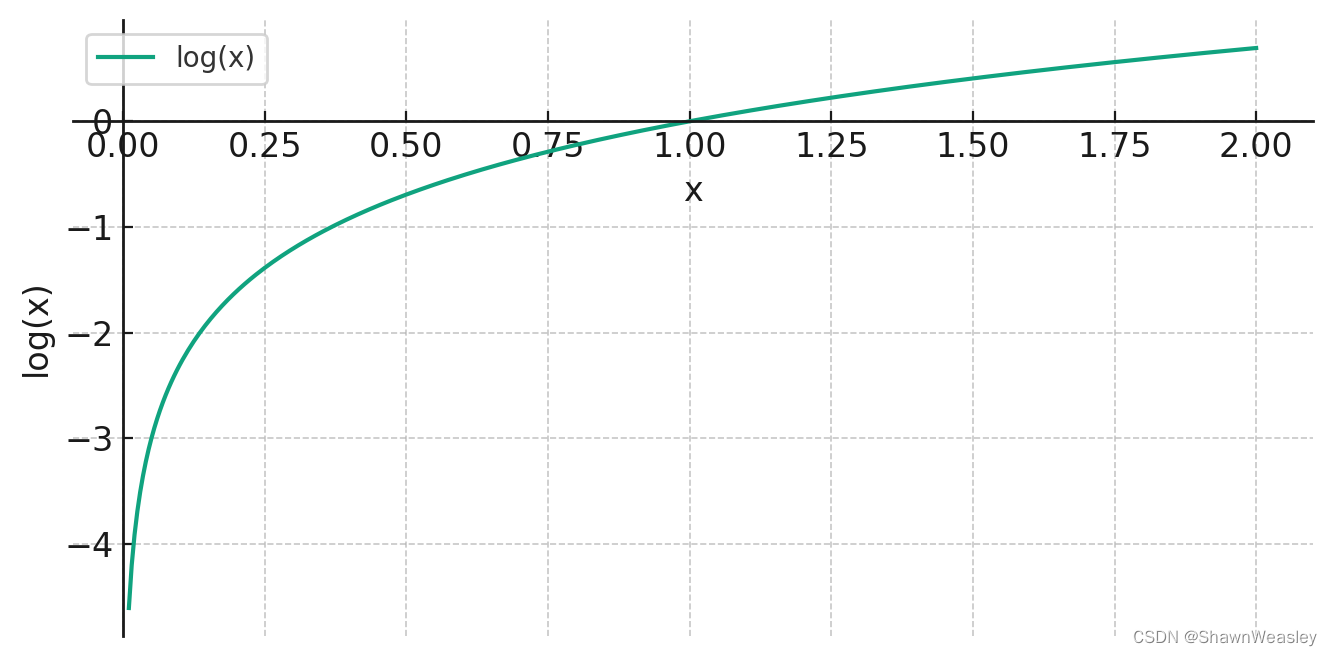
Pc是概率值,所以它的范围在0到1之间,对数值将是负数。如下图为log的曲线,当x接近 1 时,
l
o
g
(
x
)
log(x)
log(x)接近 0,表示如果预测概率与实际发生概率相匹配,损失会变小。这种特性使得
l
o
g
log
log函数非常适合于衡量预测概率与实际概率之间的差异。而
−
l
o
g
(
P
c
)
-log(P_c)
−log(Pc)就可以将负数变正,最外面的负号是提取出来的。
转换为 J ( θ ) J(θ) J(θ)表示就是:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
∑
c
=
1
C
y
c
(
i
)
log
(
h
θ
(
x
(
i
)
)
c
)
J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} \sum_{c=1}^{C} y_c^{(i)} \log(h_{\theta}(x^{(i)})_c)
J(θ)=−m1i=1∑mc=1∑Cyc(i)log(hθ(x(i))c)
其中:
- J ( θ ) J(\theta) J(θ)是基于模型参数 ( \theta ) 的损失函数。
- m m m是样本的总数。
- C C C是类别的总数。
- y c ( i ) y_c^{(i)} yc(i)是一个指示器(indicator)变量,表示如果样本 i i i属于类 c c c,则 y c ( i ) = 1 y_c^{(i)} = 1 yc(i)=1,否则 y c ( i ) = 0 y_c^{(i)} = 0 yc(i)=0。
- h θ ( x ( i ) ) c h_{\theta}(x^{(i)})_c hθ(x(i))c是模型对于样本 i i i属于类别 c c c的预测概率。
对于二分类问题,这个公式可以简化为:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} [ y^{(i)} \log(h_{\theta}(x^{(i)})) + (1 - y^{(i)}) \log(1 - h_{\theta}(x^{(i)})) ] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
这里:
- y ( i ) y^{(i)} y(i)是样本 i i i的实际标签(0 或 1)。
- h θ ( x ( i ) ) h_{\theta}(x^{(i)}) hθ(x(i))是模型预测样本 i i i为 1 的概率。
交叉熵损失现在已经被应用于非常多的方面,不仅仅是多分类问题,能够很好地衡量两个概率分布之间差异的度量。交叉熵损失函数比均方误差更不容易陷入梯度消失的问题,所以在机器学习框架中(如TensorFlow或PyTorch),交叉熵损失函数通常已经作为内置函数实现。
在代码中Softmax回归代码如下,使用鸢尾花数据集可以获得100%正确率的成绩,相比逻辑回归OvR策略的结果要好很多:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建Softmax回归模型
softmax_reg = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=200)
# 训练模型
softmax_reg.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = softmax_reg.predict(X_test)
# 评估模型
report = classification_report(y_test, y_pred)
print(report)
分类结果:
| 类别 | 精度 (Precision) | 召回率 (Recall) | F1得分 | 支持 (Support) |
|---|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 | 19 |
| 1 | 1.00 | 1.00 | 1.00 | 13 |
| 2 | 1.00 | 1.00 | 1.00 | 13 |
| 总计 | 1.00 | 1.00 | 1.00 | 45 |














 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









